使用 NumPy 和 Python 實現梯度下降
機器學習是當今的一種趨勢。每家公司或初創公司都在嘗試提出使用機器學習來解決現實世界問題的解決方案。為了解決這些問題,程式設計師構建了機器學習模型,這些模型是針對一些重要且有價值的資料進行訓練的。在訓練模型時,有很多策略、演算法和方法可供選擇。有些可能會起作用,有些則不會。
通常,使用 Python 來訓練這些模型。Python 支援眾多庫,可以輕鬆實現機器學習概念。其中一個概念是梯度下降。在本文中,我們將學習如何使用 Python 實現梯度下降。
梯度下降
梯度下降是一種基於凸函式的優化演算法,用於訓練機器學習模型。該演算法幫助我們找到最佳模型引數以更有效地解決問題。在針對某些資料訓練機器學習模型時,該演算法會為每次迭代調整模型引數,最終為可微函式生成全域性最小值,有時甚至是區域性最小值。
在調整模型引數時,稱為學習率的值決定了應調整值的量。如果這個值太大,學習會很快,我們最終可能會欠擬合模型。而且,如果這個值太小,學習會很慢,我們最終可能會過度擬合模型到訓練資料。因此,我們必須提出一個保持平衡的值,並最終產生一個具有良好準確性的良好機器學習模型。
使用 Python 實現梯度下降
現在我們已經完成了梯度下降的簡要理論,讓我們通過一個例子來了解如何在 NumPy 模組和 Python 程式語言的幫助下實現它。
我們將為方程 y = 0.5x + 2 訓練機器學習模型,其形式為 y = mx + c 或 y = ax + b。本質上將針對使用此方程生成的資料訓練機器學習模型。模型將分別猜測 m 和 c 或 a 和 b 的值,即斜率和截距。由於機器學習模型需要一些資料來學習和一些測試資料來測試它們的準確性,我們將使用 Python 指令碼生成相同的資料。我們將執行線性迴歸來執行此任務。
訓練輸入和測試輸入將採用以下形式;一個二維 NumPy 陣列。在此示例中,輸入是單個整數值,輸出是單個整數值。由於單個輸入可以是整數和浮點值的陣列,因此將使用以下格式來提高程式碼的可重用性或動態性。
[[1], [2], [3], [4], [5], [6], [7], ...]
訓練標籤和測試標籤將採用以下形式;一維 NumPy 陣列。
[1, 4, 9, 16, 25, 36, 49, ...]
Python 程式碼
下面是上面例子的實現。
import random
import numpy as np
import matplotlib.pyplot as plt
def linear_regression(inputs, targets, epochs, learning_rate):
"""
A utility function to run linear regression and get weights and bias
"""
costs = [] # A list to store losses at each epoch
values_count = inputs.shape[1] # Number of values within a single input
size = inputs.shape[0] # Total number of inputs
weights = np.zeros((values_count, 1)) # Weights
bias = 0 # Bias
for epoch in range(epochs):
# Calculating the predicted values
predicted = np.dot(inputs, weights) + bias
loss = predicted - targets # Calculating the individual loss for all the inputs
d_weights = np.dot(inputs.T, loss) / (2 * size) # Calculating gradient
d_bias = np.sum(loss) / (2 * size) # Calculating gradient
weights = weights - (learning_rate * d_weights) # Updating the weights
bias = bias - (learning_rate * d_bias) # Updating the bias
cost = np.sqrt(
np.sum(loss ** 2) / (2 * size)
) # Root Mean Squared Error Loss or RMSE Loss
costs.append(cost) # Storing the cost
print(
f"Iteration: {epoch + 1} | Cost/Loss: {cost} | Weight: {weights} | Bias: {bias}"
)
return weights, bias, costs
def plot_test(inputs, targets, weights, bias):
"""
A utility function to test the weights
"""
predicted = np.dot(inputs, weights) + bias
predicted = predicted.astype(int)
plt.plot(
predicted,
[i for i in range(len(predicted))],
color=np.random.random(3),
label="Predictions",
