Pandas で特定の文字列を含む行をフィルター処理する
- 前提ライブラリのインストール
- Pandas データフレームを作成する
-
str.contains()を使用して、特定の文字列を含む行をフィルタリングする -
str.contains()を使用して、リストに文字列を含む行をフィルタリングする
Pandas ライブラリは、数値に加えてテキスト データを処理するための完全なツールです。 多くのデータ分析アプリケーションと機械学習の探索/前処理からテキスト入力を除外する必要があります。
Python のデータフレームは、Pandas モジュールに存在する主要なデータ構造です。 これらのデータ構造は、データを表形式で格納および処理するために使用されます。
表形式で保存されたデータに対して実行されるそのようなプロセスの 1つは、データフレームを部分文字列基準でフィルタリングして、そこから関連情報を抽出できるようにすることです。 この記事では、これと同じ操作を実行する手順を順を追って説明します。
前提ライブラリのインストール
Pandas データフレームのフィルタリングを開始するには、まず Pandas ライブラリをインストールする必要があります。 選択したターミナルで次のコマンドを実行することで、これをすばやく実現できます。
pip install pandas
また、正しい Python バージョンで作業することも不可欠です。 この記事では、バージョン 3.10.4 を使用しています。
ターミナルで次のコマンドを実行すると、現在インストールされている Python のバージョンを確認できます。
python --version
Pandas データフレームを作成する
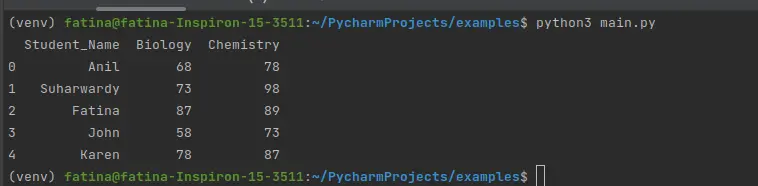
データフレーム フィルタリング操作を実行するには、サンプル データフレームが必要です。 したがって、以下のコードを使用して記事のデータフレームを生成します。 生物と化学の 2 科目で 100 人中 5 人の生徒の名前が採点されています。
コード例:
import pandas as pd
data = {
"Student_Name": ["Anil", "Suharwardy", "Fatina", "John", "Karen"],
"Biology": [68, 73, 87, 58, 78],
"Chemistry": [78, 98, 89, 73, 87],
}
data_frame = pd.DataFrame(data)
print(data_frame)
したがって、上記のコードは非常に簡単です。 Pandas ライブラリをインポートすることから始めて、結果のデータフレームに挿入する情報を含む辞書として data 変数を初期化します。
次に、Pandas モジュールの DataFrame() メソッドを使用して、data ディクショナリを上記の手法に渡すことでデータフレームを生成します。
コードを実行すると、次のデータフレームが生成されます。
出力:
str.contains() を使用して、特定の文字列を含む行をフィルタリングする
データフレームを作成したので、フィルタリングのステップに進むことができます。 Suharwardy という生徒のデータを除外したいとしましょう。 結果は、Suharwardy に対して保存されたすべての情報になります。
str.contains() メソッドを使用してこの操作を実行できます。 以下のスニペットでは、データフレーム列 Student_Name にアクセスし、str.contains() メソッドを使用して、Suharwardy という名前に対して保存されている情報にアクセスしています。
コード例:
import pandas as pd
data = {
"Student_Name": ["Anil", "Suharwardy", "Fatina", "John", "Karen"],
"Biology": [68, 73, 87, 58, 78],
"Chemistry": [78, 98, 89, 73, 87],
}
data_frame = pd.DataFrame(data=data)
df = data_frame[data_frame["Student_Name"].str.contains("Suharwardy")]
print(df)
出力:

この操作を実行するさらに簡単で直感的な方法は、ドット演算子を使用して Student_Name 列にアクセスすることです。 同じ結果が得られます。
コード例:
import pandas as pd
data = {
"Student_Name": ["Anil", "Suharwardy", "Fatina", "John", "Karen"],
"Biology": [68, 73, 87, 58, 78],
"Chemistry": [78, 98, 89, 73, 87],
}
data_frame = pd.DataFrame(data=data)
df = data_frame[data_frame.Student_Name.str.contains("Suharwardy")]
print(df)
出力:

str.contains() メソッドには regex パラメータもあり、これを False に設定することでより高速な結果を得ることができます。
コード例:
import pandas as pd
import regex as regex
data = {
"Student_Name": ["Anil", "Suharwardy", "Fatina", "John", "Karen"],
"Biology": [68, 73, 87, 58, 78],
"Chemistry": [78, 98, 89, 73, 87],
}
data_frame = pd.DataFrame(data=data)
df = data_frame[data_frame.Student_Name.str.contains("Suharwardy", regex=False)]
print(df)
出力:
これは、str.contains() メソッドを使用して Pandas データフレームをフィルタリングし、抽出する情報の詳細を指定する方法です。
str.contains() を使用して、リストに文字列を含む行をフィルタリングする
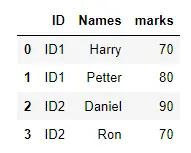
以下のコードは、ID 列に ID1 または ID2 を含むデータフレーム行をフィルタリングする方法を示しています。
コード例:
import pandas as pd
d1 = {
"ID": [
"ID1",
"ID1",
"ID2",
"ID2",
"ID3",
"ID3",
],
"Names": ["Harry", "Petter", "Daniel", "Ron", "Sofia", "Kelvin"],
"marks": [70, 80, 90, 70, 60, 90],
}
df = pd.DataFrame(d1)
print(df)
s = df[df["ID"].str.contains("ID1|ID2")]
print("use of str.contains() : ")
print(s)
出力:

I am Fariba Laiq from Pakistan. An android app developer, technical content writer, and coding instructor. Writing has always been one of my passions. I love to learn, implement and convey my knowledge to others.
LinkedIn