Pandas 和 Seaborn 的 KDE 繪圖視覺化
- 在 Python 中使用 Normal KDE Plot 和 Seaborn 進行資料視覺化
- 在 Python 中使用 Pandas 和 Seaborn 繪製一維 KDE 繪圖
- 在 Python 中使用 Pandas 和 Seaborn 繪製二維或二元 KDE 圖
- まとめ
KDE 是 Kernel Density Estimate,用於視覺化連續和非引數資料變數的概率密度。當你想要視覺化多個分佈時,KDE 函式會生成一個更簡潔、更易於解釋的圖。
使用 KDE,我們可以使用單個圖表來視覺化多個資料樣本,這是一種更有效的資料視覺化方法。
Seaborn 是一個類似於 matplotlib 的 python 庫。Seaborn 可以與 pandas 和 numpy 整合以進行資料表示。
資料科學家使用這個庫來建立資訊豐富且美觀的統計圖表和圖形。使用這些簡報,你可以瞭解不同模組內的清晰概念和資訊流。
我們可以使用 KDE 函式、Seaborn 和 Pandas 繪製單變數和雙變數圖。
我們將學習使用 pandas 和 seaborn 進行 KDE 繪圖視覺化。本文將使用 mtcars 資料集的幾個樣本來展示 KDE 繪圖視覺化。
在開始詳細介紹之前,你需要使用 pip 命令安裝或新增 seaborn 和 sklearn 庫。
pip install seaborn
pip install sklearn
在 Python 中使用 Normal KDE Plot 和 Seaborn 進行資料視覺化
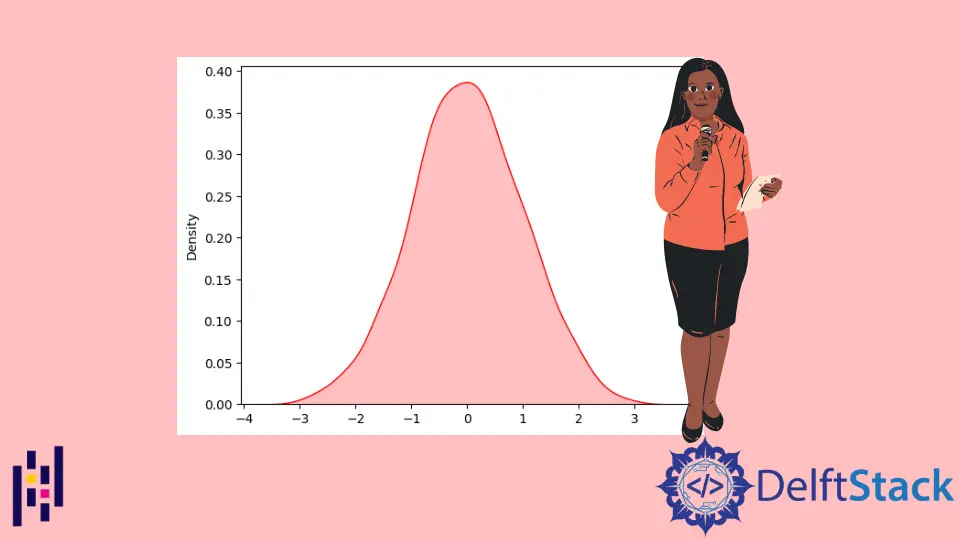
我們可以使用帶有 Seaborn 庫的普通 KDE 繪圖函式繪製資料。
在下面的示例中,我們使用隨機庫建立了 1000 個資料樣本,然後將它們排列在 numpy 的陣列中,因為 Seaborn 庫僅適用於 numpy 和 Pandas dataframes。
示例程式碼:
import seaborn as sn
import matplotlib.pyplot as plt
import numpy as np
data = np.random.randn(1000)
# KDE Plot with seaborn
res = sn.kdeplot(data, color="red", shade="True")
plt.show()
輸出:
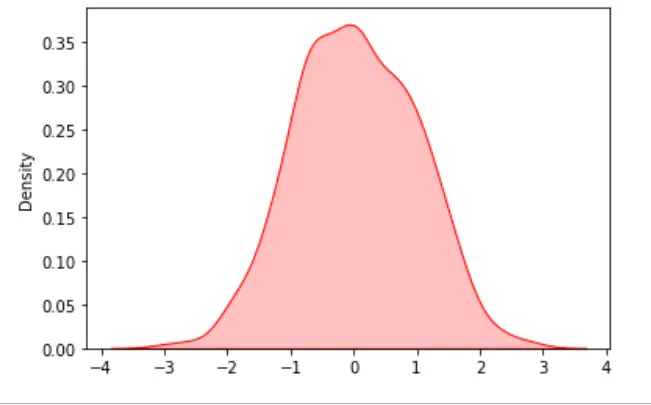
我們還可以使用 KDE 和 Seaborn 庫垂直視覺化上述資料樣本或還原上述圖。我們使用 plot 屬性 vertical=True 來還原上面的圖。
示例程式碼:
import seaborn as sn
import matplotlib.pyplot as plt
import numpy as np
