Python pandas.pivot_table() 函数
Minahil Noor
2023年1月30日
Pandas
Pandas Core
-
pandas.pivot_table()的语法 -
示例代码:
pandas.pivot_table() -
示例代码:
pandas.pivot_table()指定多个聚合函数 -
示例代码:
pandas.pivot_table()使用margins参数
Python Pandaspandas.pivot_table() 函数避免了 DataFrame 的数据重复。它对数据进行汇总,并对数据应用不同的聚合函数。
pandas.pivot_table() 的语法
pandas.pivot_table(
data,
values=None,
index=None,
columns=None,
aggfunc="mean",
fill_value=None,
margins=False,
dropna=True,
margins_name="All",
observed=False,
)
参数
这个函数有几个参数。所有参数的默认值如上所述。
data |
这是 DataFrame,我们要从中删除重复的数据。 |
values |
它代表要汇总的列 |
index |
它是一个列、grouper、数组或列表。它代表我们想要作为索引的数据列,即行。 |
columns |
它是一个列、grouper、数组或列表。它代表了我们希望在输出数据透视表中作为列的数据列。 |
aggfunc |
它是一个函数、函数列表或字典。它代表将应用于数据的聚合函数。如果传递的是聚合函数的列表,那么在结果表中,每个聚合函数将有一列,列名在顶部。 |
fill_value |
它是一个标量。它表示将取代输出表中缺失值的数值。 |
margins |
这是一个布尔值。它代表了在取了各自行和列的和之后生成的行和列。 |
dropna |
它是一个布尔值。它从输出表中删除值为 NaN 的列。 |
margins_name |
它是一个 “字符串”。它表示如果 margins 值为 True 时生成的行和列的名称。 |
observed |
它是一个布尔值。如果任何分组是分类的,那么这个参数就适用。如果为 True,则显示分类分组的观察值。如果是 False,则显示分类分组的所有值。 |
返回值
它返回汇总后的 DataFrame。
示例代码:pandas.pivot_table()
让我们通过实现这个函数来深入了解它。
import pandas as pd
dataframe = pd.DataFrame({
"Name":
["Olivia",
"Olivia",
"Olivia",
"Olivia",
"Meghan",
"Meghan",
"Meghan",
"Meghan"],
"Date":
["03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019"],
"Science Marks":
[10,
2,
4,
6,
8,
9,
1,
10]
})
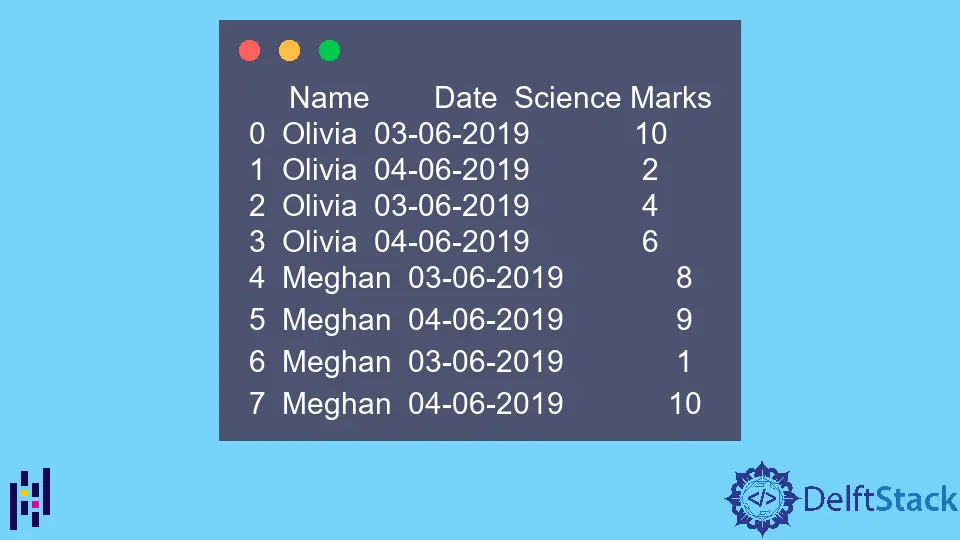
print(dataframe)
示例 DataFrame 的是:
Name Date Science Marks
0 Olivia 03-06-2019 10
1 Olivia 04-06-2019 2
2 Olivia 03-06-2019 4
3 Olivia 04-06-2019 6
4 Meghan 03-06-2019 8
5 Meghan 04-06-2019 9
6 Meghan 03-06-2019 1
7 Meghan 04-06-2019 10
请注意,上述数据在一列中多次包含相同的值。这个 pivot_table 函数将汇总这些数据。
import pandas as pd
dataframe = pd.DataFrame(
{
"Name": [
"Olivia",
"Olivia",
"Olivia",
"Olivia",
"Meghan",
"Meghan",
"Meghan",
"Meghan",
],
"Date": [
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
],
"Science Marks": [10, 2, 4, 6, 8, 9, 1, 10],
}
)
pivotTable = pd.pivot_table(dataframe, index="Name", columns="Date")
print(pivotTable)
输出:
Science Marks
Date 03-06-2019 04-06-2019
Name
Meghan 4.5 9.5
Olivia 7.0 4.0
这里,我们选择了 Name 列作为索引,Date 作为列。函数已经根据默认参数生成了结果。默认的聚合函数 mean 计算了数值的平均值。
示例代码:pandas.pivot_table() 指定多个聚合函数
import pandas as pd
dataframe = pd.DataFrame(
{
"Name": [
"Olivia",
"Olivia",
"Olivia",
"Olivia",
"Meghan",
"Meghan",
"Meghan",
"Meghan",
],
"Date": [
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
],
"Science Marks": [10, 2, 4, 6, 8, 9, 1, 10],
}
)
pivotTable = pd.pivot_table(
dataframe, index="Name", columns="Date", aggfunc=["sum", "count"]
)
print(pivotTable)
输出:
sum count
Science Marks Science Marks
Date 03-06-2019 04-06-2019 03-06-2019 04-06-2019
Name
Meghan 9 19 2 2
Olivia 14 8 2 2
我们使用了两个汇总函数。这些函数的列是单独生成的。
示例代码:pandas.pivot_table() 使用 margins 参数
import pandas as pd
dataframe = pd.DataFrame(
{
"Name": [
"Olivia",
"Olivia",
"Olivia",
"Olivia",
"Meghan",
"Meghan",
"Meghan",
"Meghan",
],
"Date": [
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
],
"Science Marks": [10, 2, 4, 6, 8, 9, 1, 10],
}
)
pivotTable = pd.pivot_table(
dataframe, index="Name", columns="Date", aggfunc=["sum", "count"], margins=True
)
print(pivotTable)
输出:
sum count
Science Marks Science Marks
Date 03-06-2019 04-06-2019 All 03-06-2019 04-06-2019 All
Name
Meghan 9 19 28 2 2 4
Olivia 14 8 22 2 2 4
All 23 27 50 4 4 8
margins 参数生成了一个名为 All 的新行和一个名为 All 的新列,分别显示行和列的和。
Enjoying our tutorials? Subscribe to DelftStack on YouTube to support us in creating more high-quality video guides. Subscribe