Seaborn 히스토그램 플롯
이 기사에서는 Seaborn histplot() 기능을 사용하여 히스토그램을 만드는 방법에 대해 설명합니다. 또한 distplot() 함수에서 오류가 발생하는 이유도 살펴보겠습니다.
그런 다음 Seaborn에서 여러 플롯을 그룹화하는 방법을 배웁니다.
Seaborn histplot() 함수를 사용하여 Python에서 히스토그램을 플로팅합니다.
Seaborn에 익숙하거나 설명서를 따라왔다면 히스토그램을 구축하는 이전 방법이 distplot을 사용했다는 것을 알 수 있습니다. 이 모든 것이 Seaborn의 최신 버전으로 변경되었습니다.
이제 distplot()이 더 이상 사용되지 않으며 대신 histplot()을 사용하여 히스토그램을 작성해야 한다는 경고가 표시됩니다.
Seaborn 버전 0.11.2에는 3개의 새로운 배포 플롯이 포함되어 있으므로 새로운 seaborn histplot의 기본 사항부터 시작하여 코드를 작성해 보겠습니다.
계속해서 Seaborn과 별칭을 sb로 가져옵니다. 계속 진행하려면 최신 Seaborn 버전으로 작업해야 함을 다시 한 번 상기시켜 드리고 싶었습니다.
따라서 다음 명령으로 버전을 확인하십시오.
import seaborn as sb
sb.__version__
출력:
'0.11.2'
이제 Seaborn 라이브러리에서 일부 데이터를 로드할 것입니다. 이 데이터는 펭귄에 관한 것입니다.
PG_Data = sb.load_dataset("penguins")
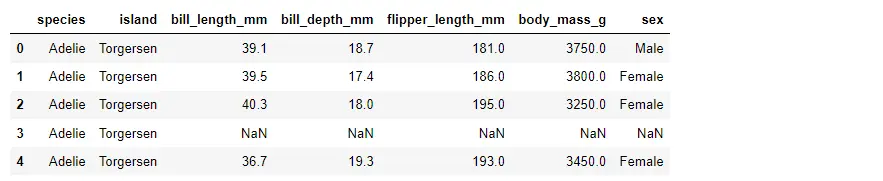
PG_Data.head()
다양한 펭귄 종에 대한 다양한 측정치가 있습니다.
PG_Data.shape
344개의 관찰이 있지만 null 값을 삭제하고 333개의 관찰을 남깁니다.
PG_Data.dropna(inplace=True)
PG_Data.shape
출력:
(333, 7)
이제 우리는 플로팅 목적으로 이 작업을 수행하고 있으므로 Seaborn 히스토그램 플롯을 작성해 보겠습니다.
먼저 Seaborn 스타일을 사용하고 Seaborn 라이브러리를 참조하며 sb.histplot()을 호출합니다.
그렇다면 펭귄에서 부리_길이_mm 시리즈를 넘기겠습니다. 히스토그램을 그리기 위해 데이터 프레임에서 하나의 열만 선택합니다.
sb.set_style("whitegrid")
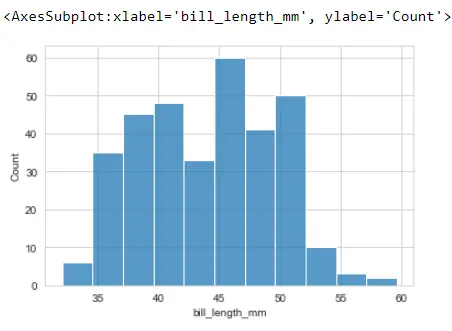
sb.histplot(PG_Data.bill_length_mm)
여기에서 구문을 수행하는 다른 방법도 있습니다. 전체 데이터 프레임을 이 data 인수에 전달한 다음 히스토그램으로 표시하려는 열을 전달할 수 있습니다.
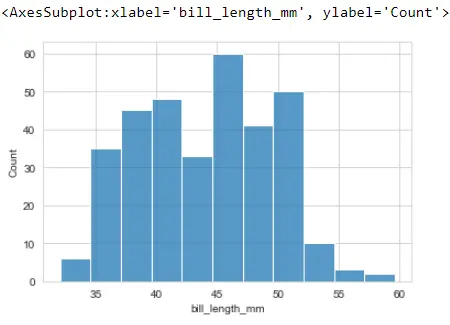
sb.histplot(x="bill_length_mm", data=PG_Data)
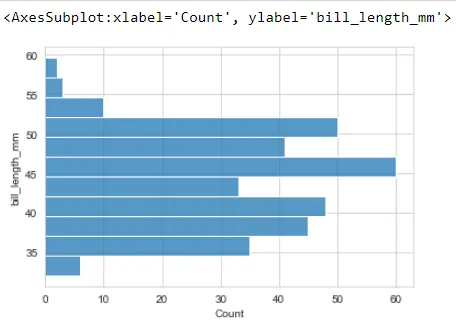
수직 막대 대신 수평 막대를 만들 수 있습니다. 대신 이를 y로 전환하여 수평 히스토그램을 생성할 수 있습니다.
sb.histplot(y="bill_length_mm", data=PG_Data)
오래된 seaborn distplot에 익숙하다면 distplot을 사용하면 kde 플롯이 히스토그램 위에 그려지고 새로운 seaborn histplot에서 이를 다시 켤 수 있음을 알 수 있습니다.
