Python で PhantomJS を使用する
この Python の記事では、PhantomJS と、Python プログラミング用の Selenium Web Automation Module でそれを使用する方法について説明します。 また、自動化のために利用可能な他の Web ドライバーよりも便利な理由についても調べます。
Selenium と PhantomJS は便利で、スクレイピングの観点から独自の利点を提供します。 また、概念全体をよりよく理解するために、いくつかの実用的なコーディング例を以下に示します。
PhantomJS をインストールする
PhantomJS は、Selenium Web 自動化モジュールで動作するヘッドレス ブラウザーです。 Firefox ドライバーや Chrome ドライバーとは対照的に、ブラウザーは手順全体を通して完全に非表示のままです。
他のブラウザとまったく同じように動作します。 Web ドライバーを Chrome ドライバーまたは Firefox ドライバーに切り替えて手順を設計し、運用可能になったら PhantomJS に切り替えることができます。
PhantomJS は GUI の使用を排除するため、テスト ケースのいくつかのテスト ランを実行する場合にはるかに高速に実行されます。
PhantomJS を使用する前に、まずそれをインストールする必要があります。 macOS にインストールするには、次のコマンドを実行します。
コード例:
brew install phantomjs
Windows または Linux にインストールするには、Web サイトからダウンロードする必要があります。 こちらでご覧いただけます。
PhantomJS を使用して解決された問題のシナリオ
ここでサンプルの問題について説明し、PhantomJS と Selenium で解決してみましょう。
現代のコンピューティング時代では、現在、ほとんどの Web サイトが、サイトのコンテンツを動的にロードするために JavaScript を使用していることを知っています。
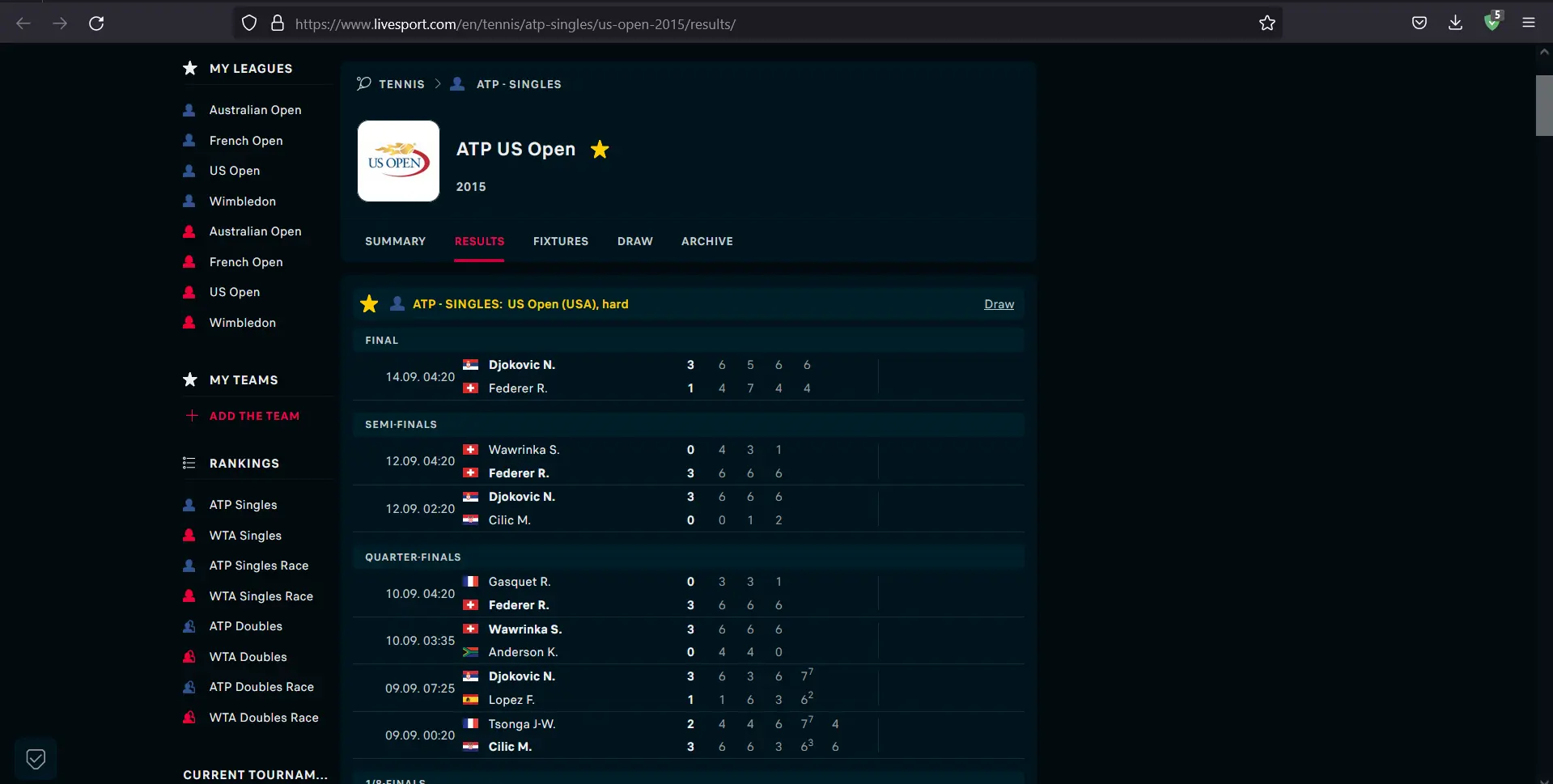
ATP Singles USA Tennis Results 2015 を読み込むサイトを考えてみましょう。 サイトが読み込まれると、ポイントと試合の詳細が表示されます。
JavaScript のおかげで、コンテンツが適切な動的な方法で読み込まれていることがわかります。 それでは、JavaScript を無効にして、何が起こるか見てみましょう。

ブラウザーから JavaScript を無効にした後、コンテンツが読み込まれていないことがわかります。
その Web サイトからすべてのゲームをダウンロードするために Python を使用したい場合はどうすればよいでしょうか? JavaScript がレンダリングされていない場合、ページの本文は未完成です。 したがって、リクエストをサイトに送信して HTML を解析する従来の方法は機能しません。
PhantomJS と Selenium を並行して使用する
コードの作業を開始する前に、まず環境を設定する必要があります。 このために、次のコードを入力します。
mkdir scraping_phantomjs && cd scraping_phantomjs
virtualenv venv
source venv/bin/activate
pip install selenium beautifulsoup4
必要なインストールとインポートが完了したので、次のステップに進み、コードの実行の最後までに取得するデータを保存することになっている Python ファイルを作成します。
コード例:
touch scraper.py
ファイルが作成されたら、上記の Web サイトで最初に一致した HTML を取得するスクリプトを書き始めましょう。
コード例:
import platform
from bs4 import BeautifulSoup
from selenium import webdriver
# Extensions may vary from OS to OS that is why we're considering multiple types
if platform.system() == "Windows":
