在 Python 中执行逻辑回归
Preet Sanghavi
2024年2月15日
Python
Python Math
以下教程演示了如何在 Python 上执行逻辑回归。
让我们下载一个示例数据集以开始使用。我们将使用一个包含用户性别、年龄和薪水信息的用户数据集,并预测用户最终是否会购买该产品。
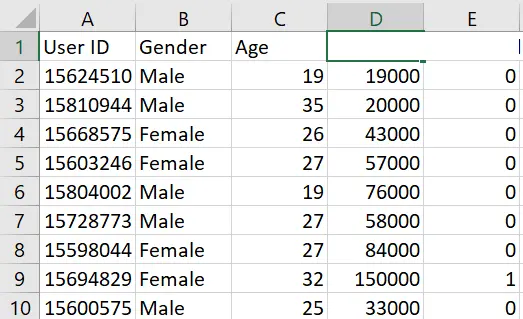
看看我们的数据集。
我们现在将通过导入相关的库开始创建我们的模型,例如 pandas、numpy 和 matplotlib。
在 Python 中执行逻辑回归
导入相关库:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
让我们使用 pandas 导入我们的数据集。
读取数据集:
dataset = pd.read_csv("log_data.csv")
我们现在将从我们的数据集中选择年龄和估计工资特征来训练我们的模型来预测用户是否购买产品。在这里,gender 和 user id 不会在预测中发挥重要作用;我们在训练过程中忽略了它们。
x = dataset.iloc[:, [2, 3]].values
y = dataset.iloc[:, 4].values
让我们将数据集拆分为训练和测试数据。我们将它们分成 75% 用于训练模型,其余 25% 用于测试模型的性能。
我们使用 sklearn 库中的 train_test_split 函数来执行此操作。
from sklearn.model_selection import train_test_split
xtrain, xtest, ytrain, ytest = train_test_split(x, y, test_size=0.25, random_state=0)
我们执行特征缩放过程,因为 Age 和 Salary 特征位于不同的范围内。这是必不可少的,因为一个特征可以在避免训练过程的同时支配另一个特征。
from sklearn.preprocessing import StandardScaler
sc_x = StandardScaler()
xtrain = sc_x.fit_transform(xtrain)
xtest = sc_x.transform(xtest)
这两个特征都在 -1 到 1 的范围内,这将确保这两个特征对决策(即预测过程)做出同等贡献。让我们来看看更新的功能。
print(xtrain[0:10, :])
[[ 0.58164944 -0.88670699]
[-0.60673761 1.46173768]
[-0.01254409 -0.5677824 ]
[-0.60673761 1.89663484]
[ 1.37390747 -1.40858358]
[ 1.47293972 0.99784738]
[ 0.08648817 -0.79972756]
[-0.01254409 -0.24885782]
[-0.21060859 -0.5677824 ]
[-0.21060859 -0.19087153]]
最后让我们训练我们的模型;在我们的例子中,我们将使用从 sklearn 库导入的逻辑回归模型。
from sklearn.linear_model import LogisticRegression
classifier1 = LogisticRegression(random_state=0)
classifier1.fit(xtrain, ytrain)
由于我们现在已经训练了我们的模型,让我们对我们的测试数据进行预测以评估我们的模型。
y_pred = classifier1.predict(xtest)
现在让我们根据我们的测试数据和我们在上一个过程中获得的预测创建一个混淆矩阵。
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(ytest, y_pred)
print("Confusion Matrix : \n", cm)
Confusion Matrix :
[[65 3]
[ 8 24]]
让我们使用 sklearn 库计算模型的准确性。
from sklearn.metrics import accuracy_score
print("Accuracy score : ", accuracy_score(ytest, y_pred))
Accuracy score : 0.89
我们的模型获得了令人满意的准确度得分 0.89,这表明我们的模型可以很好地预测用户是否会购买产品。
因此,我们可以通过上述方法使用 Python 成功执行逻辑回归。
Enjoying our tutorials? Subscribe to DelftStack on YouTube to support us in creating more high-quality video guides. Subscribe
作者: Preet Sanghavi
