Python에서 PhantomJS 사용
이 Python 기사에서는 PhantomJS를 살펴보고 Python 프로그래밍을 위해 Selenium Web Automation Module과 함께 사용하는 방법을 살펴봅니다. 또한 자동화를 위해 사용 가능한 다른 웹 드라이버보다 더 유용한 이유도 살펴보겠습니다.
Selenium 및 PhantomJS는 유용하며 스크래핑 관점에서 고유한 이점을 제공합니다. 또한 전체 개념을 더 잘 이해하기 위해 몇 가지 실용적인 코딩 예제를 따라야 합니다.
PhantomJS 설치
PhantomJS는 Selenium 웹 자동화 모듈과 함께 작동하는 헤드리스 브라우저입니다. Firefox 드라이버 및 Chrome 드라이버와 달리 브라우저는 절차 내내 완전히 숨겨져 있습니다.
다른 브라우저와 똑같이 작동합니다. 웹 드라이버를 Chrome 드라이버 또는 Firefox 드라이버로 전환하여 절차를 설계하고 작동되면 PhantomJS로 전환할 수 있습니다.
PhantomJS는 GUI를 사용하지 않기 때문에 테스트 사례에 대한 일부 테스트 실행을 수행할 때 훨씬 빠르게 실행됩니다.
PhantomJS를 사용하기 전에 먼저 설치해야 합니다. macOS에 설치하려면 다음 명령을 실행합니다.
예제 코드:
brew install phantomjs
Windows 또는 Linux에 설치하려면 웹 사이트에서 다운로드해야 합니다. 여기에서 확인할 수 있습니다.
PhantomJS를 사용하여 해결한 문제 시나리오
여기에서 샘플 문제에 대해 논의한 다음 PhantomJS 및 Selenium으로 해결해 보겠습니다.
현대 컴퓨팅 시대에 오늘날 대부분의 웹사이트는 사이트에 콘텐츠를 동적으로 로드하기 위해 JavaScript를 사용합니다.
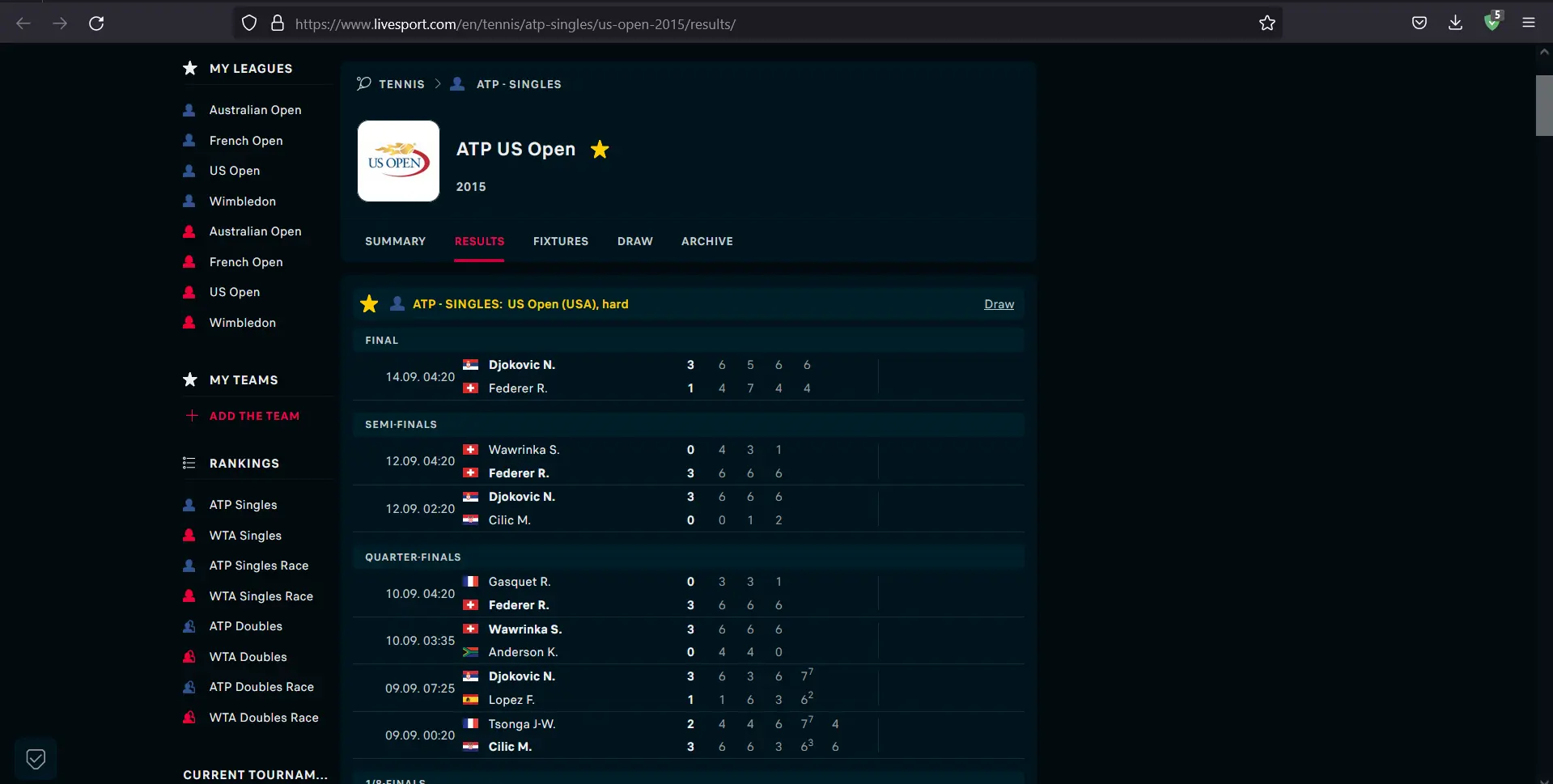
ATP Singles USA Tennis Results 2015를 로드하는 사이트를 고려해 보겠습니다. 사이트가 로드되면 포인트와 경기 세부 정보가 표시되는 것을 볼 수 있습니다.
