이진 검색 트리
- 이진 검색 트리에서 검색 작업
- BST 검색 알고리즘
- BST 검색 일러스트레이션
- BST에 삽입
- BST 삽입 알고리즘
- BST 삽입 그림
- BST 검색 및 삽입 구현
- BST 삽입 및 검색 알고리즘 복잡성
이진 검색 트리 (BST)는 정렬 된 노드 기반 이진 트리 데이터 구조입니다. 노드에는 값이 있고 두 개의 자식 노드 (이진 트리에는 최대 두 개의 자식 노드가 있음)가 왼쪽과 오른쪽에 연결됩니다. 루트 노드를 제외하고 모든 노드는 상위 노드에서만 참조 할 수 있습니다. BST에는 다음과 같은 속성이 있습니다.
- 왼쪽 하위 트리의 모든 노드가 루트 노드보다 작습니다.
- 오른쪽 하위 트리의 모든 노드가 루트 노드보다 큽니다.
- 왼쪽 및 오른쪽 하위 트리도 이진 검색 트리 여야합니다.

왼쪽 트리는 BST의 모든 속성을 충족합니다. 반면에 왼쪽 하위 트리의 모든 노드가 더 작고 오른쪽 하위 트리의 모든 노드가 더 크기 때문에 오른쪽의 트리는 BST 인 것처럼 보입니다. 그러나 왼쪽 하위 트리의 노드
1은 노드4보다 작지만 루트 노드3보다 크지 않기 때문에 BST 속성을 만족하지 않습니다. 따라서 BST가 아닙니다.
정렬 된 데이터 구조이므로 입력 된 요소는 항상 정렬 된 방식으로 구성됩니다. 순회 순회를 사용하여 BST에 저장된 데이터를 정렬 된 순서로 검색 할 수 있습니다. 이진 검색과 마찬가지로O(logn)에서 데이터를 검색하는 데 사용할 수 있기 때문에 이름이 지정됩니다.
이진 검색 트리에서 검색 작업
BST에서 루트의 오른쪽에있는 모든 요소가 더 크므로 검색하는 대상 요소가 루트보다 작 으면 전체 오른쪽 하위 트리를 무시할 수 있습니다. 마찬가지로 요소가 루트보다 크면 왼쪽 하위 트리를 무시할 수 있습니다. 우리는 트리를 소모하거나 하위 트리의 루트로 대상 요소를 찾을 때까지 비슷한 방식으로 이동합니다. BST가 균형을 이루는 경우 (모든 노드에 대해 왼쪽 및 오른쪽 하위 트리의 높이 차이가 1보다 작 으면 트리를 균형 트리라고 함) BST 내부 검색은 둘 다 이진 검색과 유사하게 수행됩니다. 하위 트리에는 모든 반복에서 무시되는 요소의 약 절반이 있지만 불균형 트리의 경우 모든 노드가 동일한쪽에있을 수 있으며 검색은 선형 검색과 유사하게 수행 될 수 있습니다.
BST 검색 알고리즘
root를 BST의 루트 노드로하고X를 검색 대상 요소로 지정합니다.
-
root==NULL이면NULL을 반환합니다. -
X==root->data이면root를 반환합니다. -
X<root->data이면search(root->left)를 반환합니다. -
X>root->data인 경우search(root->right)를 반환합니다.
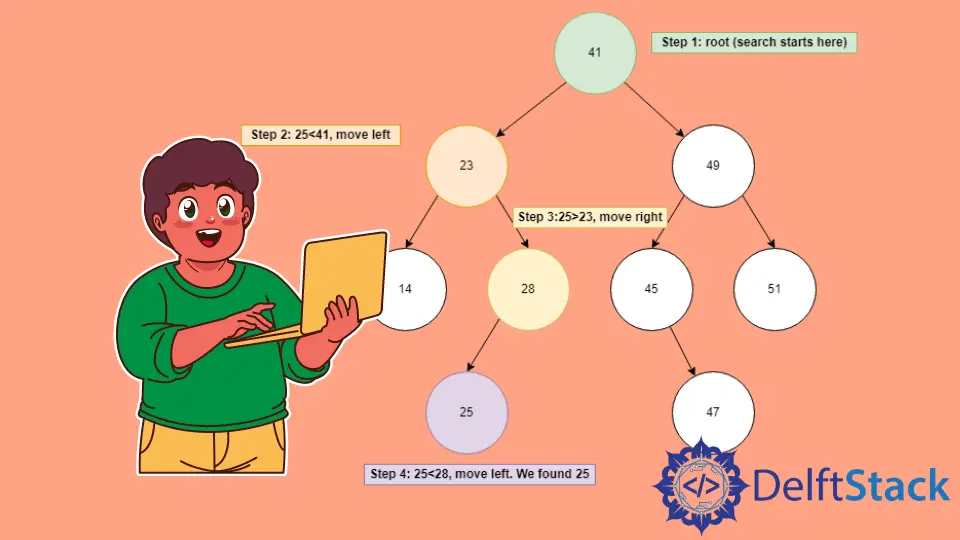
BST 검색 일러스트레이션

