TensorFlow モデルの適合
TensorFlow ライブラリが提供する model.fit() メソッドは、機械学習の旅の時間を節約します。 通常、特定のモデルを構築する場合、トレーニング関数を設定する必要がありますが、これには多くの制約とコーディングの手間が必要です。
基本モデルのこれらの問題を軽減するには、model.fit() が非常に便利です。
反対に、model.fit() がトレーニング セッションを処理する場合、model.evaluate() は、トレーニングされたモデルに基づいてランダムな入力から期待される出力データを抽出します。 どちらの方法も、意思決定と価値の生成において避けられない役割を果たします。
次のセクションでは、Keras の Sequential() モデルに model.fit() メソッドを実装する方法を検討します。 デモンストレーションは基本的な概念を使用しており、ライブコードのデモもこの スレッド で提示されています。 さぁ、始めよう!
TensorFlow model.fit() を使用する
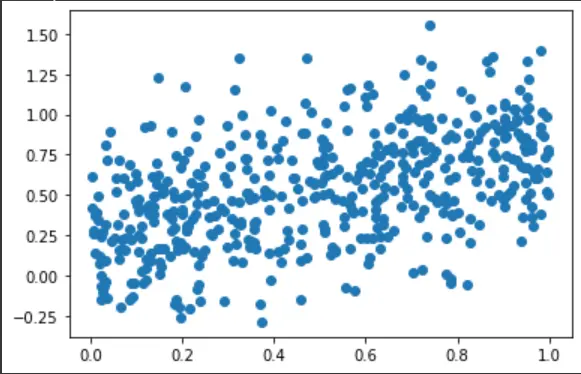
モデルのトレーニングとテストを開始するには、有効なデータセットが必要です。 この場合、独立した一連の値とそれに依存する値を持つデータセットを生成します。
後で、散布図を表示して、式が設定されたとおりに値をプロットできるかどうかを確認します。 このドライブのコードは次のとおりです。
# Necessary Imports
from tensorflow.keras import layers
import matplotlib.pyplot as plt
from tensorflow import keras
import tensorflow as tf
import numpy as np
import os
# Generating random data
x = np.random.uniform(0.0, 1.0, (500))
y = 0.3 + 0.5 * x + np.random.normal(0.0, 0.3, len(x))
plt.scatter(x, y)
出力:
モデルとその Dense レイヤーを開始します。 Dense レイヤーは、入力と期待される出力の次元を定義しました。
また、モデルに loss 関数と optimizer を設定します。 次のコードは単語を表しています。
model = (
keras.Sequential()
) # Sequential for 1D data correlating (as we only have x[independent] and y[dependent])
model.add(tf.keras.layers.Dense(1, input_shape=(1,)))
model.compile(loss="mse", optimizer="rmsprop")
TensorFlow model.fit() と model.evaluate() を使用する
model.fit() と model.evaluate() を調べて、トレーニングがあったかどうかを確認し、評価されたメソッド model.fit() の最後のエポック loss 関数と一致するかどうかを確認します 損失関数。 一致する場合、モデルは適切にトレーニングされたと言え、システムはこれらの制約に該当する値を識別できるようになりました。
ここでは、トレーニングで、batch_size (サンプル) を 500 データから 100 に設定します。 テストでは、バッチ サイズを 500 にしました。
システムは、より大きなエポック番号を持つこれらの 100 個のサンプルに関する情報を取得できた可能性があります。
print("train: ", model.fit(x, y, epochs=600, batch_size=100))
# The evaluate() method - gets the loss statistics
print("test: ", model.evaluate(x, y, batch_size=500))
出力:


