Pandas DataFrame で If-Else 条件を適用する
-
DataFrame.loc[]を使用して、Python の Pandas DataFrame にif-else条件を適用する -
DataFrame.apply()を使用して、Python の Pandas DataFrame でif-else条件を適用する -
NumPy.select()を使用して、Python の Pandas DataFrame にif-else条件を適用する -
apply()でlambdaを使用して、Python の Pandas DataFrame でif-else条件を適用する
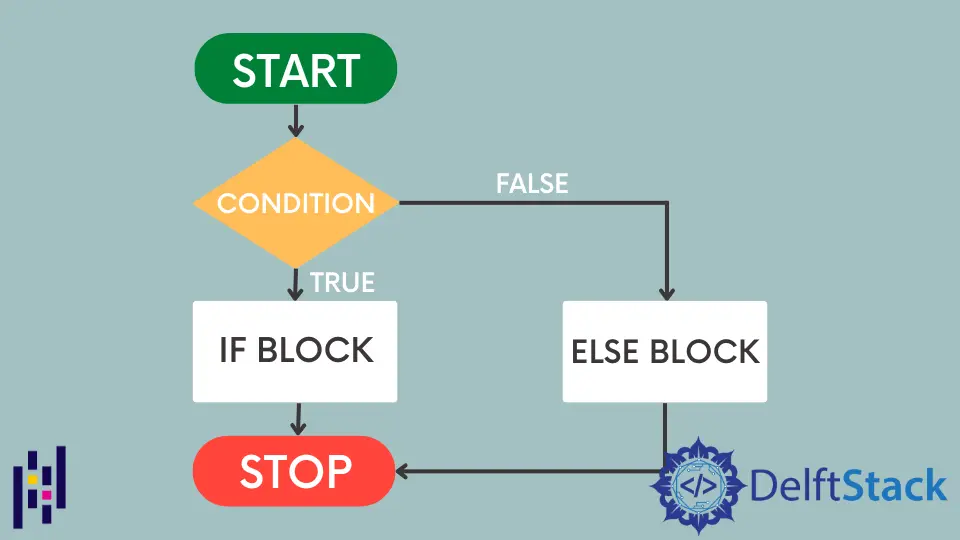
Pandas は、Python のオープンソース データ分析ライブラリです。 数値データに対して操作を実行するための組み込みメソッドが多数用意されています。
場合によっては、Pandas データフレームに if-else 条件を適用して、レコードをフィルタリングしたり、いくつかの条件に従って計算を実行したりしたいことがあります。 Python は、Pandas データフレームで if-else を使用する多くの方法を提供します。
DataFrame.loc[] を使用して、Python の Pandas DataFrame に if-else 条件を適用する
[loc[]] は、行または列のグループを選択またはフィルタリングするために使用される Pandas データ フレームのプロパティです。 次の例では、このプロパティを使用して、特定の条件を満たすレコードをフィルター処理します。
ここには、生徒のデータで構成される Pandas データ フレームがあります。 loc[] を使用すると、一度に 1つの条件しか適用できません。
最初の条件で 60 以上の点数を持つ学生をフィルタリングし、その結果を新しい列 Result に Pass として割り当てます。 同様に、別の条件で残りの生徒の結果に Fail を設定します。
コード例:
# Python 3.x
import pandas as pd
df = pd.DataFrame(
{"Name": ["Robert", "Sam", "Alia", "Jhon", "Smith"], "Marks": [60, 41, 79, 51, 88]}
)
display(df)
df.loc[df["Marks"] >= 60, "Result"] = "Pass"
df.loc[df["Marks"] < 60, "Result"] = "Fail"
display(df)
出力:

DataFrame.apply() を使用して、Python の Pandas DataFrame で if-else 条件を適用する
apply() メソッド は、データ フレームの軸 (行または列) を使用して関数を適用します。 if-else 条件で構成される定義済み関数を作成し、それを Pandas データフレームに適用できます。
ここでは、関数 assign_Result() を定義し、それを Marks 列に適用しました。 この関数は、Marks に基づいて結果を割り当て、すべての列行に対してこれを呼び出す if-else 条件で構成されます。
コード例:
# Python 3.x
import pandas as pd
df = pd.DataFrame(
{"Name": ["Robert", "Sam", "Alia", "Jhon", "Smith"], "Marks": [60, 41, 79, 51, 88]}
)
display(df)
def assign_Result(marks):
if marks >= 60:
result = "Pass"
else:
result = "Fail"
return result
df["Result"] = df["Marks"].apply(assign_Result)
display(df)
出力:
---output.webp)
NumPy.select() を使用して、Python の Pandas DataFrame に if-else 条件を適用する
条件がTrueの場合、リスト内の列と別のリスト内の対応する値に対して複数の条件を定義できます。 select() メソッドは、条件のリストとそれに対応する値のリストを引数として受け取り、それらを Result 列に割り当てます。
コード例:
# Python 3.x
import pandas as pd
import numpy as np
df = pd.DataFrame(
{"Name": ["Robert", "Sam", "Alia", "Jhon", "Smith"], "Marks": [60, 41, 79, 51, 88]}
)
display(df)
conditions = [(df["Marks"] >= 60), (df["Marks"] < 60)]
result = ["Pass", "Fail"]
df["Result"] = np.select(conditions, result)
display(df)
出力:
---output.webp)
apply() で lambda を使用して、Python の Pandas DataFrame で if-else 条件を適用する
lambda は、単一の式で構成される小さな無名関数です。 Marks 列の apply() で lambda を使用します。
x には、lambda 式のマークが含まれています。 if-else 条件を x に適用し、それに応じて結果を Result 列に割り当てました。
コード例:
# Python 3.x
import pandas as pd
import numpy as np
df = pd.DataFrame(
{"Name": ["Robert", "Sam", "Alia", "Jhon", "Smith"], "Marks": [60, 41, 79, 51, 88]}
)
display(df)
df["Result"] = df["Marks"].apply(lambda x: "Pass" if x >= 60 else "Fail")
display(df)
出力:
---output.webp)

I am Fariba Laiq from Pakistan. An android app developer, technical content writer, and coding instructor. Writing has always been one of my passions. I love to learn, implement and convey my knowledge to others.
LinkedIn