위의 BST가 있고X=25요소를 찾고 싶다고 가정합니다.
-
루트 요소를
X와 비교하여41>25를 찾으므로 오른쪽 절반을 버리고 왼쪽 하위 트리로 이동합니다. -
왼쪽 하위 트리
23<25의 루트는 왼쪽 하위 트리를 버리고 오른쪽으로 이동합니다. -
새 루트
28<25이므로 왼쪽으로 이동하여X요소가25와 같음을 찾아 노드를 반환합니다.
BST에 삽입
BST 내부에 요소를 삽입하는 알고리즘은 요소를 삽입하기 전에 올바른 위치를 찾아야하기 때문에 BST 내부에서 요소를 검색하는 것과 매우 유사합니다. 삽입 및 검색 기능의 유일한 차이점은 검색의 경우 대상 값이 포함 된 노드를 반환하는 반면 삽입의 경우 노드의 적절한 위치에 새 노드를 생성한다는 것입니다.
BST 삽입 알고리즘
root를 BST의 루트 노드로,X를 삽입하려는 요소로 설정합니다.
-
root==NULL이면data=X를 사용하여 새로 형성된 노드를 반환합니다. -
if (
X<root->data),root->left=insert(root->left, X); -
else if (
X>root->data),root->right=insert(root->right, X); -
원래
root에 대한 포인터를 반환합니다.
BST 삽입 그림

-
먼저
root노드를 생성하여 BST를 초기화하고 여기에5를 삽입합니다. -
3은5보다 작아서5의 왼쪽에 삽입됩니다. -
4는5보다 작지만3보다 커서3의 오른쪽에 삽입되고4의 왼쪽에 삽입됩니다. -
2는 현재 트리에서 가장 작은 요소이므로 가장 왼쪽에 삽입됩니다. -
1은 현재 트리에서 가장 작은 요소이므로 가장 왼쪽에 삽입됩니다. -
6은 현재 트리에서 가장 큰 요소이므로 가장 오른쪽에 삽입됩니다.
이것이 BST 안에 요소를 삽입하는 방법입니다.
BST 검색 및 삽입 구현
#include <iostream>
using namespace std;
class Node {
public:
int key;
Node *left, *right;
};
Node *newNode(int item) {
Node *temp = (Node *)malloc(sizeof(Node));
temp->key = item;
temp->left = temp->right = NULL;
return temp;
}
void inorder(Node *root) {
if (root != NULL) {
inorder(root->left);
cout << root->key << " ";
inorder(root->right);
}
}
Node *insert(Node *root, int key) {
if (root == NULL) return newNode(key);
if (key < root->key)
root->left = insert(root->left, key);
else
root->right = insert(root->right, key);
return root;
}
Node *search(Node *root, int key) {
if (root == NULL || root->key == key) return root;
if (root->key < key) return search(root->right, key);
return search(root->left, key);
}
int main() {
Node *root = NULL;
root = insert(root, 5);
root = insert(root, 3);
root = insert(root, 8);
root = insert(root, 6);
root = insert(root, 4);
root = insert(root, 2);
root = insert(root, 1);
root = insert(root, 7);
cout << search(root, 5)->key << endl;
}
BST 삽입 및 검색 알고리즘 복잡성
시간 복잡성
- 평균 사례
평균적인 경우, BST에서 노드를 삽입하거나 요소를 검색하는 시간 복잡도는 이진 검색 트리의 높이 순서입니다. 평균적으로 BST의 높이는O(logn)입니다. 형성된 BST가 균형 BST 일 때 발생합니다. 따라서 시간 복잡도는 [Big Theta] :O(logn)의 순서입니다.
- 베스트 케이스
최상의 경우는 트리가 균형 잡힌 BST 일 때 발생합니다. 삽입 및 검색의 가장 좋은 경우 시간 복잡성은O(logn)순서입니다. 평균 케이스 시간 복잡성과 동일합니다.
- 최악의 경우
최악의 경우 루트에서 가장 깊은 리프 노드, 즉 트리의 전체 높이h로 이동해야 할 수 있습니다. 트리의 균형이 맞지 않는 경우, 즉 치우친 경우 트리의 높이가n이 될 수 있으므로 삽입 및 검색 작업의 최악의 경우 시간 복잡도는O(n)입니다.
공간 복잡성
삽입 및 검색 작업의 공간 복잡성은 재귀 호출에 필요한 공간으로 인해O(n)입니다.

Harshit Jindal has done his Bachelors in Computer Science Engineering(2021) from DTU. He has always been a problem solver and now turned that into his profession. Currently working at M365 Cloud Security team(Torus) on Cloud Security Services and Datacenter Buildout Automation.
LinkedIn