Python Pandas pandas.pivot_table() 함수
Minahil Noor
2023년1월30일
Pandas
Pandas Core
-
pandas.pivot_table()구문 -
예제 코드:
pandas.pivot_table() -
예제 코드: 여러 집계 함수를 지정하는
pandas.pivot_table() -
예제 코드:
margins매개 변수를 사용하는pandas.pivot_table()
Python Pandas pandas.pivot_table() 함수는DataFrame의 데이터 반복을 방지합니다. 데이터를 요약하고 데이터에 다른 집계 함수를 적용합니다.
pandas.pivot_table()구문
pandas.pivot_table(
data,
values=None,
index=None,
columns=None,
aggfunc="mean",
fill_value=None,
margins=False,
dropna=True,
margins_name="All",
observed=False,
)
매개 변수
이 기능에는 여러 매개 변수가 있습니다. 모든 매개 변수의 기본값은 위에 언급되어 있습니다.
data |
반복되는 데이터를 제거하려는 DataFrame입니다. |
values |
집계 할 열을 나타냅니다. |
index |
열, grouper, 배열 또는 목록입니다. 인덱스, 즉 행으로 원하는 데이터 열을 나타냅니다. |
columns |
열, grouper, 배열 또는 목록입니다. 출력 피벗 테이블에서 열로 원하는 데이터 열을 나타냅니다. |
aggfunc |
함수, 함수 목록 또는 사전입니다. 데이터에 적용될 집계 함수를 나타냅니다. 집계 함수 목록이 전달되면 맨 위에 열 이름이있는 결과 테이블의 각 집계 함수에 대한 열이 있습니다. |
fill_value |
스칼라입니다. 출력 테이블에서 누락 된 값을 대체 할 값을 나타냅니다. |
margins |
부울 값입니다. 각 행과 열을 합한 후 생성 된 행과 열을 나타냅니다. |
dropna |
부울 값입니다. 출력 테이블에서 값이 NaN인 열을 제거합니다. |
margins_name |
문자열입니다. margins값이 True인 경우 생성되는 행과 열의 이름을 나타냅니다. |
observed |
부울 값입니다. 그룹화가 범주 형이면이 매개 변수가 적용됩니다. True인 경우 범주 형 그룹화에 대해 관찰 된 값을 표시합니다. False인 경우 범주 형 그룹화에 대한 모든 값을 표시합니다. |
반환
요약 된 DataFrame을 반환합니다.
예제 코드: pandas.pivot_table()
이 기능을 구현하여 더 자세히 살펴 보겠습니다.
import pandas as pd
dataframe = pd.DataFrame({
"Name":
["Olivia",
"Olivia",
"Olivia",
"Olivia",
"Meghan",
"Meghan",
"Meghan",
"Meghan"],
"Date":
["03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019"],
"Science Marks":
[10,
2,
4,
6,
8,
9,
1,
10]
})
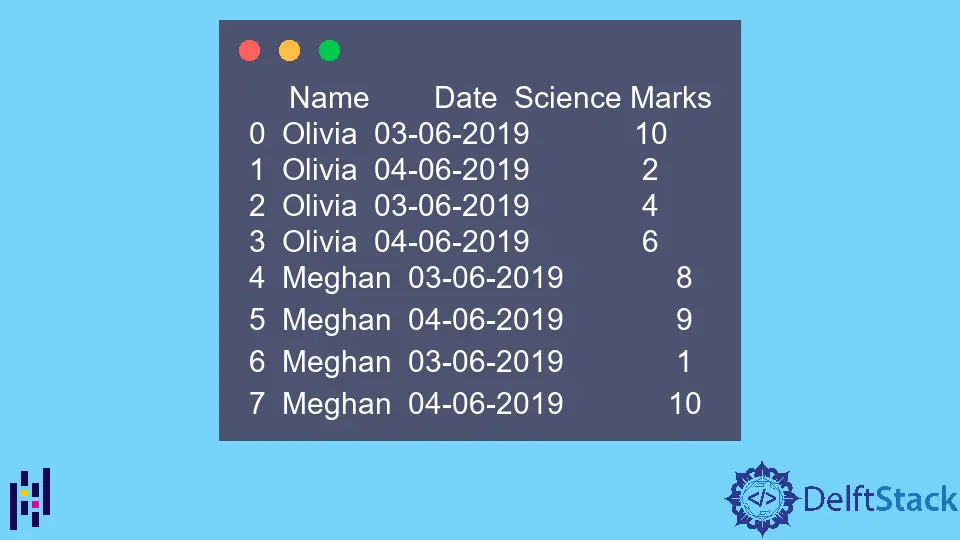
print(dataframe)
DataFrame의 예는 다음과 같습니다.
