MATLAB kstest() 함수
이 튜토리얼에서는 MATLAB의 kstest() 함수를 사용하여 데이터 세트가 표준 정규 분포에 속하는지 또는 표준 정규 분포에 속하지 않는지 확인하는 데 사용되는 데이터 세트에 대한 귀무 가설의 테스트 결정을 찾는 방법에 대해 설명합니다. .
Matlab kstest() 함수
Matlab에서 kstest() 함수는 데이터 세트가 표준 정규 분포에서 나온 것인지 아니면 표준 정규 분포에서 나오지 않았는지 확인하는 데 사용되는 데이터 세트에 대한 귀무 가설의 테스트 결정을 찾는 데 사용됩니다. 분포. kstest() 함수는 하나의 샘플 Kolmogorov Smirnov 알고리즘을 사용하여 테스트 결정을 찾습니다.
kstest() 함수의 기본 구문은 다음과 같습니다.
output = kstest(data)
위 구문의 출력은 0 또는 1이 될 수 있습니다. 출력이 0이면 함수는 귀무가설에 대한 검정 결정을 기각하지 않으며, 출력이 1이면 함수가 검정 결정을 기각했음을 의미합니다.
kstest() 함수의 테스트 결정을 확인하기 위한 시험 성적의 예를 논의해 봅시다. 표준정규분포와 경험적 누적분포를 하나의 플롯에 그려서 비교하고 테스트 결정을 확인할 수 있습니다.
아래 예제 코드 및 출력을 참조하십시오.
clc
clear
load examgrades
data = grades(:,1);
a = (data-75)/10;
testResult = kstest(a)
cdfplot(a)
hold on
x = linspace(min(a),max(a));
plot(x,normcdf(x,0,1),'r--')
legend('Empirical-CDF','Normal-CDF')
출력:
testResult =
logical
0
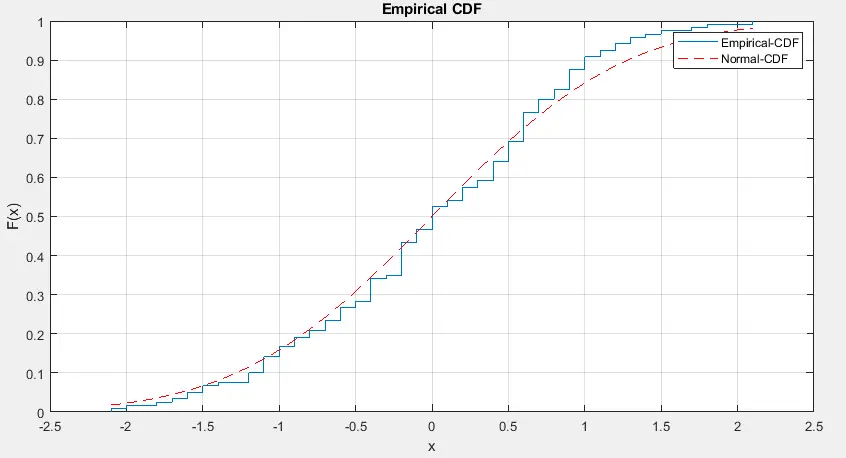
우리는 위의 코드에서 이미 Matlab에 있는 examgrades 데이터 세트를 사용했습니다. 평균 75, 표준편차 10을 사용하여 주어진 등급에서 데이터 집합을 만들고 kstest() 함수 내부에 전달했으며 테스트 결정 값으로 0을 반환했습니다. 귀무 가설의 검정 결정을 기각하지 않았습니다.
위의 출력 그림을 보면 두 분포가 서로 가깝다는 것을 알 수 있으며 이는 테스트 결정이 정확함을 확인합니다. cdfplot() 함수를 사용하여 데이터의 누적 분포 함수를 플로팅하고 normcdf() 함수를 사용하여 주어진 데이터의 정규 분포를 찾습니다.
쉽게 이해할 수 있도록 legend() 함수를 사용하여 플롯에 범례를 추가했습니다. 이제 위의 코드에서 평균을 75에서 85로 변경하고 결과를 확인해보자.
아래 예제 코드 및 출력을 참조하십시오.
clc
clear
load examgrades
data = grades(:,1);
a = (data-85)/10;
testResult = kstest(a)
cdfplot(a)
hold on
x = linspace(min(a),max(a));
plot(x,normcdf(x,0,1),'r--')
legend('Empirical-CDF','Normal-CDF')
출력:
testResult =
logical
1

위의 코드에서 kstest() 함수는 테스트 결정이 거부되었음을 의미하는 1을 반환했으며, 두 분포를 명확하게 보여주고 서로 같지 않은 위의 그림을 사용하여 확인할 수도 있습니다.
2열 행렬을 사용하여 테스트 결정을 찾는 동안 가설 분포를 지정할 수도 있습니다. 첫 번째 열에는 데이터가 포함되고 두 번째 열에는 누적 분포 값 또는 cdf가 포함됩니다.
또한 아래와 같이 CDF 인수를 사용하여 kstest() 함수에 알려야 합니다.
output = kstest(data,'CDF',cdfOfData)
위의 코드에서 cdfOfData는 첫 번째 열이 데이터이고 두 번째 열이 해당 데이터의 cdf인 2열 행렬입니다. Matlab의 cdf() 함수를 사용하여 cdf를 찾을 수 있습니다.
또한 makedist() 함수를 사용하여 만들 수 있는 확률 분포 개체를 사용하여 가설 분포를 지정할 수 있습니다. makedist() 기능에 대한 자세한 내용은 이 링크를 확인하십시오.
아래와 같이 CDF 인수를 사용하여 kstest() 함수 내부에 분포 개체를 전달해야 합니다.
output = kstest(data,'CDF',cdfObject)
또한 Alpha 인수를 사용하고 그 값을 0에서 1로 설정하여 다른 유의 수준에서 테스트 결정을 찾을 수 있습니다. kstest() 함수는 또한 새 인수인 p를 반환합니다. 테스트 결정.
Alpha 인수가 있는 kstest() 함수의 예는 다음과 같습니다.
[output, p] = kstest(data,'CDF',cdfObject, 'Alpha', 0.2)
또한 kstest() 함수가 대체 가설에 찬성하여 0 또는 1을 반환하는 Tail 인수를 사용하여 대체 가설을 사용하여 테스트 결정을 확인할 수 있습니다. Tail 인수의 값은 같지 않거나 크거나 작을 수 있습니다.
기본적으로 꼬리 인수의 값은 불일치로 설정됩니다. 즉, 모집단의 cdf와 가설 분포의 cdf가 같지 않음을 의미합니다. larger 값은 모집단의 cdf를 가설 분포의 cdf보다 크게 설정하고 작게 값은 모집단 cdf를 가설 cdf보다 작게 설정합니다.
Tail 인수가 있는 kstest() 함수의 예는 다음과 같습니다.
output = kstest(data, 'Tail', 'larger')
kstest() 함수는 아래 구문에 표시된 총 4개의 인수를 반환합니다.
[h,p,ksstat,cv] = kstest(data)
우리는 이미 kstest() 함수의 처음 두 인수에 대해 잘 알고 있습니다.
ksstat 인수에는 가설 테스트 통계의 음수가 아닌 스케일러 값이 포함됩니다. cv 인수는 음이 아닌 스칼라인 임계 값을 가집니다.
Matlab에는 두 샘플 Kolmogorov Smirnov 알고리즘을 사용하여 두 벡터의 결정을 테스트하는 데 사용되는 kstest2() 함수도 포함되어 있습니다.
kstest() 기능에 대한 자세한 내용은 이 링크를 확인하십시오.