data = np.random.randn(1000)
# KDE Plot with seaborn
res = sn.kdeplot(data, color="green", vertical=True, shade="True")
plt.show()
輸出:
在 Python 中使用 Pandas 和 Seaborn 繪製一維 KDE 繪圖
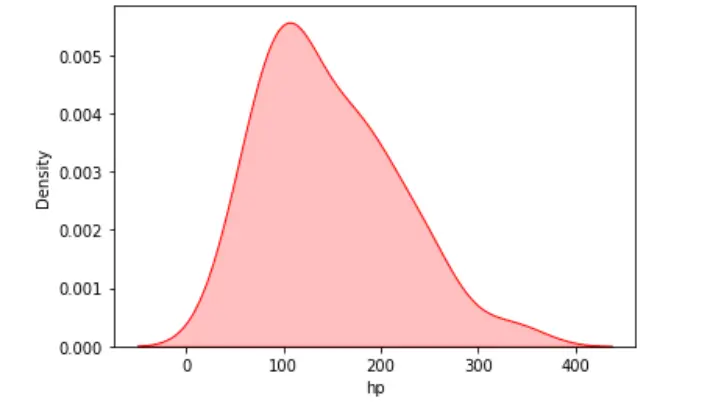
我們可以使用 KDE 圖來視覺化單個目標或連續屬性的概率分佈。在以下示例中,我們讀取了 mtcars 資料集的 CSV 檔案。
我們的資料集中有 350 多個條目,我們將沿 x 軸視覺化單變數分佈。
示例程式碼:
import seaborn as sn
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# read CSV file of dataset using pandas
dataset = pd.read_csv(r"C:\\Users\\DELL\\OneDrive\\Desktop\\samplecardataset.csv")
# kde plot using seaborn
sn.kdeplot(data=dataset, x="hp", shade=True, color="red")
plt.show()
輸出:
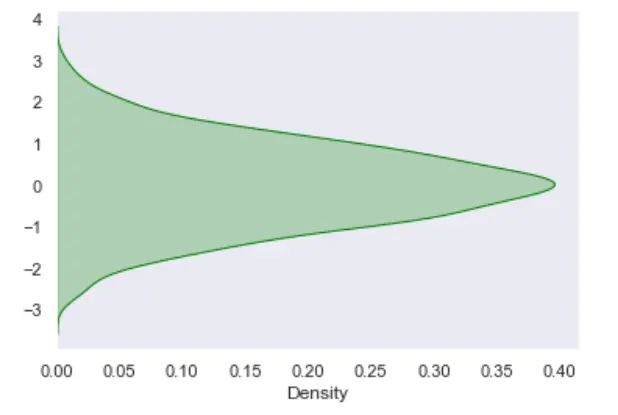
你還可以通過沿 y 軸視覺化資料變數來翻轉繪圖。
示例程式碼:
import seaborn as sn
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# Read CSV file using pandas
dataset = pd.read_csv(r"C:\\Users\\DELL\\OneDrive\\Desktop\\samplecardataset.csv")
# KDE plotting using seaborn
sn.kdeplot(data=dataset, y="hp", shade=True, color="red")
plt.show()
輸出:
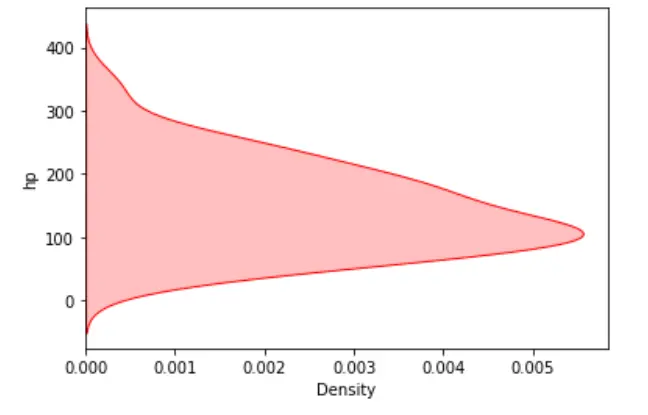
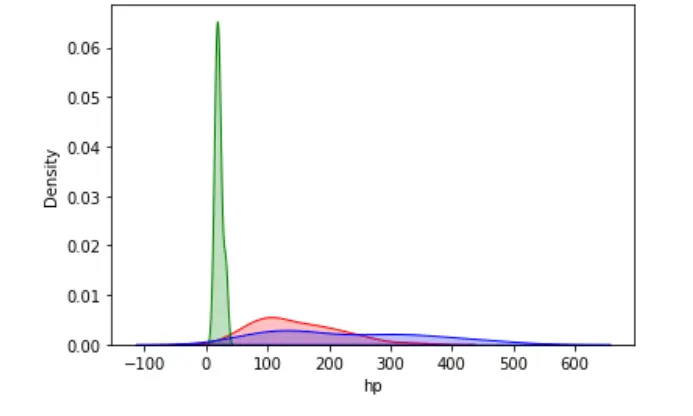
我們可以在單個圖中視覺化多個目標值的概率分佈。
示例程式碼:
import seaborn as sn
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# Read CSV file using pandas
dataset = pd.read_csv(r"C:\\Users\\DELL\\OneDrive\\Desktop\\samplecardataset.csv")
