Pandas 和 Seaborn 的 KDE 绘图可视化
- 在 Python 中使用 Normal KDE Plot 和 Seaborn 进行数据可视化
- 在 Python 中使用 Pandas 和 Seaborn 绘制一维 KDE 绘图
- 在 Python 中使用 Pandas 和 Seaborn 绘制二维或二元 KDE 图
- 结论
KDE 是 Kernel Density Estimate,用于可视化连续和非参数数据变量的概率密度。当你想要可视化多个分布时,KDE 函数会生成一个更简洁、更易于解释的图。
使用 KDE,我们可以使用单个图表来可视化多个数据样本,这是一种更有效的数据可视化方法。
Seaborn 是一个类似于 matplotlib 的 python 库。Seaborn 可以与 pandas 和 numpy 集成以进行数据表示。
数据科学家使用这个库来创建信息丰富且美观的统计图表和图形。使用这些演示文稿,你可以了解不同模块内的清晰概念和信息流。
我们可以使用 KDE 函数、Seaborn 和 Pandas 绘制单变量和双变量图。
我们将学习使用 pandas 和 seaborn 进行 KDE 绘图可视化。本文将使用 mtcars 数据集的几个样本来展示 KDE 绘图可视化。
在开始详细介绍之前,你需要使用 pip 命令安装或添加 seaborn 和 sklearn 库。
pip install seaborn
pip install sklearn
在 Python 中使用 Normal KDE Plot 和 Seaborn 进行数据可视化
我们可以使用带有 Seaborn 库的普通 KDE 绘图函数绘制数据。
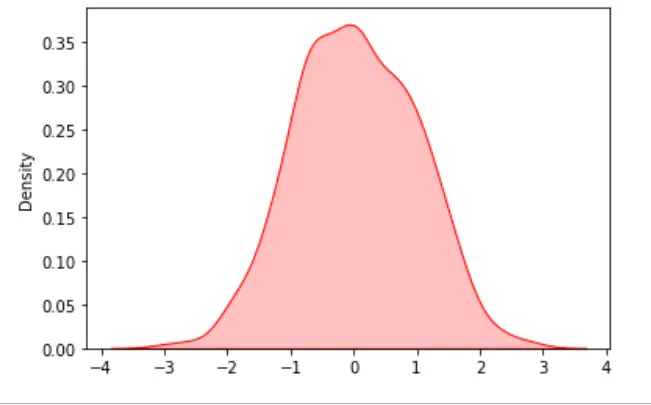
在下面的示例中,我们使用随机库创建了 1000 个数据样本,然后将它们排列在 numpy 的数组中,因为 Seaborn 库仅适用于 numpy 和 Pandas dataframes。
示例代码:
import seaborn as sn
import matplotlib.pyplot as plt
import numpy as np
data = np.random.randn(1000)
# KDE Plot with seaborn
res = sn.kdeplot(data, color="red", shade="True")
plt.show()
输出:
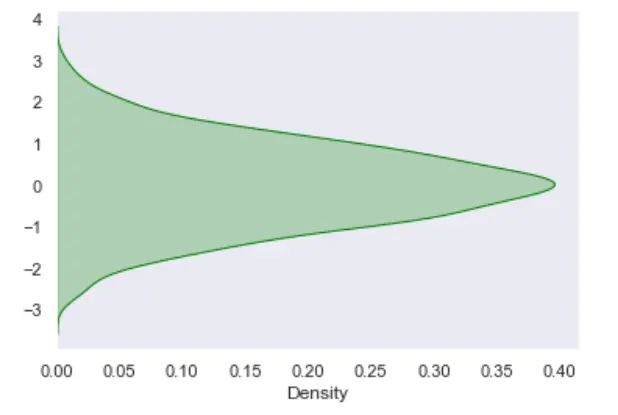
我们还可以使用 KDE 和 Seaborn 库垂直可视化上述数据样本或还原上述图。我们使用 plot 属性 vertical=True 来还原上面的图。
示例代码:
import seaborn as sn
import matplotlib.pyplot as plt
import numpy as np
