シーボーン カウント プロット
この記事では、Seaborn カウント プロットと、カウント プロットとバー プロットの違いについて説明します。 また、Seaborn の countplot() 関数で利用可能な Python オプションも見ていきます。
Seaborn で countplot() 関数を使用する
countplot() は、カテゴリごとの観測数をカウントし、その情報を棒グラフで表示する方法です。 これはヒストグラムと考えることができますが、カテゴリ データの場合、これは非常に単純なプロットであり、特に Python で探索的データ分析を行う場合に非常に役立ちます。
Seaborn ライブラリの countplot() 関数を調べてください。 まず、Seaborn ライブラリをインポートし、Seaborn ライブラリからダイヤモンドに関するデータを読み込みます。
import seaborn as sb
Data_DM = sb.load_dataset("diamonds")
Data_DM.head()
このデータ セットの各行には、1つの特定のダイヤモンドに関する情報が含まれています。

clarity.isin を使用して SI1 と VS2 に絞り込み、2つのオプションしかないカテゴリを作成します。
Data_DM = Data_DM[Data_DM.clarity.isin(["SI1", "VS2"])]
Data_DM.shape
すべてを絞り込むと、このデータセットには約 25323 個の異なるダイヤモンドが含まれています。
(25323, 10)
これで、最初のカウント プロットを作成する準備が整いました。 そのために、Seaborn ライブラリを参照し、countplot() 関数を呼び出して、プロットする列を渡します。
color 列をプロットします。これらのデータは Data_DM データフレームから取得されます。
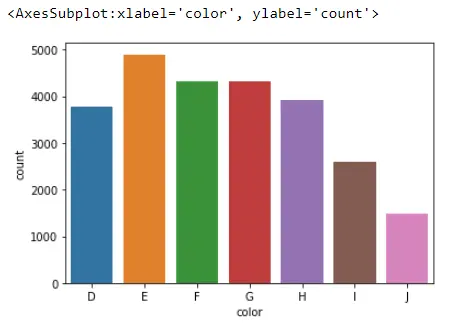
sb.countplot(x="color", data=Data_DM)
これがこのプロットで行うことは、color 列で見つかった各カテゴリの観測数をカウントすることです。 たとえば、Seaborn は J に等しい色のダイヤモンドを約 1500 個見つけました。
color 列に value_counts() を適用した場合:
Data_DM.color.value_counts(sort=False)
これらの数値は、countplot() 関数を使用するときにプロットするものです。
D 3780
E 4896
F 4332
G 4323
H 3918
I 2593
J 1481
Name: color, dtype: int64
Seaborn countplot() の良い点の 1つは、縦棒から横棒に簡単に切り替えられることです。 この x を y に切り替えるだけです。
sb.countplot(y="color", data=Data_DM)
出力:

Seaborn Barplot 対 Countplot
この時点で、Seaborn の countplot は barplot に非常に似ていると思うかもしれません。 しかし、大きな違いが 1つあります。Seaborn countplot では、カテゴリごとの観測数をカウントしているだけです。
Seaborn barplot を使用して、カテゴリごとの要約統計量の推定値を取得します。 たとえば、カテゴリごとの平均を取得し、そこから信頼区間を取得できます。 そのため、棒グラフが使用されます。
注文引数
それらは 2つの異なる目的で使用されます。 ただし、コーディング オプションは両方のプロットで使用できます。 これらのオプションのいくつかを Seaborn コードで確認してみましょう。
最初のオプションでは、上のプロットに表示されるバーの順序について話しましょう。 これらのダイヤモンドの色の countplot を見ると、バーは現在、最も人気のあるものから最も人気のないものに基づいて並べ替えられていないことがわかります。
D から J までアルファベット順に並んでいます。
sb.countplot(x="cut", data=Data_DM)
しかし、cut と呼ばれる別の列を見ると、バーがアルファベット順に配置されていないことがわかります。

