Python Pandas pandas.pivot_table() Função
-
Sintaxe da função
pandas.pivot_table() -
Códigos de exemplo:
pandas.pivot_table() -
Códigos de exemplo:
pandas.pivot_table()para Especificar Função Agregada Múltipla -
Códigos de exemplo:
pandas.pivot_table()para utilizar o parâmetromargins
A função Python Pandas pandas.pivot_table() evita a repetição de dados da função DataFrame. Resume os dados e aplica diferentes funções agregadas sobre os dados.
Sintaxe da função pandas.pivot_table()
pandas.pivot_table(
data,
values=None,
index=None,
columns=None,
aggfunc="mean",
fill_value=None,
margins=False,
dropna=True,
margins_name="All",
observed=False,
)
Parâmetros
Esta função tem vários parâmetros. Os valores por defeito de todos os parâmetros são mencionados acima.
data |
É o DataFrame do qual queremos remover os dados repetidos. |
values |
Representa a coluna a agregar. |
index |
É uma column, grouper, array, ou uma lista. Representa a coluna de dados que queremos como índice, ou seja, como filas. |
columns |
É uma column, grouper, array, ou uma lista. Representa a coluna de dados que queremos como colunas na nossa tabela pivot de saída. |
aggfunc |
É uma função, lista de funções, ou um dicionário. Representa a função agregada que será aplicada aos dados. Se uma lista de funções agregadas for aprovada, então haverá uma coluna para cada função agregada na tabela resultante com o nome da coluna no topo. |
fill_value |
É um escalar. Representa o valor que irá substituir os valores em falta na tabela de saída |
margins |
É um valor booleano. Representa a linha e a coluna geradas após tomar a soma da respectiva linha e coluna. |
dropna |
É um valor booleano. Elimina as colunas cujos valores são NaN da tabela de saída. |
margins_name |
É um string. Representa o nome da linha e da coluna gerada se o valor margins for True. |
observed |
É um valor booleano. Se qualquer garoupa for categórica, então este parâmetro aplica-se. Se for True, mostra os valores observados para as garoupas categóricas. Se for False, mostra todos os valores para agrupadores categóricos. |
Devolver
Devolve o resumo DataFrame.
Códigos de exemplo: pandas.pivot_table()
Vamos aprofundar esta função, implementando-a.
import pandas as pd
dataframe = pd.DataFrame({
"Name":
["Olivia",
"Olivia",
"Olivia",
"Olivia",
"Meghan",
"Meghan",
"Meghan",
"Meghan"],
"Date":
["03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019"],
"Science Marks":
[10,
2,
4,
6,
8,
9,
1,
10]
})
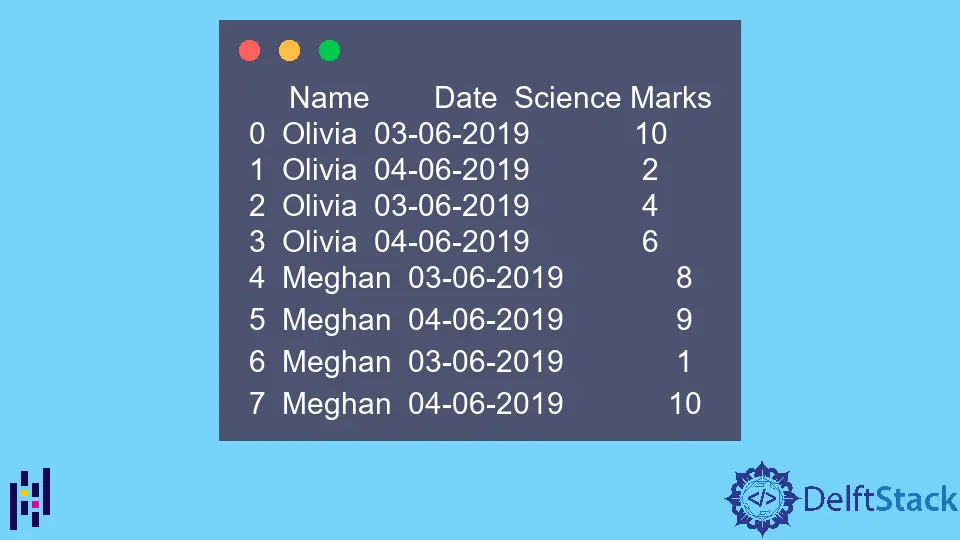
print(dataframe)
O exemplo DataFrame é,
Name Date Science Marks
0 Olivia 03-06-2019 10
1 Olivia 04-06-2019 2
2 Olivia 03-06-2019 4
3 Olivia 04-06-2019 6
4 Meghan 03-06-2019 8
5 Meghan 04-06-2019 9
6 Meghan 03-06-2019 1
7 Meghan 04-06-2019 10
Note-se que os dados acima indicados contêm o mesmo valor numa coluna várias vezes. Esta função pivot_table resumirá estes dados.
import pandas as pd
dataframe = pd.DataFrame(
{
"Name": [
"Olivia",
"Olivia",
"Olivia",
"Olivia",
"Meghan",
"Meghan",
"Meghan",
"Meghan",
],
"Date": [
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
],
"Science Marks": [10, 2, 4, 6, 8, 9, 1, 10],
}
)
pivotTable = pd.pivot_table(dataframe, index="Name", columns="Date")
print(pivotTable)
Resultado:
Science Marks
Date 03-06-2019 04-06-2019
Name
Meghan 4.5 9.5
Olivia 7.0 4.0
Aqui, escolhemos a coluna Name como o índice e a “Data” como a coluna. A função gerou o resultado com base nos parâmetros predefinidos. A função agregada predefinida mean() calculou a média dos valores.
Códigos de exemplo: pandas.pivot_table() para Especificar Função Agregada Múltipla
import pandas as pd
dataframe = pd.DataFrame(
{
"Name": [
"Olivia",
"Olivia",
"Olivia",
"Olivia",
"Meghan",
"Meghan",
"Meghan",
"Meghan",
],
"Date": [
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
],
"Science Marks": [10, 2, 4, 6, 8, 9, 1, 10],
}
)
pivotTable = pd.pivot_table(
dataframe, index="Name", columns="Date", aggfunc=["sum", "count"]
)
print(pivotTable)
Resultado:
sum count
Science Marks Science Marks
Date 03-06-2019 04-06-2019 03-06-2019 04-06-2019
Name
Meghan 9 19 2 2
Olivia 14 8 2 2
Utilizámos duas funções agregadas. As colunas destas funções são geradas separadamente.
Códigos de exemplo: pandas.pivot_table() para utilizar o parâmetro margins
import pandas as pd
dataframe = pd.DataFrame(
{
"Name": [
"Olivia",
"Olivia",
"Olivia",
"Olivia",
"Meghan",
"Meghan",
"Meghan",
"Meghan",
],
"Date": [
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
],
"Science Marks": [10, 2, 4, 6, 8, 9, 1, 10],
}
)
pivotTable = pd.pivot_table(
dataframe, index="Name", columns="Date", aggfunc=["sum", "count"], margins=True
)
print(pivotTable)
Resultado:
sum count
Science Marks Science Marks
Date 03-06-2019 04-06-2019 All 03-06-2019 04-06-2019 All
Name
Meghan 9 19 28 2 2 4
Olivia 14 8 22 2 2 4
All 23 27 50 4 4 8
O parâmetro margins gerou uma nova linha chamada All e uma nova coluna chamada também como All que mostram a soma da linha e da coluna respectivamente.