linestyle="None",
marker="x",
)
plt.plot(
targets,
[i for i in range(len(targets))],
color=np.random.random(3),
label="Targets",
linestyle="None",
marker="o",
)
plt.xlabel("Indexes")
plt.ylabel("Values")
plt.title("Predictions VS Targets")
plt.legend()
plt.show()
def rmse(inputs, targets, weights, bias):
"""
A utility function to calculate RMSE or Root Mean Squared Error
"""
predicted = np.dot(inputs, weights) + bias
mse = np.sum((predicted - targets) ** 2) / (2 * inputs.shape[0])
return np.sqrt(mse)
def generate_data(m, n, a, b):
"""
A function to generate training data, training labels, testing data, and testing inputs
"""
x, y, tx, ty = [], [], [], []
for i in range(1, m + 1):
x.append([float(i)])
y.append([float(i) * a + b])
for i in range(n):
tx.append([float(random.randint(1000, 100000))])
ty.append([tx[-1][0] * a + b])
return np.array(x), np.array(y), np.array(tx), np.array(ty)
learning_rate = 0.0001 # Learning rate
epochs = 200000 # Number of epochs
a = 0.5 # y = ax + b
b = 2.0 # y = ax + b
inputs, targets, train_inputs, train_targets = generate_data(300, 50, a, b)
weights, bias, costs = linear_regression(
inputs, targets, epochs, learning_rate
) # Linear Regression
indexes = [i for i in range(1, epochs + 1)]
plot_test(train_inputs, train_targets, weights, bias) # Testing
print(f"Weights: {[x[0] for x in weights]}")
print(f"Bias: {bias}")
print(
f"RMSE on training data: {rmse(inputs, targets, weights, bias)}"
) # RMSE on training data
print(
f"RMSE on testing data: {rmse(train_inputs, train_targets, weights, bias)}"
) # RMSE on testing data
plt.plot(indexes, costs)
plt.xlabel("Epochs")
plt.ylabel("Overall Cost/Loss")
plt.title(f"Calculated loss over {epochs} epochs")
plt.show()
Python 程式碼的簡要說明
程式碼實現了以下方法。
linear_regression(inputs, targets, epochs, learning_rate):該函式對資料執行線性迴歸,並返回每個時期的模型權重、模型偏差和中間成本或損失plot_test(inputs, targets, weights, bias):該函式接受輸入、目標、權重和偏差,並預測輸入的輸出。然後它會繪製一個圖表來顯示模型預測與實際值的接近程度。rmse(輸入、目標、權重、偏差):該函式計算並返回某些輸入、權重、偏差和目標或標籤的均方根誤差。generate_data(m, n, a, b):該函式為機器學習模型生成樣本資料,使用方程y = ax + b進行訓練。它生成訓練和測試資料。m和n分別是指生成的訓練和測試樣本的數量。
下面是上面程式碼的執行流程。
-
generate_data()方法被呼叫以生成一些樣本訓練輸入、訓練標籤、測試輸入和測試標籤。 -
一些常量,比如學習率和 epochs 的數量,被初始化。
-
linear_regression()方法被呼叫以對生成的訓練資料執行線性迴歸,並儲存在每個時期找到的權重、偏差和成本。 -
使用生成的測試資料測試模型權重和偏差,並繪製一個圖,顯示預測與真實值的接近程度。
-
計算並列印訓練和測試資料的 ##### RMSE 損失。
-
使用
Matplotlib模組(Python 圖形繪製庫)繪製每個時期的成本。
輸出
Python 程式碼會將每個 epoch 或迭代的模型訓練狀態輸出到控制檯。如下所示。
...
