R でのデータの正規性のテスト
多くの統計テストまたは手法では、サンプルが正規分布に関連していると仮定しています。 一部のテストまたは手順では、サンプルが正規分布した母集団から抽出されたと仮定する場合があります。
他の人は、データのランダム誤差 (残差) が正規分布から引き出されたと仮定するかもしれません。 R は、データ (元のデータまたは残差) が正規分布に従うかどうかをテストする複数の方法を提供します。
この記事では、グループ化されていない単変量データの正規性をテストするための 3つの単純で一般的な手法について説明します。
コード例:
# First, we will create the data for our demonstrations.
# Large normal population.
set.seed(951)
p = rnorm(100000,100,5)
# Plot the population.
hist(p, breaks=100)
# Take a sample from the normal population.
set.seed(753)
s1 = sample(p, size=125, replace=FALSE)
# Create a non-normal sample.
# A vector (population).
v = c(31:81)
# Non-normal sample.
set.seed(159)
s2 = sample(v, 2000, replace=TRUE)
与えられた技術の適用性
以下のテクニックは、私たちが利用できるデータのためのものです。 それらは、データが許容できるほど正常かどうかを教えてくれます。
したがって、それらは利用可能なデータを結論付けるためにのみ使用されます。
特に、データ (サンプル) が取得された母集団を結論付けることはできません。 これらの結論は、サンプルを取得するために使用されるサンプリング手法に関連する統計理論に依存します。
データをプロットする
出発点として適切な定性的なアプローチから始めます。 単純なヒストグラムは、データが通常の曲線のような釣鐘型であるかどうかを示します。
コード例:
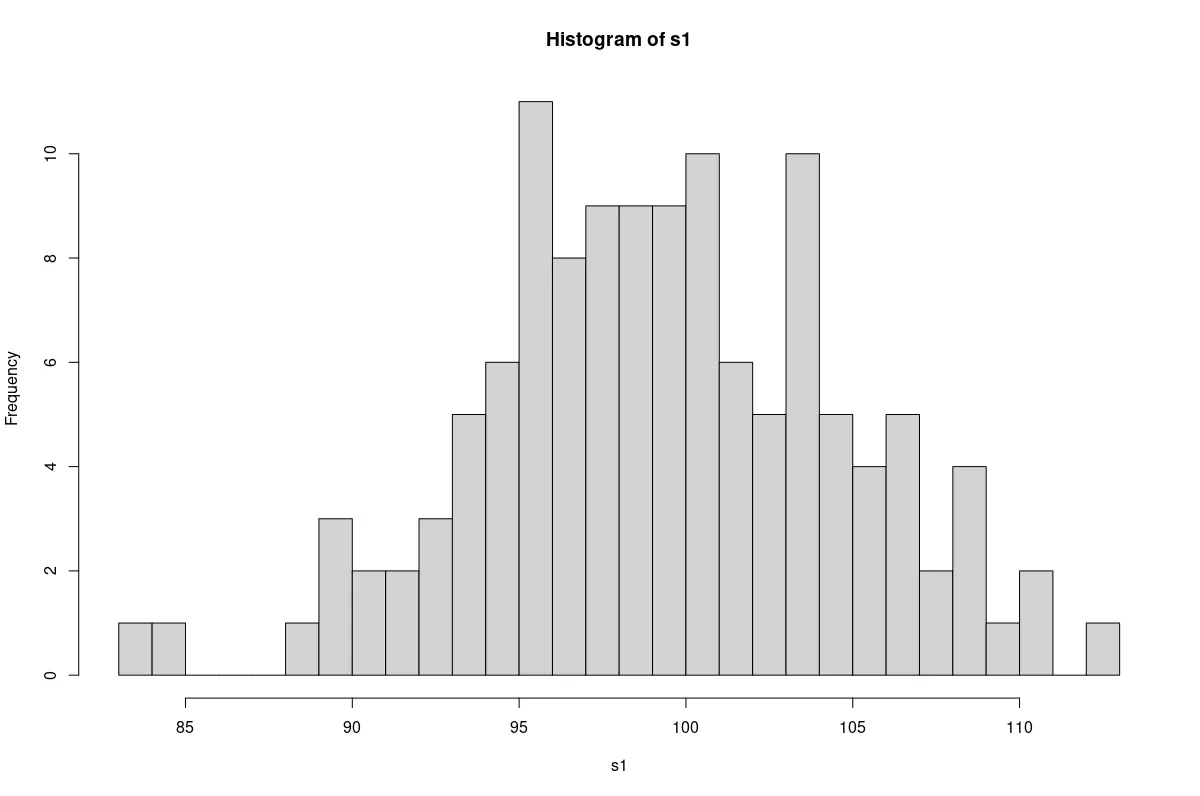
# Plot the sample from the normal population.
hist(s1, breaks=25)
# Plot the non-normal sample.
hist(s2, breaks=25)
正規母集団から抽出されたサンプルのプロット。
非正規サンプルのプロット。

正規母集団からのサンプルは、おおよそベル型であることがわかります。 非正規サンプルは長方形に似ています。
R で Shapiro-Wilk 正規性検定を使用する
データの正規性に対する Shapiro-Wilk 検定は、広く使用されている統計検定です。
shapiro.test() 関数は、3 ~ 5000 要素のデータ ベクトルを受け取ります。 より正確には、これは欠損していない要素の数に対するベクトルの範囲です。
このテストでは、データが正常であることを前提としています。 それが帰無仮説です。
W-statistic と p-value を返します。 1 に近い W-statistic は、分布がほぼ正規であることを意味します。
ただし、この解釈は、返される p-value と組み合わせる必要があります。
0.05 より大きい p 値 は、サンプルが正規分布しているという結論をサポートします。
コード例:
# Run the Shapiro-Wilk test on the samples.
# Sample from normal population.
shapiro.test(s1)
# Non-normal sample.
shapiro.test(s2)
出力:
> # Sample from normal population.
> shapiro.test(s1)
Shapiro-Wilk normality test
data: s1
W = 0.99353, p-value = 0.8383
> # Non-normal sample.
> shapiro.test(s2)
Shapiro-Wilk normality test
data: s2
W = 0.95117, p-value < 2.2e-16
正規母集団からのサンプルは、高い W-statistic と高い p-value を持っていることがわかります。 標本は正規分布に厳密に従います。
ただし、予想どおり、非正規サンプルの p 値 は非常に低くなっています。 サンプルが正規分布に従っていないことを確認します。
R の分位 - 分位プロット
Quantile-Quantile Plot (Q-Q プロットとも呼ばれます) は、正規性をテストするためのもう 1つの定性的手法です。
この検定では、サンプル データの分位数が、標準正規分布の対応する分位数に対してプロットされます。 分位数間に十分な線形相関がある場合、両方の分布は似ています。 サンプル データは正規分布に従います。
グラフィカルに、プロットがほぼ直線になる場合、サンプルがほぼ正常であるという結論を裏付けています。
qqnorm() 関数は、R で Q-Q プロットを作成します。
コード例:
# Plot the Q-Q plots for both the samples.
# Q-Q plot of sample from the normal population.
qqnorm(s1)
# Q-Q plot for the non-normal sample.
qqnorm(s2)
正規母集団からのサンプルのQ-Qプロット。 グラフはほぼ直線です。

非正規サンプルのQ-Qプロット。 プロットは曲線です。 サンプルは正常ではありませんでした。

まとめ
実際には、上記の 3つのアプローチはすべて補完的です。 サンプルサイズが非常に大きい場合、Shapiro-Wilk 検定は非常に低い p 値 を与えることがあります。
視覚的なテクニックは、正しい結論を導き出すのに役立ちます。

Jesse is passionate about data analysis and visualization. He uses the R statistical programming language for all aspects of his work.