NumPy と Python を使用して最急降下法を実装する
機械学習は最近のトレンドです。すべての企業やスタートアップは、機械学習を使用して現実の問題を解決するソリューションを考え出そうとしています。これらの問題を解決するために、プログラマーはいくつかの重要で価値のあるデータについてトレーニングされた機械学習モデルを構築します。モデルをトレーニングしている間、選択できる多くの戦術、アルゴリズム、および方法があります。動作するものと動作しないものがあります。
通常、Python はこれらのモデルのトレーニングに使用されます。Python は、機械学習の概念を簡単に実装できるようにする多数のライブラリをサポートしています。そのような概念の 1つは、最急降下法です。この記事では、Python を使用して最急降下法を実装する方法を学習します。
最急降下法
最急降下法は、機械学習モデルのトレーニング中に使用される凸関数ベースの最適化アルゴリズムです。このアルゴリズムは、問題をより効率的に解決するための最適なモデルパラメーターを見つけるのに役立ちます。一部のデータに対して機械学習モデルをトレーニングしている間、このアルゴリズムは各反復のモデルパラメータを微調整し、微分可能関数のグローバル最小値、場合によってはローカル最小値を最終的に生成します。
モデルパラメータを微調整している間、学習率と呼ばれる値によって、値を微調整する量が決まります。この値が大きすぎると、学習が速くなり、モデルに適合しなくなる可能性があります。また、この値が小さすぎると、学習が遅くなり、モデルをトレーニングデータに過剰適合させる可能性があります。したがって、バランスを維持し、最終的に優れた精度の優れた機械学習モデルを生成する値を考え出す必要があります。
Python を使用した最急降下法の実装
最急降下法の簡単な理論が完了したので、例を使用して NumPy モジュールと Python プログラミング言語を使用してそれを実装する方法を理解しましょう。
方程式 y = 0.5x + 2 の機械学習モデルをトレーニングします。これは y = mx + c または y = ax + b の形式です。基本的に、この方程式を使用して生成されたデータに対して機械学習モデルをトレーニングします。モデルは、m と c または a と b の値、つまり、それぞれ傾きと切片を推測します。機械学習モデルには、学習するデータと精度をテストするためのテストデータが必要なため、Python スクリプトを使用して同じものを生成します。このタスクを実行するために線形回帰を実行します。
トレーニング入力とテスト入力は次の形式になります。2 次元の NumPy 配列。この例では、入力は単一の整数値であり、出力は単一の整数値です。単一の入力は整数値と浮動小数点値の配列である可能性があるため、次の形式を使用して、コードの再利用性または動的な性質を促進します。
[[1], [2], [3], [4], [5], [6], [7], ...]
また、トレーニングラベルとテストラベルは次の形式になります。1 次元の NumPy 配列。
[1, 4, 9, 16, 25, 36, 49, ...]
Python コード
以下は、上記の例の実装です。
import random
import numpy as np
import matplotlib.pyplot as plt
def linear_regression(inputs, targets, epochs, learning_rate):
"""
A utility function to run linear regression and get weights and bias
"""
costs = [] # A list to store losses at each epoch
values_count = inputs.shape[1] # Number of values within a single input
size = inputs.shape[0] # Total number of inputs
weights = np.zeros((values_count, 1)) # Weights
bias = 0 # Bias
for epoch in range(epochs):
# Calculating the predicted values
predicted = np.dot(inputs, weights) + bias
loss = predicted - targets # Calculating the individual loss for all the inputs
d_weights = np.dot(inputs.T, loss) / (2 * size) # Calculating gradient
d_bias = np.sum(loss) / (2 * size) # Calculating gradient
weights = weights - (learning_rate * d_weights) # Updating the weights
bias = bias - (learning_rate * d_bias) # Updating the bias
cost = np.sqrt(
np.sum(loss ** 2) / (2 * size)
) # Root Mean Squared Error Loss or RMSE Loss
costs.append(cost) # Storing the cost
print(
f"Iteration: {epoch + 1} | Cost/Loss: {cost} | Weight: {weights} | Bias: {bias}"
)
return weights, bias, costs
def plot_test(inputs, targets, weights, bias):
"""
A utility function to test the weights
"""
predicted = np.dot(inputs, weights) + bias
predicted = predicted.astype(int)
plt.plot(
predicted,
[i for i in range(len(predicted))],
