Pandas에서 특정 문자열을 포함하는 행 필터링
- 필수 라이브러리 설치
- Pandas DataFrame 만들기
-
str.contains()를 사용하여 특정 문자열을 포함하는 행 필터링 -
str.contains()를 사용하여 목록에 문자열이 포함된 행 필터링
Pandas 라이브러리는 숫자 외에도 텍스트 데이터를 처리하기 위한 완벽한 도구입니다. 많은 데이터 분석 애플리케이션 및 기계 학습 탐색/전처리에서 텍스트 입력을 제외하고 싶을 것입니다.
Python의 데이터 프레임은 Pandas 모듈에 있는 기본 데이터 구조입니다. 이러한 데이터 구조는 테이블 형식으로 데이터를 저장하고 처리하는 데 사용됩니다.
테이블 형식으로 저장된 데이터에 대해 수행되는 이러한 프로세스 중 하나는 관련 정보를 추출할 수 있도록 하위 문자열 기준으로 데이터 프레임을 필터링하는 것입니다. 이 문서에서는 동일한 작업을 수행하는 단계별 절차를 살펴봅니다.
필수 라이브러리 설치
Pandas 데이터 프레임 필터링을 시작하려면 먼저 Pandas 라이브러리를 설치해야 합니다. 선택한 터미널에서 다음 명령을 실행하여 이를 빠르게 달성할 수 있습니다.
pip install pandas
올바른 Python 버전으로 작업하는지 확인하는 것도 중요합니다. 이 문서에서는 버전 3.10.4를 사용하고 있습니다.
터미널에서 다음 명령을 실행하여 현재 설치된 Python 버전을 확인할 수 있습니다.
python --version
Pandas DataFrame 만들기
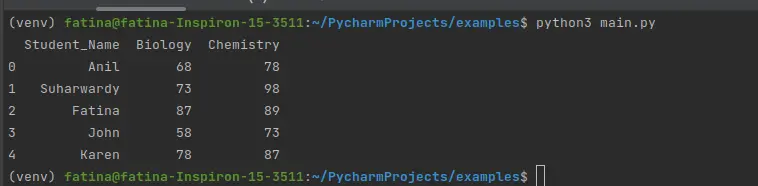
데이터 프레임 필터링 작업을 수행하려면 예제 데이터 프레임이 필요합니다. 따라서 아래 코드를 사용하여 기사의 데이터 프레임을 생성합니다. 100개 중 생물학과 화학의 두 과목에 대해 채점되는 5명의 학생 이름을 보여줍니다.
예제 코드:
import pandas as pd
data = {
"Student_Name": ["Anil", "Suharwardy", "Fatina", "John", "Karen"],
"Biology": [68, 73, 87, 58, 78],
"Chemistry": [78, 98, 89, 73, 87],
}
data_frame = pd.DataFrame(data)
print(data_frame)
따라서 위의 코드는 매우 간단합니다. Pandas 라이브러리를 가져온 다음 data 변수를 결과 데이터 프레임에 삽입하려는 정보가 포함된 사전으로 초기화합니다.
그런 다음 Pandas 모듈의 DataFrame() 메서드를 사용하여 위에서 언급한 기술에 data 사전을 전달하여 데이터 프레임을 생성합니다.
코드를 실행하면 다음 데이터 프레임이 생성됩니다.
출력:
str.contains()를 사용하여 특정 문자열을 포함하는 행 필터링
이제 데이터 프레임을 만들었으므로 필터링 단계로 넘어갈 수 있습니다. 학생 Suharwardy에 대한 데이터를 필터링한다고 가정해 보겠습니다. 결과는 Suharwardy에 대해 저장된 모든 정보여야 합니다.
str.contains() 메서드를 사용하여 이 작업을 수행할 수 있습니다. 아래 스니펫에서 Student_Name 데이터 프레임 열에 액세스했으며 str.contains() 메서드를 사용하여 Suharwardy라는 이름에 대해 저장된 정보에 액세스했습니다.
예제 코드:
import pandas as pd
data = {
"Student_Name": ["Anil", "Suharwardy", "Fatina", "John", "Karen"],
"Biology": [68, 73, 87, 58, 78],
"Chemistry": [78, 98, 89, 73, 87],
}
data_frame = pd.DataFrame(data=data)
df = data_frame[data_frame["Student_Name"].str.contains("Suharwardy")]
print(df)
출력:

이 작업을 수행하는 훨씬 더 간단하고 직관적인 방법은 점 연산자를 사용하여 Student_Name 열에 액세스하는 것입니다. 우리는 같은 결과를 얻습니다.
예제 코드:
import pandas as pd
data = {
"Student_Name": ["Anil", "Suharwardy", "Fatina", "John", "Karen"],
"Biology": [68, 73, 87, 58, 78],
"Chemistry": [78, 98, 89, 73, 87],
}
data_frame = pd.DataFrame(data=data)
df = data_frame[data_frame.Student_Name.str.contains("Suharwardy")]
print(df)
출력:

str.contains() 메서드에는 regex 매개 변수도 있으며 이를 False로 설정하여 더 빠른 결과를 얻는 데 사용할 수 있습니다.
예제 코드:
import pandas as pd
import regex as regex
data = {
"Student_Name": ["Anil", "Suharwardy", "Fatina", "John", "Karen"],
"Biology": [68, 73, 87, 58, 78],
"Chemistry": [78, 98, 89, 73, 87],
}
data_frame = pd.DataFrame(data=data)
df = data_frame[data_frame.Student_Name.str.contains("Suharwardy", regex=False)]
print(df)
출력:
이것이 str.contains() 메서드를 사용하여 Pandas 데이터 프레임을 필터링하고 추출하려는 정보의 세부 사항을 지정하는 방법입니다.
str.contains()를 사용하여 목록에 문자열이 포함된 행 필터링
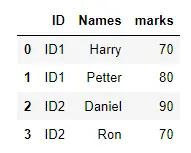
아래 코드는 ID 열에 ID1 또는 ID2가 포함된 데이터 프레임 행을 필터링하는 방법을 보여줍니다.
예제 코드:
import pandas as pd
d1 = {
"ID": [
"ID1",
"ID1",
"ID2",
"ID2",
"ID3",
"ID3",
],
"Names": ["Harry", "Petter", "Daniel", "Ron", "Sofia", "Kelvin"],
"marks": [70, 80, 90, 70, 60, 90],
}
df = pd.DataFrame(d1)
print(df)
s = df[df["ID"].str.contains("ID1|ID2")]
print("use of str.contains() : ")
print(s)
출력:

I am Fariba Laiq from Pakistan. An android app developer, technical content writer, and coding instructor. Writing has always been one of my passions. I love to learn, implement and convey my knowledge to others.
LinkedIn