JavaScript 덕분에 적절한 동적 방식으로 로드된 콘텐츠를 볼 수 있습니다. 이제 JavaScript를 비활성화하고 어떤 일이 발생하는지 살펴보겠습니다.

브라우저에서 JavaScript를 비활성화한 후 콘텐츠가 로드되지 않는 것을 볼 수 있습니다.
Python을 사용하여 해당 웹 사이트에서 모든 게임을 다운로드하려면 어떻게 해야 합니까? JavaScript가 렌더링되지 않으면 페이지 본문이 완료되지 않습니다. 따라서 사이트에 요청을 보내고 HTML을 구문 분석하는 기존 방법은 작동하지 않습니다.
PhantomJS 및 Selenium을 병렬로 사용
코드 작업을 시작하기 전에 먼저 환경을 설정해야 합니다. 이를 위해 다음 코드를 입력합니다.
mkdir scraping_phantomjs && cd scraping_phantomjs
virtualenv venv
source venv/bin/activate
pip install selenium beautifulsoup4
이제 필요한 설치 및 가져오기가 완료되었으므로 다음 단계로 이동하여 코드 실행이 끝날 때 얻을 데이터를 저장할 Python 파일을 만듭니다.
예제 코드:
touch scraper.py
파일이 생성되면 위에서 언급한 웹사이트에서 첫 번째 일치에 대한 HTML을 가져오는 스크립트 작성을 시작하겠습니다.
예제 코드:
import platform
from bs4 import BeautifulSoup
from selenium import webdriver
# Extensions may vary from OS to OS that is why we're considering multiple types
if platform.system() == "Windows":
PHANTOMJS_PATH = "./phantomjs.exe"
else:
PHANTOMJS_PATH = "./phantomjs"
# We are using pseudo browser PhantomJS here but can change it to Firefox as
# per our needs
browser = webdriver.PhantomJS(PHANTOMJS_PATH)
browser.get("http://www.scoreboard.com/en/tennis/atp-singles/us-open-2015/results/")
# Now we need to parse our HTML
soup = BeautifulSoup(browser.page_source, "html.parser")
# Find all the games listed
games = soup.find_all("tr", {"class": "stage-finished"})
# and print out the html for the first game
# You can print the next game by changing 0 to 1 in games[]
print(games[0].prettify())
이 스크립트가 작동하려면 PhantomJS의 위치를 지정해야 합니다. 위의 링크에서 운영 체제에 맞는 PhantomJS 버전을 다운로드했는지 확인하십시오.
그런 다음 압축을 풀면 bin 폴더에 phantomjs 파일이 나타납니다. 파일은 scraper.py 스크립트와 같은 폴더에 있어야 합니다.
필요한 출력을 얻는지 확인하기 위해 스크립트를 실행해 봅시다. 스크립트를 실행하려면 다음 명령을 입력하십시오.
예제 코드:
python scraper.py
출력은 첫 번째 일치에 대한 HTML을 제공합니다. 다음과 같이 보입니다.
<tr class="The odd no-border-bottom stage-finished" id="g_2_2DtOK9O8">
<td class="cell_ib icons left ">
</td>
<td class="cell_ad time ">
14.09. 02:20
</td>
<td class="cell_ab team-home bold ">
<span class="padl">
Djokovic N. (Srb)
</span>
</td>
<td class="cell_ac team-away ">
<span class="padl">
Federer R. (Sui)
</span>
</td>
<td class="cell_sa score bold ">
3 : 1
</td>
<td class="cell_ia icons ">
<span class="icons">
</span>
</td>
</tr>
우리가 본 것처럼 동적으로 로드된 콘텐츠를 가져오는 것은 단순히 서버에 요청을 보내는 것보다 상대적으로 쉽고 효율적입니다.
이 기사에서는 PhantomJS 및 Selenium을 사용하여 동적 웹 사이트에서 콘텐츠를 가져오는 방법을 간략하게 요약했습니다. 또한 해당 프로세스가 기존 방법보다 빠르고 효율적인 이유도 설명했습니다.

My name is Abid Ullah, and I am a software engineer. I love writing articles on programming, and my favorite topics are Python, PHP, JavaScript, and Linux. I tend to provide solutions to people in programming problems through my articles. I believe that I can bring a lot to you with my skills, experience, and qualification in technical writing.
LinkedIn