data = np.random.randn(1000)
# KDE Plot with seaborn
res = sn.kdeplot(data, color="green", vertical=True, shade="True")
plt.show()
输出:
在 Python 中使用 Pandas 和 Seaborn 绘制一维 KDE 绘图
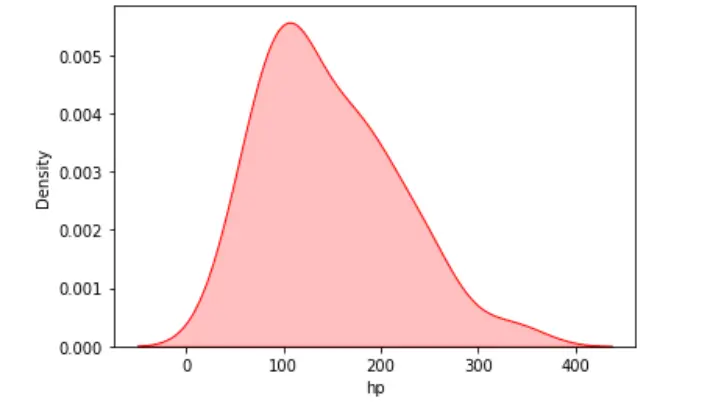
我们可以使用 KDE 图来可视化单个目标或连续属性的概率分布。在以下示例中,我们读取了 mtcars 数据集的 CSV 文件。
我们的数据集中有 350 多个条目,我们将沿 x 轴可视化单变量分布。
示例代码:
import seaborn as sn
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# read CSV file of dataset using pandas
dataset = pd.read_csv(r"C:\\Users\\DELL\\OneDrive\\Desktop\\samplecardataset.csv")
# kde plot using seaborn
sn.kdeplot(data=dataset, x="hp", shade=True, color="red")
plt.show()
输出:
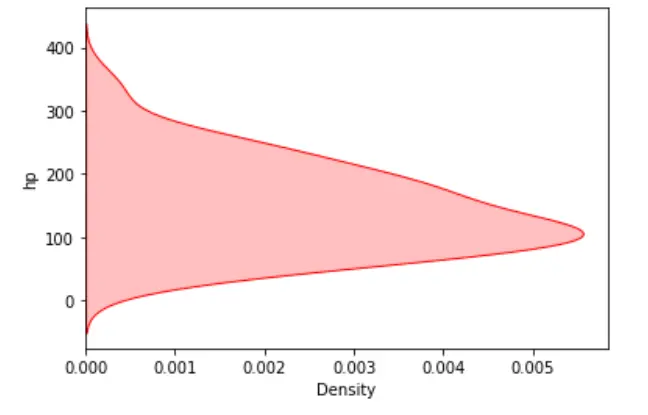
你还可以通过沿 y 轴可视化数据变量来翻转绘图。
示例代码:
import seaborn as sn
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# Read CSV file using pandas
dataset = pd.read_csv(r"C:\\Users\\DELL\\OneDrive\\Desktop\\samplecardataset.csv")
# KDE plotting using seaborn
sn.kdeplot(data=dataset, y="hp", shade=True, color="red")
plt.show()
输出:
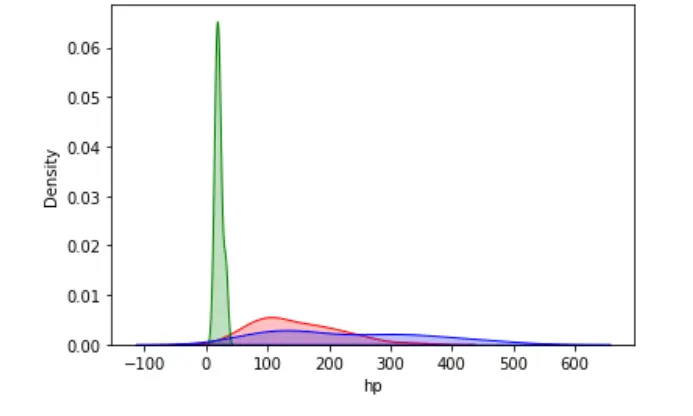
我们可以在单个图中可视化多个目标值的概率分布。
示例代码:
import seaborn as sn
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# Read CSV file using pandas
dataset = pd.read_csv(r"C:\\Users\\DELL\\OneDrive\\Desktop\\samplecardataset.csv")