이 kde 인수를 참조하고 True와 동일하게 설정합니다.
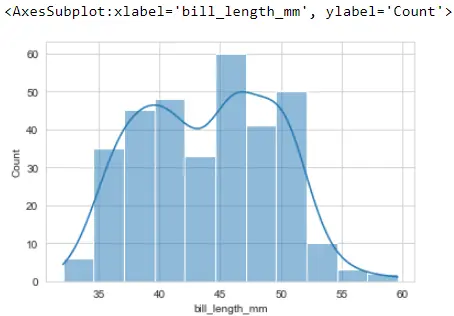
sb.histplot(x="bill_length_mm", data=PG_Data, kde=True)
이것은 이전 distplot 버전에 대해 Seaborn이 생성한 것과 매우 유사하게 보입니다. kde 플롯에 익숙하지 않다면 여기를 읽어보세요.
bins, binwidth 및 binrange 인수와 함께 histplot() 사용
기본적으로 Seaborn은 데이터에 적합한 빈 수를 결정하려고 시도하지만 몇 가지 다른 것을 허용하는 bins라는 인수를 사용하여 전환할 수 있습니다.
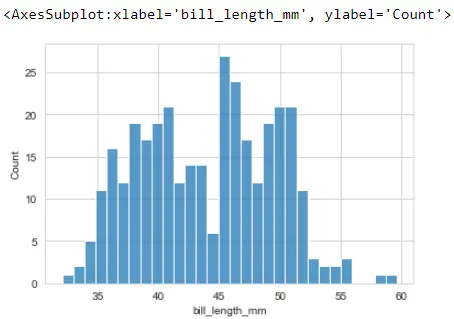
빈이 30이라고 가정해 보겠습니다. 이렇게 하면 범위 전체에 걸쳐 동일한 간격으로 30개의 별도 빈이 생성되고 대략적인 분포가 표시됩니다.
sb.histplot(x="bill_length_mm", data=PG_Data, bins=30)
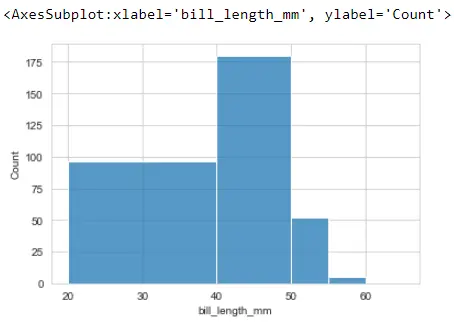
어떤 이유로 해당 저장소를 표시할 특정 위치가 있습니다. 또한 각 숫자가 히스토그램 빈의 시작 및 중지 위치인 목록을 전달할 수도 있습니다.
sb.histplot(x="bill_length_mm", data=PG_Data, bins=[20, 40, 50, 55, 60, 65])
우리는 어떤 이유로 쓰레기통을 불규칙한 간격으로 만들도록 선택할 수 있습니다. 매우 유용한 두 가지 인수는 binwidth와 binrange입니다.
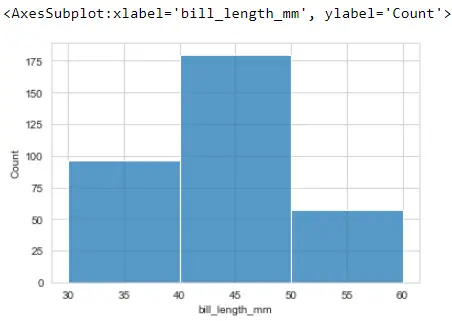
binwidth에서 입력할 수 있는 모든 값으로 설정할 수 있습니다. 그러나 우리는 10을 넣었으므로 10단위가 필요합니다.
binrange 인수를 사용하여 빈 범위를 정의할 수 있으며 튜플을 전달하여 값을 시작하고 중지해야 합니다.
sb.histplot(x="bill_length_mm", data=PG_Data, binwidth=10, binrange=(30, 60))
Seaborn의 FacetGrid() 기능으로 다중 히스토그램 그룹화
이제 우리는 Seaborn 함수 FacetGrid()에 대해 이야기하고 있습니다. catplot, replot 및 displot의 중추입니다.
FacetGrid() 함수를 사용하여 플롯을 그룹화할 수 있으며 FacetGrid의 기본 아이디어는 작은 배수를 생성한다는 것입니다.
