グループ内で Pandas DataFrame をランク付けする
この記事では、昇順および降順でデータをランク付けする方法について説明します。 Pandas の groupby() 関数を使用して、データのグループをランク付けする方法も学習します。
rank() 関数を使用して Python で Pandas DataFrame をランク付けする
ランキングは、データを操作するときや、たとえば利益がランキングに基づいて高いか低いかを判断しようとするときの一般的な手順です。 時間管理は、トップ 10 製品またはボトム 10 製品が何であるかを知ることに関心がある場合もあります。
Pandas では、データのランク付けは、シリーズの要素をその値に従ってランク付けまたはソートする操作です。 rank 操作は、SQL ROW_NUMBER に着想を得ています。または、ROW_NUMBER 操作から期待できるほとんどの結果は、Pandas の rank 操作から期待できます。
例を見るためにコードを書くことから始めましょう。
スーパーストアのデータセットを読み込み、データから月と年を抽出しました。 そして、月と年の売上高のピボット テーブルを作成しました。
import numpy as np
import pandas as pd
import datetime
Store_Data = pd.read_excel("demo_Data.xls")
Store_Data["OrderDateMonth"] = Store_Data["Order Date"].apply(lambda x: x.month)
Store_Data["OrderDateYear"] = Store_Data["Order Date"].apply(lambda x: x.year)
Mon_Year_Sales = pd.pivot_table(
Store_Data,
index=["OrderDateMonth"],
columns=["OrderDateYear"],
aggfunc="sum",
values="Sales",
)
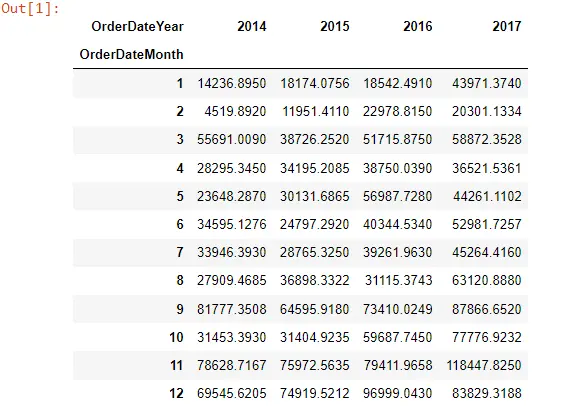
Mon_Year_Sales
したがって、ピボット テーブルを調べると、次のようになります。
昇順および降順で DataFrame をランク付けする
ここで、値に基づいてこのデータをランク付けする必要があります。 Pandas ライブラリには rank() 関数があり、オプションでパラメーター ascending を取り、デフォルトでデータを昇順に並べ替えます。
rank() 関数にはいくつかの引数があり、shift+tab+tab を押すと表示されます。 すべての引数と定義が表示されます。
![]()
Mon_Year_Sales にランク付けを適用して実行すると、これらの列がすべて取得され、数値形式が何であれ数値に変換され、昇順でランク付けされます。
Mon_Year_Sales.rank()
![]()
ランクは、指定された値を使用して計算されます。
2014 年の 2 行目では、このデータが 1 位です。 ascending 引数に値を渡していないため、昇順で並べられています。
ascending 引数 False を渡すと、値の降順でシーケンスが並べ替えられます。
Mon_Year_Sales.rank(ascending=False)
さて、2014 年は 9 か月目の売上額が最も高いため、1 位になりました。
![]()
groupby() メソッドを使用して、Pandas のグループに基づいてデータをランク付けします
全体ではなく、値のグループに基づいてデータをランク付けする特定の要件があります。 データが次のようになっているとします。
![]()
全体のランキングではなく、Profit 値のカテゴリ間でランク付けしたいとします。
Group_Data = (
Store_Data.groupby(["OrderDateYear", "Category"])
.agg({"Profit": "sum"})
.reset_index()
)
Group_Data
![]()
特定の年について、カテゴリの利益をランク付けしたいので、2014 年の場合、2 番目の値が 2014 年の最大値であるため、1 番目のランクになるようにします。
同様に、2015 年については、全体的に継続的に進むのではなく、1、2、および 3 から再び開始するような別のランキングが必要です。 次に、どのカテゴリが最高ランクであるかを知りたいのですが、どうすればそれを達成できますか?
目標を達成するために、年ごとにグループ化し、profit を選択し、ascending 引数を False に設定します。これは、トップ ランクを最大値にすることを意味します。 次に、method 引数を dense に設定します。
Group_Data["Rank_groupby"] = Group_Data.groupby("OrderDateYear")["Profit"].rank(
ascending=False, method="dense"
)
Group_Data
実行後、Office Supplies が 1 位になり、他のグループ レベルが特定の年ごとに 1、2、および 3 と再び開始したことがわかります。
![]()
完全なコード例:
# In[1]:
import numpy as np
import pandas as pd
import datetime
Store_Data = pd.read_excel("demo_Data.xls")
Store_Data["OrderDateMonth"] = Store_Data["Order Date"].apply(lambda x: x.month)
Store_Data["OrderDateYear"] = Store_Data["Order Date"].apply(lambda x: x.year)
Mon_Year_Sales = pd.pivot_table(
Store_Data,
index=["OrderDateMonth"],
columns=["OrderDateYear"],
aggfunc="sum",
values="Sales",
)
Mon_Year_Sales
# In[2]:
Mon_Year_Sales.rank()
# In[3]:
Mon_Year_Sales.rank(ascending=False)
# In[4]:
Store_Data.head(2)
# In[5]:
Group_Data = (
Store_Data.groupby(["OrderDateYear", "Category"])
.agg({"Profit": "sum"})
.reset_index()
)
Group_Data
# In[6]:
Group_Data["Rank_groupby"] = Group_Data.groupby("OrderDateYear")["Profit"].rank(
ascending=False, method="dense"
)
Group_Data
ここから関連する回答をさらに読んでください。

Hello! I am Salman Bin Mehmood(Baum), a software developer and I help organizations, address complex problems. My expertise lies within back-end, data science and machine learning. I am a lifelong learner, currently working on metaverse, and enrolled in a course building an AI application with python. I love solving problems and developing bug-free software for people. I write content related to python and hot Technologies.
LinkedIn