Pandas でグループ化されたデータの平均を計算する
-
groupby.mean()を使用して Pandas で単一列の平均を計算する -
groupby.mean()を使用して Pandas で複数の列の平均を計算する -
agg()メソッドを使用して、Pandas でグループ化されたデータの平均を計算する

Pandas は、Python のオープンソース データ分析ライブラリです。 数値データに対して操作を実行するための組み込みメソッドが多数用意されています。
groupby() は Pandas で利用可能なメソッドの 1つで、いくつかの基準に従ってデータを複数のグループに分割します。 その後、count()、mean()などのように、グループ化されたデータにさまざまなメソッドを適用できます。
このチュートリアルでは、Pandas で groupby.mean() メソッドを使用してグループ化されたデータの平均を見つける方法を示します。
groupby.mean() を使用して Pandas で単一列の平均を計算する
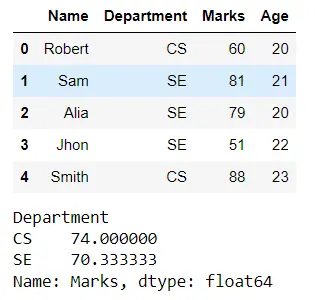
ここでは、Pandas データフレーム オブジェクトに学生のデータがあり、データは学科に基づいてグループ化されています。 2つの部門に対して 2つのグループを用意します。
次に、各グループまたは部門の学生の平均点を、単一の列、つまりMarksで groupby.mean() メソッドを介して計算します。 出力では、CS 部門と SE 部門の学生の平均点を取得します。
コード例:
# Python 3.x
import pandas as pd
df = pd.DataFrame(
{
"Name": ["Robert", "Sam", "Alia", "Jhon", "Smith"],
"Department": ["CS", "SE", "SE", "SE", "CS"],
"Marks": [60, 81, 79, 51, 88],
"Age": [20, 21, 20, 22, 23],
}
)
display(df)
df.groupby("Department")["Marks"].mean()
出力:
groupby.mean() を使用して Pandas で複数の列の平均を計算する
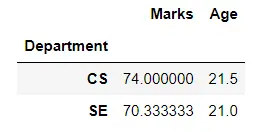
平均を計算するすべての問題の名前を指定することで、データをグループ化した後、複数の列の平均を同時に取得することもできます。 次のコードでは、データを学科ごとに分割し、学生の平均 Marks と Age を計算しています。
コード例:
# Python 3.x
import pandas as pd
df = pd.DataFrame(
{
"Name": ["Robert", "Sam", "Alia", "Jhon", "Smith"],
"Department": ["CS", "SE", "SE", "SE", "CS"],
"Marks": [60, 81, 79, 51, 88],
"Age": [20, 21, 20, 22, 23],
}
)
display(df)
df.groupby("Department")["Marks", "Age"].mean()
出力:
agg() メソッドを使用して、Pandas でグループ化されたデータの平均を計算する
あるいは、agg() メソッドを使用して、オブジェクトごとのグループの平均を計算することもできます。 agg() メソッドへの引数として mean を渡します。
コード例:
# Python 3.x
import pandas as pd
df = pd.DataFrame(
{
"Name": ["Robert", "Sam", "Alia", "Jhon", "Smith"],
"Department": ["CS", "SE", "SE", "SE", "CS"],
"Marks": [60, 81, 79, 51, 88],
"Age": [20, 21, 20, 22, 23],
}
)
display(df)
df.groupby("Department")["Marks"].agg("mean")
出力:
---output.webp)

I am Fariba Laiq from Pakistan. An android app developer, technical content writer, and coding instructor. Writing has always been one of my passions. I love to learn, implement and convey my knowledge to others.
LinkedIn