Seaborn がこれらのバーをどのように配置しているかは、最初は明確ではありません。 プロセスをたどることができます。 diamonds 列のデータ型を見ると、いくつかの float64、int64、およびカテゴリがあることがわかります。
Data_DM.dtypes
これら 3つの列は、カテゴリ データ型と見なされます。 cut、color、clarity はすべてカテゴリです。
carat float64
cut category
color category
clarity category
depth float64
table float64
price int64
x float64
y float64
z float64
dtype: object
それが何を意味するか見てみましょう。 color をチェックするために、categories というプロパティがあります。
Data_DM.color.cat.categories
これは、Seaborn がバーを並べるために使用しているものです。
Index(['D', 'E', 'F', 'G', 'H', 'I', 'J'], dtype='object')
通常、category 列には categories と呼ばれるこのプロパティが付属しており、Seaborn はこれを使用してこれらのバーをどのように並べるかを決定します。
Data_DM.cut.cat.categories
出力:
Index(['Ideal', 'Premium', 'Very Good', 'Good', 'Fair'], dtype='object')
1つ目はアルファベット順に並んでいますが、2つ目は最初に最高のダイヤモンドに基づいて並べ、次に最悪のダイヤモンドまで並べています。
しかし、その category の順序が、これらのバーを表示したい方法と異なる場合はどうなるでしょうか? Seaborn の countplot() 関数には order という引数があり、これらのバーをどのように並べるかのリストを渡すことができます。
ord_of_c = ["J", "I", "H", "G", "F", "E", "D"]
sb.countplot(x="color", data=Data_DM, order=ord_of_c)
出力:

これは Pandas データフレームであるため、これらのバーを昇順または降順で並べ替えることもできるため、value_counts() メソッドを使用することをお勧めします。 これにより、バーが最も人気のあるものから最も人気のないものへと並べ替えられます。
先に進んでインデックスを取得すると、最も人気のあるカテゴリは E であり、最も人気のないカテゴリは J です。
Data_DM.color.value_counts().index
出力:
CategoricalIndex(['E', 'F', 'G', 'H', 'D', 'I', 'J'], categories=['D', 'E', 'F', 'G', 'H', 'I', 'J'], ordered=False, dtype='category')
バーの注文を作成するときに、この index を使用できます。 これで、これらが降順にソートされました。
しかし、それらを昇順でソートしたい場合。
必要なのは、このインデックスを逆にすることだけです。これには、2つのコロンと負のコロンを使用して、インデックスを完全に切り替えることができます。
sb.countplot(x="color", data=Data_DM, order=Data_DM.color.value_counts().index[::-1])
出力:

こちら にアクセスすると、その他のオプションを見つけることができます。
完全なコード:
# In[1]:
import seaborn as sb
Data_DM = sb.load_dataset("diamonds")
Data_DM.head()
# In[2]:
Data_DM = Data_DM[Data_DM.clarity.isin(["SI1", "VS2"])]
Data_DM.shape
# In[3]:
sb.countplot(x="color", data=Data_DM)
# In[4]:
Data_DM.color.value_counts(sort=False)
# In[5]:
sb.countplot(y="color", data=Data_DM)
# In[6]: order argument
sb.countplot(x="cut", data=Data_DM)
# In[7]:
Data_DM.dtypes
# In[8]:
Data_DM.color.cat.categories
# In[9]:
Data_DM.cut.cat.categories
# In[10]:
ord_of_c = ["J", "I", "H", "G", "F", "E", "D"]
sb.countplot(x="color", data=Data_DM, order=ord_of_c)
# In[11]:
Data_DM.color.value_counts().index
# In[12]:
sb.countplot(x="color", data=Data_DM, order=Data_DM.color.value_counts().index[::-1])

Hello! I am Salman Bin Mehmood(Baum), a software developer and I help organizations, address complex problems. My expertise lies within back-end, data science and machine learning. I am a lifelong learner, currently working on metaverse, and enrolled in a course building an AI application with python. I love solving problems and developing bug-free software for people. I write content related to python and hot Technologies.
LinkedIn