Iteration: 199987 | Cost/Loss: 0.05856315870190882 | Weight: [[0.5008289]] | Bias: 1.8339454694938624
Iteration: 199988 | Cost/Loss: 0.05856243033468181 | Weight: [[0.50082889]] | Bias: 1.8339475347628937
Iteration: 199989 | Cost/Loss: 0.05856170197651294 | Weight: [[0.50082888]] | Bias: 1.8339496000062387
Iteration: 199990 | Cost/Loss: 0.058560973627402625 | Weight: [[0.50082887]] | Bias: 1.8339516652238976
Iteration: 199991 | Cost/Loss: 0.05856024528735169 | Weight: [[0.50082886]] | Bias: 1.8339537304158708
Iteration: 199992 | Cost/Loss: 0.05855951695635694 | Weight: [[0.50082885]] | Bias: 1.8339557955821586
Iteration: 199993 | Cost/Loss: 0.05855878863442534 | Weight: [[0.50082884]] | Bias: 1.8339578607227613
Iteration: 199994 | Cost/Loss: 0.05855806032154768 | Weight: [[0.50082883]] | Bias: 1.8339599258376793
...
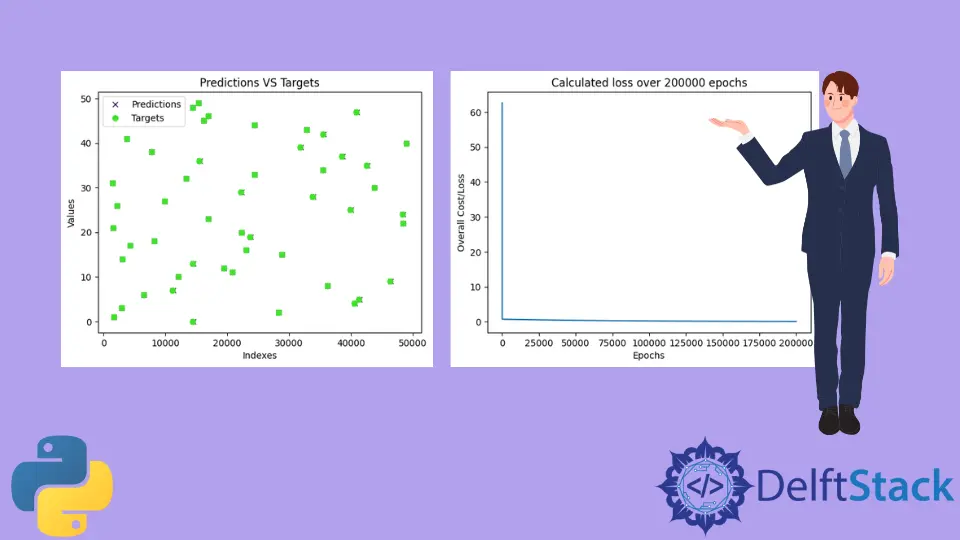
訓練模型後,程式將測試模型並繪製包含模型預測值和真實值的圖。訓練的圖將類似於下圖所示。請注意,由於測試資料是使用 random 模組生成的,隨機值將即時生成,因此,下面顯示的圖表很可能與你的不同。

正如我們所看到的,預測幾乎與所有真實值重疊(預測由 x 表示,目標由 o 表示)。這意味著該模型幾乎成功地預測了 a 和 b 或 m 和 c 的值。
接下來,程式列印在訓練模型時發現的所有損失。

正如我們所看到的,損失立即從 60 左右下降到 0 附近,並在接下來的時期繼續保持在附近。
最後,列印訓練和測試資料的 RMSE 損失,以及 a 和 b 的預測值或模型引數。
Weights: [0.5008287639956263]
Bias: 1.8339723159878247
RMSE on training data: 0.05855296238504223
RMSE on testing data: 30.609530314187527
我們在這個例子中使用的方程是 y = 0.5x + 2,其中 a = 0.5 和 b = 2。而且,該模型預測了 a = 0.50082 和 b = 1.83397,它們非常接近真實值。這就是為什麼我們的預測與真實目標重疊的原因。
在本例中,我們將 epoch 數設定為 200000,將學習率設定為 0.0001。幸運的是,這只是一組給我們帶來非常好的、近乎完美的結果的配置。我強烈建議本文的讀者嘗試使用這些值,看看他們是否可以提出一些可以產生更好結果的值。

Vaibhav is an artificial intelligence and cloud computing stan. He likes to build end-to-end full-stack web and mobile applications. Besides computer science and technology, he loves playing cricket and badminton, going on bike rides, and doodling.