PHANTOMJS_PATH = "./phantomjs.exe"
else:
PHANTOMJS_PATH = "./phantomjs"
# We are using pseudo browser PhantomJS here but can change it to Firefox as
# per our needs
browser = webdriver.PhantomJS(PHANTOMJS_PATH)
browser.get("http://www.scoreboard.com/en/tennis/atp-singles/us-open-2015/results/")
# Now we need to parse our HTML
soup = BeautifulSoup(browser.page_source, "html.parser")
# Find all the games listed
games = soup.find_all("tr", {"class": "stage-finished"})
# and print out the html for the first game
# You can print the next game by changing 0 to 1 in games[]
print(games[0].prettify())
このスクリプトが機能するには、PhantomJS の場所を指定する必要があります。 上記のリンクから、お使いのオペレーティング システムに適したバージョンの PhantomJS を入手してください。
その後、それを解凍して、bin フォルダー内の phantomjs ファイルを明らかにします。 このファイルは、scraper.py スクリプトと同じフォルダーにある必要があります。
スクリプトを実行して、必要な出力が得られるかどうかを確認してみましょう。 スクリプトを実行するには、次のコマンドを入力します。
コード例:
python scraper.py
出力は、最初の一致の HTML を提供します。 次のようになります。
<tr class="The odd no-border-bottom stage-finished" id="g_2_2DtOK9O8">
<td class="cell_ib icons left ">
</td>
<td class="cell_ad time ">
14.09. 02:20
</td>
<td class="cell_ab team-home bold ">
<span class="padl">
Djokovic N. (Srb)
</span>
</td>
<td class="cell_ac team-away ">
<span class="padl">
Federer R. (Sui)
</span>
</td>
<td class="cell_sa score bold ">
3 : 1
</td>
<td class="cell_ia icons ">
<span class="icons">
</span>
</td>
</tr>
これまで見てきたように、動的に読み込まれたコンテンツを取得することは、サーバーにリクエストを送信するよりも比較的簡単で効率的です。
この記事では、PhantomJS と Selenium を使用して動的 Web サイトからコンテンツを取得する方法を簡単にまとめました。 また、このプロセスが従来の方法よりも高速で効率的である理由についても説明しました。

My name is Abid Ullah, and I am a software engineer. I love writing articles on programming, and my favorite topics are Python, PHP, JavaScript, and Linux. I tend to provide solutions to people in programming problems through my articles. I believe that I can bring a lot to you with my skills, experience, and qualification in technical writing.
LinkedIn