Rのランダムフォレスト
ランダム フォレスト アプローチでは、多数の決定木が作成されます。 このチュートリアルでは、R でランダム フォレスト アプローチを適用する方法を示します。
Rのランダムフォレスト
ランダム フォレスト アプローチでは、多数の決定木が作成されます。 多くの観察結果がデシジョン ツリーに入力され、それらからの最も一般的な出力が最終出力として使用されます。
次に、新しい観測がすべての決定木に送信され、すべての分類モデルに対して多数決が取られます。 ツリーの構築中に使用されなかったケースについて、OOB (out-of-bag) エラーの推定が行われます。
iris データセットを使用して、それにランダム フォレスト アプローチを適用してみましょう。 R でランダム フォレストを実装するには、caTools と randomForest をインストールする必要があります。
install.packages("caTools")
install.packages("randomForest")
パッケージがインストールされたら、それらをロードしてランダム フォレスト アプローチを開始できます。 例を参照してください:
# Loading package
library(caTools)
library(randomForest)
# Split the data in train data and test data with ratio 0.8
split_data <- sample.split(iris, SplitRatio = 0.8)
split_data
train_data <- subset(iris, split == "TRUE")
test_data <- subset(iris, split == "FALSE")
# Fit the random Forest to the train dataset
set.seed(120) # Setting seed
classifier_Random_Forest = randomForest(x = train_data[-4],
y = train_data$Species,
ntree = 400)
classifier_Random_Forest
上記のコードは iris データを 0.8 の比率で分割し、トレーニング データとテスト データを作成します。 最後に、400 本の木でランダム フォレスト アプローチを適用します。 出力は次のとおりです。
Call:
randomForest(x = train_data[-4], y = train_data$Species, ntree = 400)
Type of random forest: classification
Number of trees: 400
No. of variables tried at each split: 2
OOB estimate of error rate: 0%
Confusion matrix:
setosa versicolor virginica class.error
setosa 30 0 0 0
versicolor 0 30 0 0
virginica 0 0 30 0
ランダム フォレスト モデルが適合したら、テスト セットの結果を予測し、混同行列を確認して、モデル グラフをプロットできます。 以下のコードを参照してください。
# Predict the Test set result
y_pred = predict(classifier_RF, newdata = test_data[-4])
# The Confusion Matrix
conf_matrix = table(test_data[, 4], y_pred)
conf_matrix
# Plot the random forest model
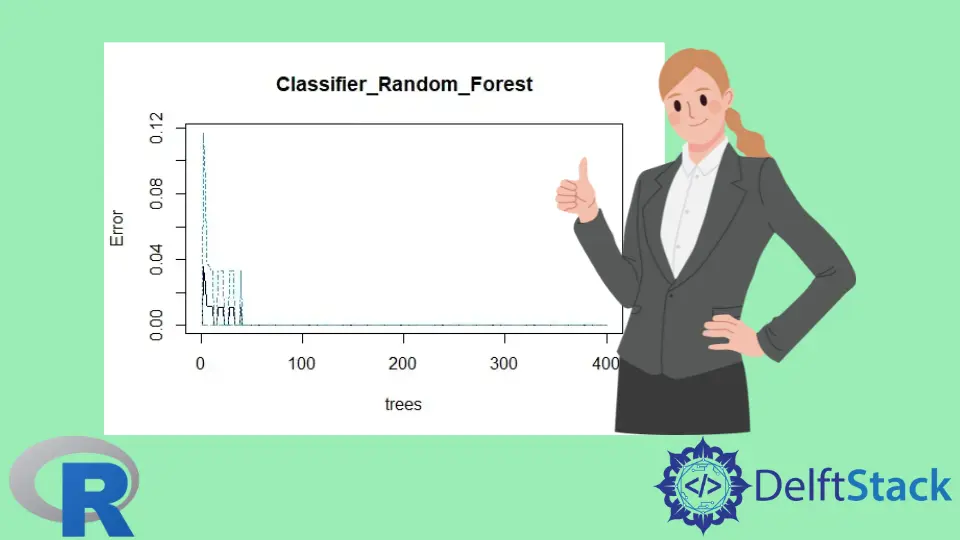
plot(classifier_Random_Forest)
# The importance plot
importance(classifier_Random_Forest)
# The Variable importance plot
varImpPlot(classifier_Random_Forest)
上記のコードは、テスト セットの結果を予測し、混同行列を表示します。 最後に、ランダム フォレスト モデル プロット、重要度、および 変数重要度 プロットを示します。
出力を参照してください:
> conf_matrix
y_pred
setosa versicolor virginica
0.1 1 0 0
0.2 10 0 0
0.3 3 0 0
0.4 4 0 0
0.5 1 0 0
0.6 1 0 0
1 0 2 0
1.1 0 1 0
1.2 0 1 0
1.3 0 5 0
1.4 0 3 0
1.5 0 6 1
1.6 0 1 1
1.7 0 1 0
1.8 0 2 4
1.9 0 0 3
2 0 0 3
2.1 0 0 1
2.3 0 0 4
2.4 0 0 1
ランダム フォレスト モデル プロット:

ランダム フォレスト モデルの重要性:
MeanDecreaseGini
Sepal.Length 6.1736467
Sepal.Width 0.9664428
Petal.Length 24.1454822
Species 28.0489838
Variable Importance プロット:


Sheeraz is a Doctorate fellow in Computer Science at Northwestern Polytechnical University, Xian, China. He has 7 years of Software Development experience in AI, Web, Database, and Desktop technologies. He writes tutorials in Java, PHP, Python, GoLang, R, etc., to help beginners learn the field of Computer Science.
LinkedIn Facebook