# KDE plotting using seaborn
sn.kdeplot(data=dataset, x="hp", shade=True, color="red")
sn.kdeplot(data=dataset, x="mpg", shade=True, color="green")
sn.kdeplot(data=dataset, x="disp", shade=True, color="blue")
plt.show()
輸出:
在 Python 中使用 Pandas 和 Seaborn 繪製二維或二元 KDE 圖
我們可以使用 seaborn 和 pandas 庫在二維或雙變數 KDE 圖中視覺化資料。
通過這種方式,我們可以視覺化給定樣本針對多個連續屬性的概率分佈。我們沿 x 和 y 軸視覺化資料。
示例程式碼:
import seaborn as sn
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# Read CSV file using pandas
dataset = pd.read_csv(r"C:\\Users\\DELL\\OneDrive\\Desktop\\samplecardataset.csv")
# KDE plotting using seaborn
sn.kdeplot(data=dataset, shade=True, x="hp", y="mpg")
plt.show()
輸出:
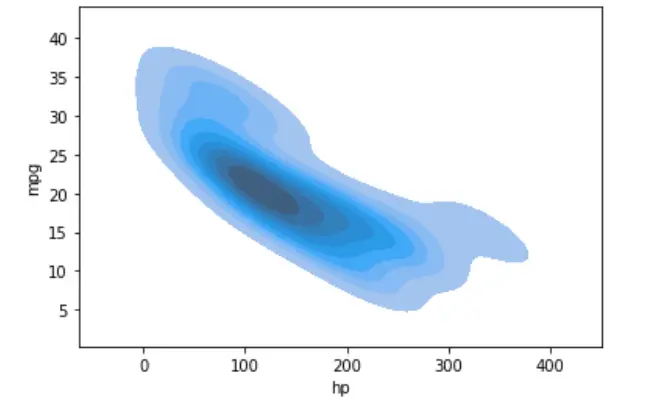
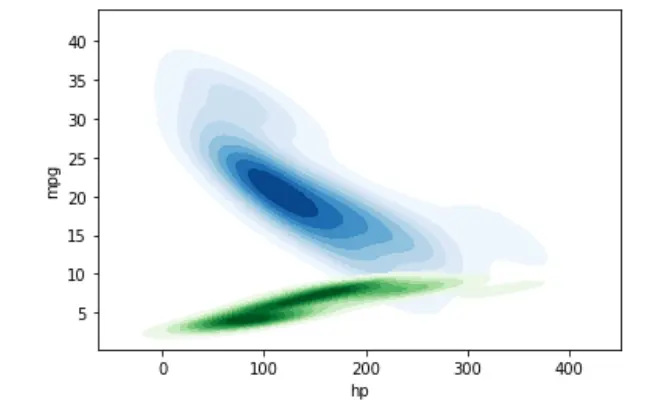
同樣,我們可以使用單個 KDE 圖繪製多個樣本的概率分佈。
示例程式碼:
import seaborn as sn
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# Read CSV file using pandas
dataset = pd.read_csv(r"C:\\Users\\DELL\\OneDrive\\Desktop\\samplecardataset.csv")
# KDE plotting using seaborn
sn.kdeplot(data=dataset, shade=True, x="hp", y="mpg", cmap="Blues")
sn.kdeplot(data=dataset, shade=True, x="hp", y="cyl", cmap="Greens")
plt.show()
輸出:
まとめ
我們在本教程中演示了使用 Pandas 和 Seaborn 庫的 KDE 繪圖視覺化。我們已經看到如何在一維 KDE 圖中視覺化單個和多個樣本的概率分佈。
我們討論瞭如何使用帶有 Seaborn 和 Pandas 的 KDE 圖來視覺化二維資料。