이진 검색 트리 Inorder Succesor
- BST 알고리즘의 Inorder 후계자
- BST 일러스트레이션의 Inorder 후속 제품
- BST 구현의 Inorder 후계자
- BST 알고리즘에서 Inorder Successor의 복잡성
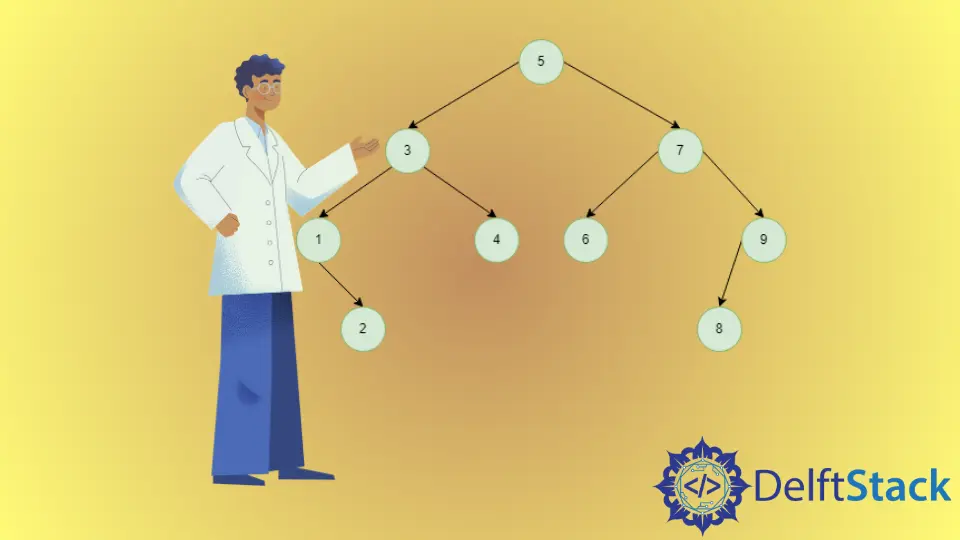
이진 트리의 inorder 후계자는 이진 트리의 inorder traversal에서 다음으로 오는 노드입니다. 따라서 트리 내부의 마지막 노드는NULL입니다. 이진 검색 트리의 순회 순회는 정렬 된 배열이기 때문에. 주어진 노드보다 큰 키가 가장 작은 노드는 그 후속 노드로 정의됩니다. BST에는 노드의 오른쪽 하위 트리 또는 조상에서 가장 적은 값을 갖는 노드 인 순차 후속 작업에 대한 두 가지 가능성이 있습니다. 그렇지 않으면 노드의 inorder 후속 작업이 존재하지 않습니다.
BST 알고리즘의 Inorder 후계자
root==NULL이면succ를NULL로 설정하고 반환합니다.root-> data<current-> data인 경우succ는current로current는current-> left로 표시됩니다.root-> data>current-> data인 경우current는current-> right로 표시됩니다.root-> data==current-> data및root-> right!=NULL,succ=minimum(current-> right)인 경우.succ를 반환합니다.
BST 일러스트레이션의 Inorder 후속 제품

3의 순차 후속자는4입니다.3에는 오른쪽 노드가 있고4는 오른쪽 하위 트리에서3보다 큰 가장 작은 노드이기 때문입니다.
4의 순차 후계자는5입니다.4에는 올바른 노드가 없기 때문에 해당 조상을 확인해야하며 그 중에서5는4보다 큰 가장 작은 노드입니다.
BST 구현의 Inorder 후계자
#include <iostream>
using namespace std;
class Node {
public:
int data;
Node *left, *right;
Node(int x) {
this->data = x;
this->left = this->right = NULL;
}
};
Node* insert(Node* root, int key) {
if (root == NULL) {
return new Node(key);
}
if (key < root->data) {
root->left = insert(root->left, key);
} else {
root->right = insert(root->right, key);
}
return root;
}
Node* getNextleft(Node* root) {
while (root->left) {
root = root->left;
}
return root;
}
void inorderSuccessor(Node* root, Node*& succ, int key) {
if (root == NULL) {
succ = NULL;
return;
}
if (root->data == key) {
if (root->right) {
succ = getNextleft(root->right);
}
}
else if (key < root->data) {
succ = root;
inorderSuccessor(root->left, succ, key);
} else {
inorderSuccessor(root->right, succ, key);
}
}
int main() {
int keys[] = {1, 5, 8, 2, 6, 3, 7, 4};
Node* root = NULL;
for (int key : keys) {
root = insert(root, key);
}
for (int key : keys) {
Node* prec = NULL;
inorderSuccessor(root, prec, key);
if (prec) {
cout << "Inorder successor of node " << key << " is " << prec->data;
} else {
cout << "No inorder Successor of node " << key;
}
cout << '\n';
}
return 0;
}
BST 알고리즘에서 Inorder Successor의 복잡성
시간 복잡성
- 평균 사례
평균적인 경우 BST에서 순서가 뒤 따르는 것을 찾는 시간 복잡도는 이진 검색 트리의 높이 순서입니다. 평균적으로 BST의 높이는O(logn)입니다. 형성된 BST가 균형 BST 일 때 발생합니다. 따라서 시간 복잡도는 [Big Theta] :O(logn)의 순서입니다.
- 베스트 케이스
최상의 경우는 트리가 균형 잡힌 BST 일 때 발생합니다. 삭제의 가장 좋은 경우 시간 복잡도는O(logn)순서입니다. 평균 케이스 시간 복잡성과 동일합니다.
- 최악의 경우
최악의 경우 루트에서 가장 깊은 리프 노드, 즉 트리의 전체 높이h로 이동해야 할 수 있습니다. 트리의 균형이 맞지 않는 경우 (예 : 치우친 경우) 트리의 높이가n이 될 수 있으므로 삽입 및 검색 작업의 최악의 경우 시간 복잡성은O(n)입니다.
공간 복잡성
알고리즘의 공간 복잡도는 재귀 호출에 필요한 추가 공간으로 인해O(h)입니다.

Harshit Jindal has done his Bachelors in Computer Science Engineering(2021) from DTU. He has always been a problem solver and now turned that into his profession. Currently working at M365 Cloud Security team(Torus) on Cloud Security Services and Datacenter Buildout Automation.
LinkedIn