# KDE plotting using seaborn
sn.kdeplot(data=dataset, x="hp", shade=True, color="red")
sn.kdeplot(data=dataset, x="mpg", shade=True, color="green")
sn.kdeplot(data=dataset, x="disp", shade=True, color="blue")
plt.show()
输出:
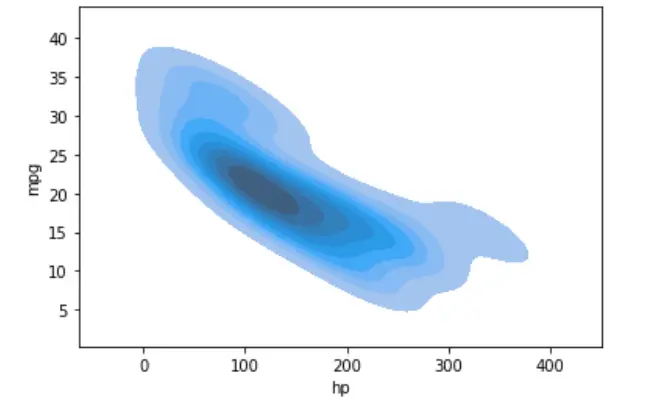
在 Python 中使用 Pandas 和 Seaborn 绘制二维或二元 KDE 图
我们可以使用 seaborn 和 pandas 库在二维或双变量 KDE 图中可视化数据。
通过这种方式,我们可以可视化给定样本针对多个连续属性的概率分布。我们沿 x 和 y 轴可视化数据。
示例代码:
import seaborn as sn
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# Read CSV file using pandas
dataset = pd.read_csv(r"C:\\Users\\DELL\\OneDrive\\Desktop\\samplecardataset.csv")
# KDE plotting using seaborn
sn.kdeplot(data=dataset, shade=True, x="hp", y="mpg")
plt.show()
输出:
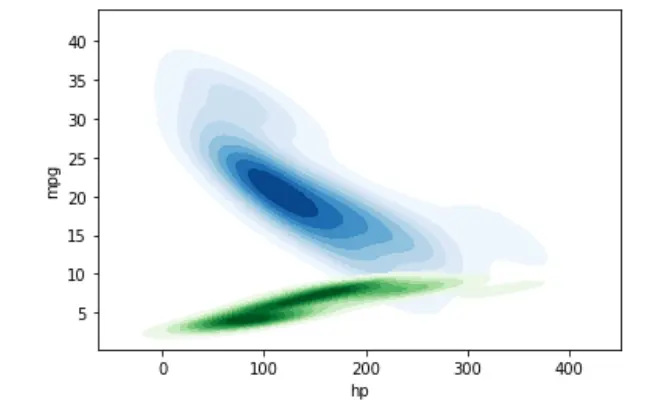
同样,我们可以使用单个 KDE 图绘制多个样本的概率分布。
示例代码:
import seaborn as sn
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# Read CSV file using pandas
dataset = pd.read_csv(r"C:\\Users\\DELL\\OneDrive\\Desktop\\samplecardataset.csv")
# KDE plotting using seaborn
sn.kdeplot(data=dataset, shade=True, x="hp", y="mpg", cmap="Blues")
sn.kdeplot(data=dataset, shade=True, x="hp", y="cyl", cmap="Greens")
plt.show()
输出:
结论
我们在本教程中演示了使用 Pandas 和 Seaborn 库的 KDE 绘图可视化。我们已经看到如何在一维 KDE 图中可视化单个和多个样本的概率分布。
我们讨论了如何使用带有 Seaborn 和 Pandas 的 KDE 图来可视化二维数据。