二叉搜索树
二叉搜索树(BST)是一种基于节点的有序二叉树数据结构,节点有一个值和两个子节点(一个二叉树最多有两个子节点)左右相连。节点有一个值和两个子节点(一棵二叉树最多两个子节点)左右相连。除根节点外,所有节点只能由其父节点引用。一个 BST 具有以下属性。
- 左边子树上的所有节点都比根节点小。
- 右侧子树中的所有节点都比根节点大。
- 左子树和右子树也必须是二叉搜索树。

左边的树满足 BST 的所有属性。另一方面,右侧的树似乎是一个 BST,因为左侧子树的所有节点都较小,而右侧子树的节点较大。但左边子树上的节点
1不符合 BST 属性,因为它比节点4小,但不比根节点3大。因此,它不是一个 BST。
由于它是一个有序的数据结构,所以输入的元素总是以排序的方式组织的。我们可以使用顺序内遍历来检索存储在 BST 中的数据,以排序的方式。它之所以得名是因为,就像二叉搜索一样,它可以用来搜索 O(logn) 中的数据。
二叉搜索树的搜索操作
我们知道,在 BST 中,根部右侧的元素都比较大,因此如果我们要搜索的目标元素比根部小,那么整个右侧子树可以忽略。同理,如果元素比根大,那么左边的子树也可以忽略。我们以类似的方式移动,直到用尽树或找到目标元素作为子树的根。如果 BST 是平衡的(如果对于所有节点来说,左子树和右子树的高度之差小于等于 1,则称为平衡树),那么 BST 内部的搜索执行类似于二叉搜索,因为两个子树都有大约一半的元素,在每次迭代时都会被忽略,但如果是一棵不平衡的树,所有的节点可能存在于同一侧,搜索可能执行类似于线性搜索。
二叉搜索树搜索算法
假设 root 是 BST 的根节点,X 是被搜索的目标元素。
-
如果
root==NULL,返回NULL。 -
如果
X==root->data, 返回root; -
如果
X<root->data,返回search(root->left)。 -
如果
X>root->data,返回search(root->right)。
二叉搜索树搜索说明

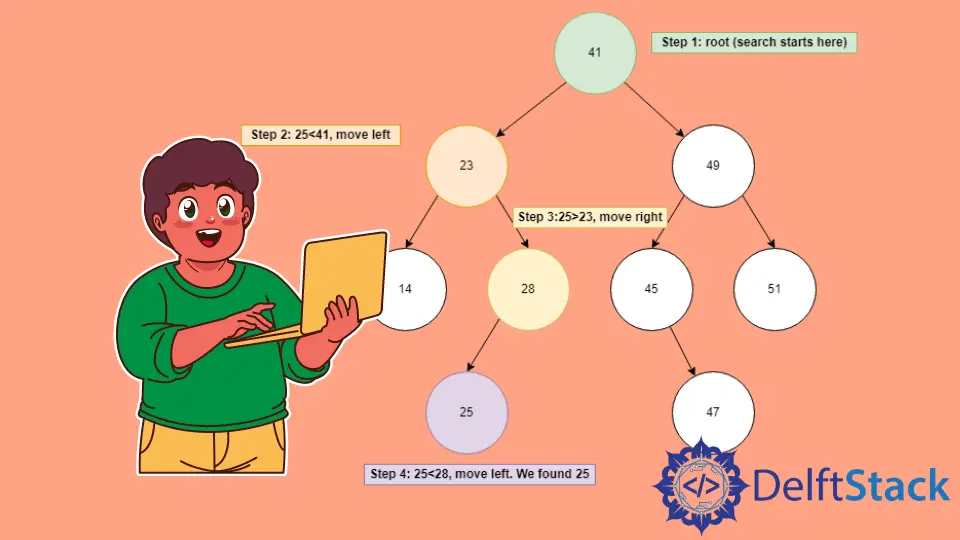
假设我们有上面的 BST,我们想找到元素 X=25。
-
将根元素与
X进行比较,发现41>25,因此丢弃右半部分,转移到左子树。 -
左侧子树的根
23<25,因此丢弃其左侧子树,移到右侧。 -
新的根
28<25,因此向左移动,找到我们的元素X等于25并返回节点。
二叉搜索树中插入元素
在 BST 中插入元素的算法与在 BST 中搜索元素的算法非常相似,因为在插入元素之前,我们必须找到它的正确位置,插入和搜索功能的唯一区别是,在搜索的情况下,我们返回包含目标值的节点,而在插入的情况下,我们在节点的适当位置创建新节点。
BST 插入算法
假设 root 是 BST 的根节点,X 是我们要插入的元素。
-
如果
root==NULL,返回一个新形成的节点,data=X。 -
if (
X<root->data),root->left=insert(root->left, X); -
else if (
X>root->data) ,root->right=insert(root->right, X)。 -
返回一个指向原
root的指针。
BST 插入说明

-
首先,我们通过创建一个
root节点来初始化 BST,并在其中插入5。 -
3比5小,所以它被插入5的左边。 -
4比5小,但比3大,所以插入3的右边,但插入4的左边。 -
2是当前树中最小的元素,所以它被插入到最左边的位置。 -
1是当前树中最小的元素,所以它被插入到最左边的位置。 -
6是当前树中最大的元素,所以它被插入到最右边的位置。
这就是我们在 BST 中插入元素的方法。
BST 搜索和插入的实现
#include <iostream>
using namespace std;
class Node {
public:
int key;
Node *left, *right;
};
Node *newNode(int item) {
Node *temp = (Node *)malloc(sizeof(Node));
temp->key = item;
temp->left = temp->right = NULL;
return temp;
}
void inorder(Node *root) {
if (root != NULL) {
inorder(root->left);
cout << root->key << " ";
inorder(root->right);
}
}
Node *insert(Node *root, int key) {
if (root == NULL) return newNode(key);
if (key < root->key)
root->left = insert(root->left, key);
else
root->right = insert(root->right, key);
return root;
}
Node *search(Node *root, int key) {
if (root == NULL || root->key == key) return root;
if (root->key < key) return search(root->right, key);
return search(root->left, key);
}
int main() {
Node *root = NULL;
root = insert(root, 5);
root = insert(root, 3);
root = insert(root, 8);
root = insert(root, 6);
root = insert(root, 4);
root = insert(root, 2);
root = insert(root, 1);
root = insert(root, 7);
cout << search(root, 5)->key << endl;
}
BST 插入和搜索算法的复杂度
时间复杂度
- 平均情况
平均而言,在 BST 中插入一个节点或搜索一个元素的时间复杂度与二元搜索树的高度相当。平均来说,一个 BST 的高度是 O(logn)。当形成的 BST 是一个平衡的 BST 时,就会出现这种情况。因此,时间复杂度是 [Big Theta]:O(logn)。
- 最佳情况
最好的情况是,该树是一个平衡的 BST。插入和搜索的最佳情况时间复杂度为 O(logn)。它与平均情况下的时间复杂度相同。
- 最坏情况
在最坏的情况下,我们可能要从根节点遍历到最深的叶子节点,即树的整个高度 h。如果树是不平衡的,即它是倾斜的,树的高度可能会变成 n,因此插入和搜索操作的最坏情况下的时间复杂度是 O(n)。
空间复杂度
由于递归调用所需的空间,插入和搜索操作的空间复杂度都是 O(n)。

Harshit Jindal has done his Bachelors in Computer Science Engineering(2021) from DTU. He has always been a problem solver and now turned that into his profession. Currently working at M365 Cloud Security team(Torus) on Cloud Security Services and Datacenter Buildout Automation.
LinkedIn