Name Date Science Marks
0 Olivia 03-06-2019 10
1 Olivia 04-06-2019 2
2 Olivia 03-06-2019 4
3 Olivia 04-06-2019 6
4 Meghan 03-06-2019 8
5 Meghan 04-06-2019 9
6 Meghan 03-06-2019 1
7 Meghan 04-06-2019 10
위의 데이터는 열에 동일한 값을 여러 번 포함합니다. 이pivot_table 함수는이 데이터를 요약합니다.
import pandas as pd
dataframe = pd.DataFrame(
{
"Name": [
"Olivia",
"Olivia",
"Olivia",
"Olivia",
"Meghan",
"Meghan",
"Meghan",
"Meghan",
],
"Date": [
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
],
"Science Marks": [10, 2, 4, 6, 8, 9, 1, 10],
}
)
pivotTable = pd.pivot_table(dataframe, index="Name", columns="Date")
print(pivotTable)
출력:
Science Marks
Date 03-06-2019 04-06-2019
Name
Meghan 4.5 9.5
Olivia 7.0 4.0
여기서는 Name열을 색인으로, Date를 열로 선택했습니다. 이 함수는 기본 매개 변수를 기반으로 결과를 생성했습니다. 기본 집계 함수 mean()이 값의 평균을 계산했습니다.
예제 코드: 여러 집계 함수를 지정하는pandas.pivot_table()
import pandas as pd
dataframe = pd.DataFrame(
{
"Name": [
"Olivia",
"Olivia",
"Olivia",
"Olivia",
"Meghan",
"Meghan",
"Meghan",
"Meghan",
],
"Date": [
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
],
"Science Marks": [10, 2, 4, 6, 8, 9, 1, 10],
}
)
pivotTable = pd.pivot_table(
dataframe, index="Name", columns="Date", aggfunc=["sum", "count"]
)
print(pivotTable)
출력:
sum count
Science Marks Science Marks
Date 03-06-2019 04-06-2019 03-06-2019 04-06-2019
Name
Meghan 9 19 2 2
Olivia 14 8 2 2
두 가지 집계 함수를 사용했습니다. 이러한 함수의 열은 별도로 생성됩니다.
예제 코드: margins 매개 변수를 사용하는pandas.pivot_table()
import pandas as pd
dataframe = pd.DataFrame(
{
"Name": [
"Olivia",
"Olivia",
"Olivia",
"Olivia",
"Meghan",
"Meghan",
"Meghan",
"Meghan",
],
"Date": [
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
],
"Science Marks": [10, 2, 4, 6, 8, 9, 1, 10],
}
)
pivotTable = pd.pivot_table(
dataframe, index="Name", columns="Date", aggfunc=["sum", "count"], margins=True
)
print(pivotTable)
출력:
sum count
Science Marks Science Marks
Date 03-06-2019 04-06-2019 All 03-06-2019 04-06-2019 All
Name
Meghan 9 19 28 2 2 4
Olivia 14 8 22 2 2 4
All 23 27 50 4 4 8
margins 매개 변수는All이라는 새 행과 행과 열의 합계를 각각 표시하는All이라는 새 열을 생성했습니다.
튜토리얼이 마음에 드시나요? DelftStack을 구독하세요 YouTube에서 저희가 더 많은 고품질 비디오 가이드를 제작할 수 있도록 지원해주세요. 구독하다