color=np.random.random(3),
label="Predictions",
linestyle="None",
marker="x",
)
plt.plot(
targets,
[i for i in range(len(targets))],
color=np.random.random(3),
label="Targets",
linestyle="None",
marker="o",
)
plt.xlabel("Indexes")
plt.ylabel("Values")
plt.title("Predictions VS Targets")
plt.legend()
plt.show()
def rmse(inputs, targets, weights, bias):
"""
A utility function to calculate RMSE or Root Mean Squared Error
"""
predicted = np.dot(inputs, weights) + bias
mse = np.sum((predicted - targets) ** 2) / (2 * inputs.shape[0])
return np.sqrt(mse)
def generate_data(m, n, a, b):
"""
A function to generate training data, training labels, testing data, and testing inputs
"""
x, y, tx, ty = [], [], [], []
for i in range(1, m + 1):
x.append([float(i)])
y.append([float(i) * a + b])
for i in range(n):
tx.append([float(random.randint(1000, 100000))])
ty.append([tx[-1][0] * a + b])
return np.array(x), np.array(y), np.array(tx), np.array(ty)
learning_rate = 0.0001 # Learning rate
epochs = 200000 # Number of epochs
a = 0.5 # y = ax + b
b = 2.0 # y = ax + b
inputs, targets, train_inputs, train_targets = generate_data(300, 50, a, b)
weights, bias, costs = linear_regression(
inputs, targets, epochs, learning_rate
) # Linear Regression
indexes = [i for i in range(1, epochs + 1)]
plot_test(train_inputs, train_targets, weights, bias) # Testing
print(f"Weights: {[x[0] for x in weights]}")
print(f"Bias: {bias}")
print(
f"RMSE on training data: {rmse(inputs, targets, weights, bias)}"
) # RMSE on training data
print(
f"RMSE on testing data: {rmse(train_inputs, train_targets, weights, bias)}"
) # RMSE on testing data
plt.plot(indexes, costs)
plt.xlabel("Epochs")
plt.ylabel("Overall Cost/Loss")
plt.title(f"Calculated loss over {epochs} epochs")
plt.show()
Python コードの簡単な説明
このコードには、次のメソッドが実装されています。
linear_regression(inputs, targets, epochs, learning_rate):この関数は、データに対して線形回帰を実行し、各エポックのモデルの重み、モデルのバイアス、および中間のコストまたは損失を返します。plot_test(inputs, targets, weights, bias):この関数は、入力、ターゲット、重み、およびバイアスを受け入れ、入力の出力を予測します。次に、グラフをプロットして、実際の値からモデルの予測がどれだけ近かったかを示します。rmse(inputs, targets, weights, bias):この関数は、一部の入力、重み、バイアス、およびターゲットまたはラベルの二乗平均平方根誤差を計算して返します。generate_data(m, n, a, b):この関数は、方程式y = ax + bを使用してトレーニングされる機械学習モデルのサンプルデータを生成します。トレーニングおよびテストデータを生成します。mとnは、それぞれ生成されたトレーニングサンプルとテストサンプルの数を示します。
上記のコードの実行フローは次のとおりです。
-
generate_data()メソッドは、いくつかのサンプルトレーニング入力、トレーニングラベル、テスト入力、およびテストラベルを生成するために呼び出されます。 -
学習率やエポック数など、一部の定数が初期化されます。
-
linear_regression()メソッドは、生成されたトレーニングデータに対して線形回帰を実行するために呼び出され、各エポックで検出された重み、バイアス、およびコストが保存されます。 -
生成されたテストデータを使用してモデルの重みとバイアスがテストされ、予測が真の値にどれだけ近いかを示すプロットが描画されます。
-
トレーニングおよびテストデータの RMSE 損失が計算され、出力されます。
-
各エポックで見つかったコストは、
Matplotlibモジュール(Python 用のグラフプロットライブラリ)を使用してプロットされます。
出力
Python コードは、エポックまたは反復ごとにモデルトレーニングステータスをコンソールに出力します。以下のようになります。
...