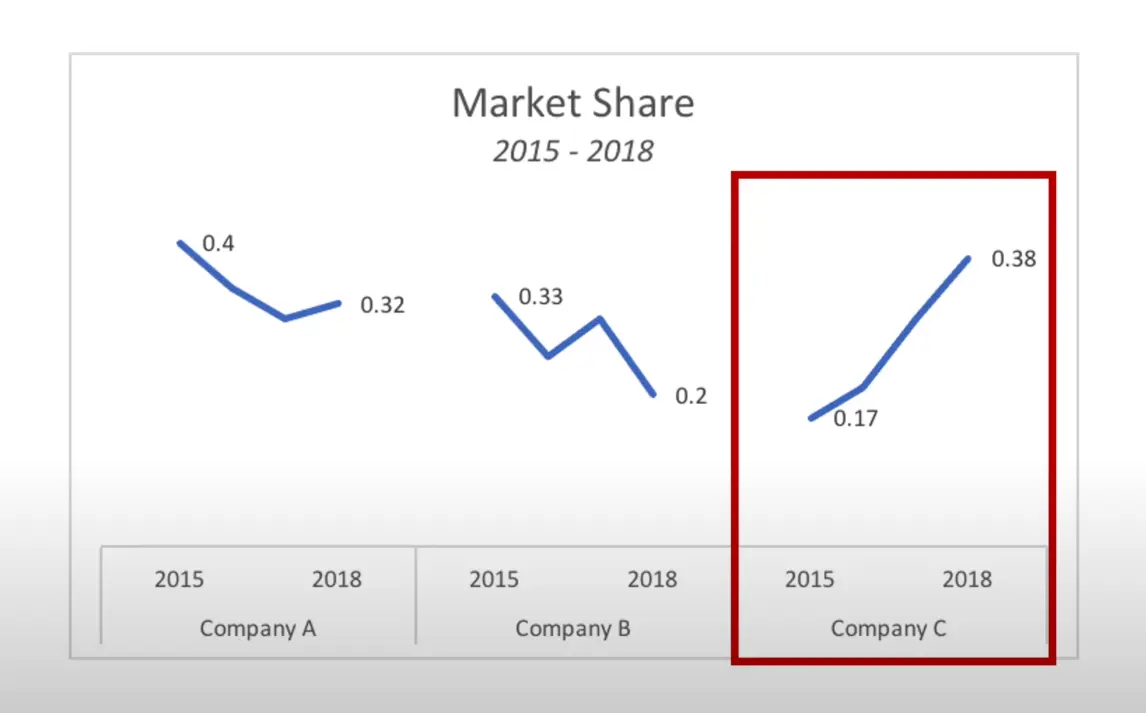
즉, 데이터에서 범주형 기능을 선택한 다음 모든 범주에 대해 하나의 플롯을 만들고 단 몇 줄의 코드로 이 모든 작업을 수행할 수 있습니다. 예를 들어 회사 A, B, C의 시장 점유율을 통해 다양한 범주의 추세를 비교할 수 있습니다.
코드 속으로 뛰어들어 봅시다. 위에서 살펴본 것처럼 펭귄에 대한 몇 가지 데이터를 살펴보겠습니다.
이제 FacetGrid를 생성합니다. 이를 위해 Seaborn 라이브러리를 참조한 다음 FacetGrid() 함수를 입력하고 penguins 데이터 프레임도 제공해야 합니다.
일부 데이터를 입력할 준비가 된 빈 x 및 y 축을 생성합니다. 행이나 열 차원 또는 둘 다를 제공할 수 있습니다.
이 열 차원을 제공하고 펭귄이 살고 있는 “섬"으로 작은 배수를 나누고 싶다고 가정해 보겠습니다.
sb.set_style("darkgrid")
sb.FacetGrid(PG_Data, col="island")
3개의 섬을 찾았기 때문에 각 섬에 대해 3개의 별도 하위 플롯을 만들었습니다.
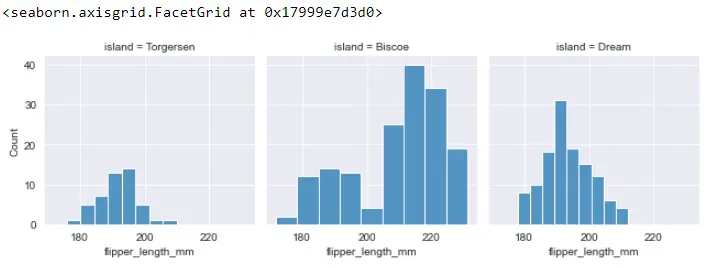
이제 FacetGrid를 설정했으므로 2단계로 이동하여 일부 플롯을 이러한 축에 매핑할 수 있습니다. 우리는 map() 함수를 호출하고 이 함수 내에서 생성하려는 그림을 제공해야 합니다.
