Seaborn에서 선형 회귀 생성
이 기사는 선형 회귀에 대해 자세히 알아보고 Seaborn의 regplot() 메서드를 사용하여 선형 회귀를 생성하는 방법을 알아보는 것을 목표로 합니다.
Seaborn에서 regplot() 메서드를 사용하여 선형 회귀 생성
regplot() 함수의 전체 목적은 데이터에 대한 선형 회귀 모델을 구축하고 시각화하는 것입니다. regplot()은 회귀 플롯을 나타냅니다.
Seaborn을 사용하여 회귀 플롯을 작성하는 방법을 알아보기 위해 코드를 바로 살펴보겠습니다. 이제 Seaborn 라이브러리와 pyplot 모듈을 가져오고 seaborn 라이브러리에서 일부 데이터도 가져옵니다.
이 데이터는 모두 다이아몬드에 관한 것입니다. 따라서 이 데이터 프레임의 각 행은 하나의 특정 다이아몬드와 다른 속성에 관한 것입니다.
import matplotlib.pyplot as plot
import seaborn as sb
DATA = sb.load_dataset("diamonds").dropna()
DATA.head()
출력:

이제 각 다이아몬드를 점으로 나타낼 것이기 때문에 이 데이터 세트에서 190개의 임의 샘플을 수집합니다.
DATA = DATA.sample(n=190, random_state=38)
이제 회귀 플롯을 시작할 준비가 되었습니다. seaborn 회귀 플롯을 작성하려면 regplot() 메소드로 참조를 사용해야 합니다.
여기에서는 이 방법으로 캐럿과 가격의 두 시리즈를 전달합니다.
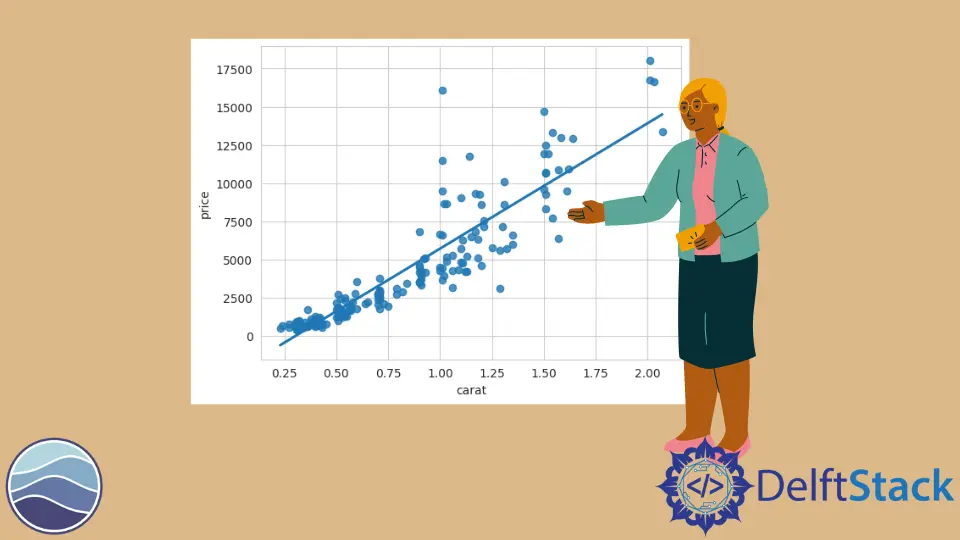
sb.regplot(DATA.carat, DATA.price)
위에 제공된 예제의 전체 소스 코드는 다음과 같습니다.
import matplotlib.pyplot as plot
import seaborn as sb
DATA = sb.load_dataset("diamonds").dropna()
DATA.head()
DATA = DATA.sample(n=190, random_state=38)
sb.set_style("whitegrid")
sb.regplot(DATA.carat, DATA.price)
plot.show()
이제 seaborn이 우리를 위해 무엇을 했는지 볼 수 있습니다. 첫 번째 계열은 x축을 따라 그려지고 두 번째 계열은 y축을 따라 그려집니다.
이러한 데이터에 적합한 선형 모델이 있습니다. 이 선은 모든 산란점을 통과합니다.
출력:

이제 우리는 선형 모델이 어떻게 생겼는지 압니다.
구문에 대한 또 다른 점은 Seaborn regplot()을 생성하는 또 다른 방법은 data 인수로 전체 데이터 프레임을 참조하는 것입니다.
sb.regplot(x="carat", y="price", data=DATA)
x 및 y 인수에 대한 열 이름으로 참조를 제공합니다. 그러면 동일한 플롯이 생성됩니다.
출력:

알 수 있듯이 이 플롯에는 산포 부분과 선형 회귀선이라는 두 가지 구성 요소가 있습니다. 회귀 모델을 이러한 데이터에 맞추지 않으려면 fit_reg=False를 전달할 수 있습니다.
import matplotlib.pyplot as plot
import seaborn as sb
DATA = sb.load_dataset("diamonds").dropna()
DATA.head()
DATA = DATA.sample(n=190, random_state=38)
sb.set_style("whitegrid")
sb.regplot(x="carat", y="price", data=DATA, fit_reg=False)
plot.show()
출력:

회귀선만 있는 플롯을 선호하는 경우 다른 옵션은 선형 회귀선만 플롯하는 것입니다. scatter 인수를 사용하여 분산점을 꺼야 합니다. 이 인수는 False와 같아야 합니다.
import matplotlib.pyplot as plot
import seaborn as sb
DATA = sb.load_dataset("diamonds").dropna()
DATA.head()
DATA = DATA.sample(n=190, random_state=38)
sb.set_style("whitegrid")
sb.regplot(x="carat", y="price", data=DATA, scatter=False)
plot.show()
출력:

일반 회귀 플롯을 플롯하면 선 주위에 음영 영역이 있는 줄무늬 영역이 표시됩니다. 이를 신뢰 구간이라고 합니다.
이를 끄려면 ci 인수를 사용하여 None과 동일하게 설정할 수 있습니다.
import matplotlib.pyplot as plot
import seaborn as sb
DATA = sb.load_dataset("diamonds").dropna()
DATA.head()
DATA = DATA.sample(n=190, random_state=38)
sb.set_style("whitegrid")
sb.regplot(x="carat", y="price", data=DATA, ci=None)
plot.show()
출력:

음영 처리된 밴드가 아닌 선만 제공하는 신뢰 구간을 완전히 해제합니다.
또한 이러한 축 중 하나에 대해 사용하려는 이산 변수가 있는 경우 어떤 일이 발생하는지 보여주고 싶습니다. 따라서 일부 정보를 숫자 값으로 변환합니다.
CUT_MAP = {"Fair": 1, "Good": 2, "Very Good": 3, "Premium": 4, "Ideal": 5}
우리는 각 다이아몬드의 “컷"을 가지고 있고 그것을 최악의 컷에 매핑하고 카테고리를 오름차순으로 설정합니다.
DATA["CUT_VALUE"] = DATA.cut.map(CUT_MAP).cat.as_ordered()
CUT_VALUE 열을 생성했으며 인쇄하면 1에서 5까지의 값이 있음을 알 수 있습니다.
import matplotlib.pyplot as plot
import seaborn as sb
DATA = sb.load_dataset("diamonds").dropna()
DATA.head()
DATA = DATA.sample(n=190, random_state=38)
sb.set_style("whitegrid")
CUT_MAP = {"Fair": 1, "Good": 2, "Very Good": 3, "Premium": 4, "Ideal": 5}
DATA["CUT_VALUE"] = DATA.cut.map(CUT_MAP).cat.as_ordered()
sb.regplot(x="CUT_VALUE", y="price", data=DATA)
plot.show()
출력:

이 CUT_VALUE 열을 x 값으로 사용하려고 하면 많은 산점점이 서로 쌓이는 것을 볼 수 있습니다. 선형 회귀 아래에서 그것들을 보는 것은 정말 어려울 수 있습니다.
따라서 x_jitter 속성이 제어하는 약간의 지터를 추가할 수 있습니다. 각 스캐터 포인트를 가져와서 왼쪽이나 오른쪽으로 이동합니다.
import numpy as np
import matplotlib.pyplot as plot
import seaborn as sb
DATA = sb.load_dataset("diamonds").dropna()
DATA.head()
DATA = DATA.sample(n=190, random_state=38)
sb.set_style("whitegrid")
CUT_MAP = {"Fair": 1, "Good": 2, "Very Good": 3, "Premium": 4, "Ideal": 5}
DATA["CUT_VALUE"] = DATA.cut.map(CUT_MAP).cat.as_ordered().astype(np.int8)
sb.regplot(x="CUT_VALUE", y="price", data=DATA, x_jitter=0.1)
plot.show()
출력:

이렇게 하면 산란점의 덩어리가 모여 있는 위치를 확인할 수 있습니다.
우리가 할 수 있는 다른 일은 불연속 변수가 있는 경우입니다. 각 개별 분산점을 플로팅하는 대신 x_estimator 인수를 사용하여 해당 점에 대한 추정기를 사용할 수 있습니다.
import numpy as np
import matplotlib.pyplot as plot
import seaborn as sb
DATA = sb.load_dataset("diamonds").dropna()
DATA.head()
DATA = DATA.sample(n=190, random_state=38)
sb.set_style("whitegrid")
CUT_MAP = {"Fair": 1, "Good": 2, "Very Good": 3, "Premium": 4, "Ideal": 5}
DATA["CUT_VALUE"] = DATA.cut.map(CUT_MAP).cat.as_ordered().astype(np.int8)
sb.regplot(x="CUT_VALUE", y="price", data=DATA, x_estimator=np.mean)
plot.show()
이러한 불연속 점을 그룹화하고 해당 값에 대한 평균 및 일부 신뢰 구간을 계산했습니다. 이제는 많은 포인트가 서로 쌓여 있어도 읽기 쉽습니다.
출력:


Hello! I am Salman Bin Mehmood(Baum), a software developer and I help organizations, address complex problems. My expertise lies within back-end, data science and machine learning. I am a lifelong learner, currently working on metaverse, and enrolled in a course building an AI application with python. I love solving problems and developing bug-free software for people. I write content related to python and hot Technologies.
LinkedIn