Iteration: 199987 | Cost/Loss: 0.05856315870190882 | Weight: [[0.5008289]] | Bias: 1.8339454694938624
Iteration: 199988 | Cost/Loss: 0.05856243033468181 | Weight: [[0.50082889]] | Bias: 1.8339475347628937
Iteration: 199989 | Cost/Loss: 0.05856170197651294 | Weight: [[0.50082888]] | Bias: 1.8339496000062387
Iteration: 199990 | Cost/Loss: 0.058560973627402625 | Weight: [[0.50082887]] | Bias: 1.8339516652238976
Iteration: 199991 | Cost/Loss: 0.05856024528735169 | Weight: [[0.50082886]] | Bias: 1.8339537304158708
Iteration: 199992 | Cost/Loss: 0.05855951695635694 | Weight: [[0.50082885]] | Bias: 1.8339557955821586
Iteration: 199993 | Cost/Loss: 0.05855878863442534 | Weight: [[0.50082884]] | Bias: 1.8339578607227613
Iteration: 199994 | Cost/Loss: 0.05855806032154768 | Weight: [[0.50082883]] | Bias: 1.8339599258376793
...
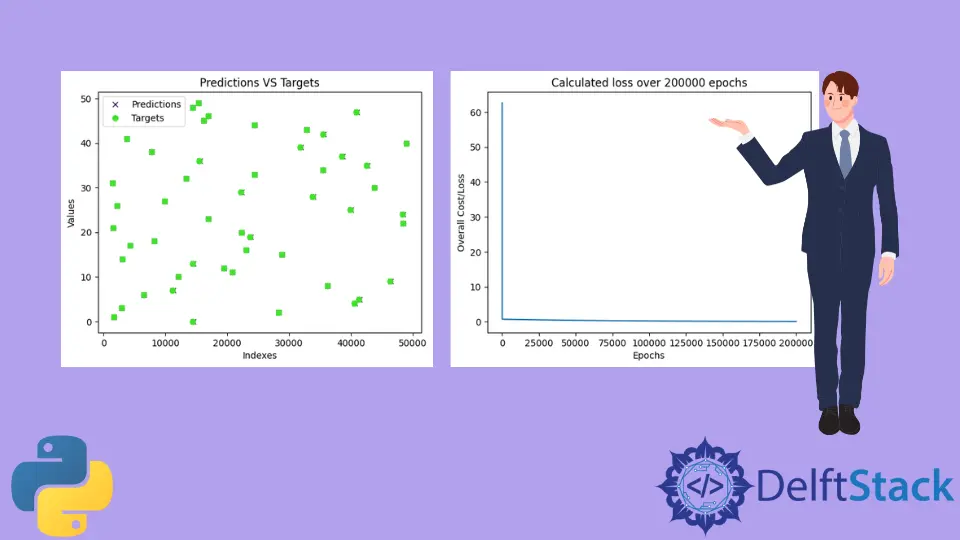
モデルがトレーニングされると、プログラムはモデルをテストし、モデルの予測と真の値を使用してプロットを描画します。トレーニングされたプロットは、以下に示すもののようになります。テストデータは random モジュールを使用して生成されるため、ランダムな値がその場で生成されることに注意してください。したがって、以下に示すグラフは、実際のグラフとは異なる可能性があります。

ご覧のとおり、予測はすべての真の値とほぼ重複しています(予測は x で表され、ターゲットは o で表されます)。これは、モデルが a と b または m と c の値をほぼ正常に予測したことを意味します。
次に、プログラムはモデルのトレーニング中に見つかったすべての損失を出力します。

ご覧のとおり、損失は 60 付近から 0 に近づき、すぐに減少し、残りのエポックの間はその状態を維持し続けました。
最後に、トレーニングおよびテストデータの RMSE 損失と、a および b の予測値またはモデルパラメーターが出力されました。
Weights: [0.5008287639956263]
Bias: 1.8339723159878247
RMSE on training data: 0.05855296238504223
RMSE on testing data: 30.609530314187527
この例で使用した式は、y = 0.5x + 2 でした。ここで、a = 0.5 および b = 2 です。そして、モデルは a = 0.50082 と b = 1.83397 を予測しましたが、これらは真の値に非常に近いものです。そのため、私たちの予測は真の目標と重複していました。
この例では、エポック数を 200000 に設定し、学習率を 0.0001 に設定します。幸い、これは非常に優れた、ほぼ完璧な結果をもたらした構成の 1 セットにすぎません。この記事の読者は、これらの値を試して、さらに良い結果が得られる値のセットを考え出すことができるかどうかを確認することを強くお勧めします。

Vaibhav is an artificial intelligence and cloud computing stan. He likes to build end-to-end full-stack web and mobile applications. Besides computer science and technology, he loves playing cricket and badminton, going on bike rides, and doodling.