각 그림에 대한 히스토그램 플롯을 생성하고 관심 있는 펭귄 데이터 프레임의 열을 정의해야 합니다. flipper_length_mm에 관심이 있습니다.
FG = sb.FacetGrid(PG_Data, col="island")
FG.map(sb.histplot, "flipper_length_mm")
각 섬별로 모든 데이터를 그룹화한 다음 각 그룹에 대한 히스토그램 플롯을 만듭니다. 우리는 단 몇 줄의 코드로 이러한 작은 배수를 모두 구축할 수 있습니다.
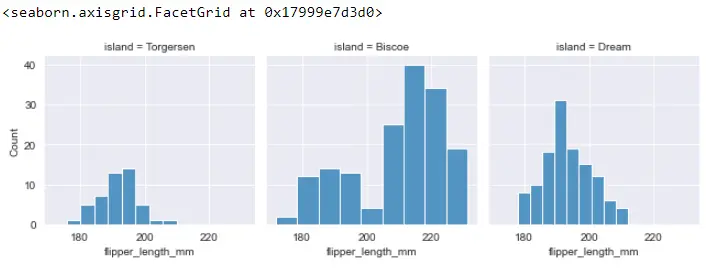
FG라는 FacetGrid 개체에는 map_dataframe이라는 또 다른 메서드가 있는데, 이는 약간 다르지만 지도와 비슷한 작업을 수행합니다.
FG = sb.FacetGrid(PG_Data, col="island")
FG.map_dataframe(sb.histplot, x="flipper_length_mm")
map() 함수와 같은 기능을 하지만 약간 다릅니다. 여기에서 큰 차이점 중 하나는 map_dataframe()이 가변 인수를 허용한다는 것입니다. 따라서 x가 flipper_length_mm와 같다고 정의하거나 y를 정의할 수 있습니다.
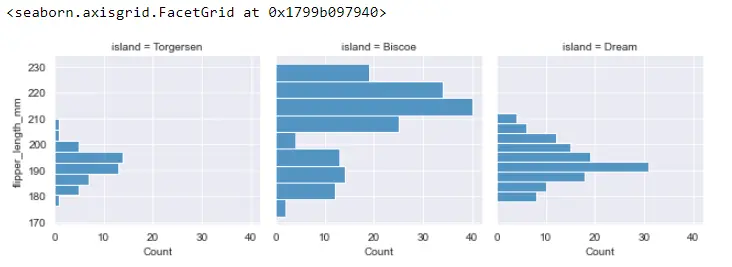
FG = sb.FacetGrid(PG_Data, col="island")
FG.map_dataframe(sb.histplot, y="flipper_length_mm")
수평 histplot을 플로팅합니다.
여기에서 histplot과 관련된 다른 내용을 읽어보세요.
전체 코드:
# In[1]:
import seaborn as sb
# In[2]:
sb.__version__
# In[3]:
PG_Data = sb.load_dataset("penguins")
# In[4]:
PG_Data.head()
# In[5]:
PG_Data.shape
# In[6]:
PG_Data.dropna(inplace=True)
# In[7]:
PG_Data.shape
# In[8]:
sb.set_style("whitegrid")
sb.histplot(PG_Data.bill_length_mm)
# In[9]:
sb.histplot(x="bill_length_mm", data=PG_Data)
# In[10]:
sb.histplot(y="bill_length_mm", data=PG_Data)
# In[11]:
sb.histplot(x="bill_length_mm", data=PG_Data, kde=True)
# In[12]:
sb.histplot(x="bill_length_mm", data=PG_Data, bins=30)
# In[13]:
sb.histplot(x="bill_length_mm", data=PG_Data, bins=[20, 40, 50, 55, 60, 65])
# In[14]:
sb.histplot(x="bill_length_mm", data=PG_Data, binwidth=10, binrange=(30, 60))
# ##### FacetGrid
# In[15]:
sb.set_style("darkgrid")
FG = sb.FacetGrid(PG_Data, col="island")
# In[16]:
FG = sb.FacetGrid(PG_Data, col="island")
FG.map(sb.histplot, "flipper_length_mm")
# In[17]:
FG = sb.FacetGrid(PG_Data, col="island")
FG.map_dataframe(sb.histplot, x="flipper_length_mm")
# In[18]:
FG = sb.FacetGrid(PG_Data, col="island")
FG.map_dataframe(sb.histplot, y="flipper_length_mm")

Hello! I am Salman Bin Mehmood(Baum), a software developer and I help organizations, address complex problems. My expertise lies within back-end, data science and machine learning. I am a lifelong learner, currently working on metaverse, and enrolled in a course building an AI application with python. I love solving problems and developing bug-free software for people. I write content related to python and hot Technologies.
LinkedIn