BeautifulSoup を使用して HTML テーブルをデータ フレームにスクレイプする
Python には、プロジェクトの要件を考慮して使用できるさまざまなパッケージがあります。 1つは BeautifulSoup で、HTML および XML ドキュメントの解析に使用されます。
これは、HTML から情報 (データ) を抽出するために使用できる、解析されたページの解析ツリーを作成します。これは Web スクレイピングに役立ちます。 今日のチュートリアルでは、BeautifulSoup パッケージを使用して HTML テーブルをデータ フレームにスクレイピングする方法を説明します。
BeautifulSoup を使用して HTML テーブルをデータ フレームにスクレイピングする
常に整理されて整理されたデータを毎回取得する必要はありません。
時には、ウェブサイトで入手可能なデータが必要になることがあります。 そのためには、それを収集できなければなりません。
幸いなことに、Python の BeautifulSoup パッケージには解決策があります。 このパッケージを使用してテーブルをデータ フレームにスクレイピングする方法を学びましょう。
まず、このパッケージをマシンにインストールして、Python スクリプトにインポートできるようにする必要があります。 WindowsオペレーティングシステムにBeautifulSoupをインストールするには、pipコマンドを使用できます。
pip install beautifulsoup
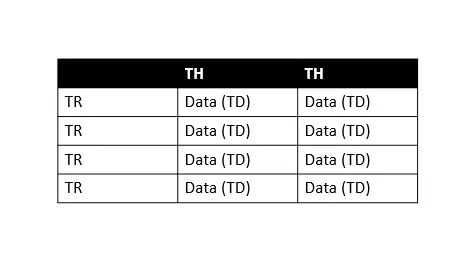
詳細については、この ドキュメント を参照してください。 HTML テーブルの基本構造に慣れていないことはわかっています。これは、スクレイピング中に知っておくことが重要です。 このチュートリアルに従うことを理解しましょう。
上記の表で、TH は表のヘッダー、TR は表の行、TD は表のデータ (セルと呼びます) を意味します。 すべてのテーブル行に複数のテーブル データがあることがわかるので、各行を簡単に反復処理して情報を抽出できます。
それでは、順を追って学習していきましょう。
-
ライブラリのインポート
import requests import pandas as pd from bs4 import BeautifulSoupまず、データ フレームを操作するための
pandasライブラリ、データをスクレイピングするためのbs4(美しいスープ)、および Python を使用して HTTP 要求を作成するためのrequestsライブラリのすべてのライブラリをインポートする必要があります。 -
Web ページからコンテンツをダウンロードする
web_url = "https://pt.wikipedia.org/wiki/Lista_de_bairros_de_Manaus" data = requests.get(web_url).text # data # print(data) # print(type(data))ここでは、必要な URL を
web_url変数に保存し、requestsモジュールを使用して HTTP リクエストを作成します。requestsモジュールの.get()を使用して、指定されたweb_urlからデータを取得しますが、.textはデータを文字列として取得することを意味します。したがって、
print(type(data))として印刷すると、ページ全体の HTML を文字列として取得したことがわかります。data、print(data)およびprint(type(data))を印刷することで遊ぶことができます。これらはすべて上記のコード フェンスにあります。 それらのコメントを外して練習することができます。
-
BeautifulSoupオブジェクトを作成するbeautiful_soup = BeautifulSoup(data, "html.parser") # print(type(beautiful_soup.b))BeautifulSoupオブジェクト (beautiful_soup) は、解析されたドキュメント全体を表します。 したがって、スクレイピングしようとしているのは完全なドキュメントであると言えます。ほとんどの場合、
Tagオブジェクトとして扱いますが、これはprint(type(beautiful_soup.b))ステートメントを使用して確認することもできます。 これで、必要なページの完全な HTML ができました。次のステップは、必要なテーブルを見つけることです。最初のテーブルから情報を取得できますが、同じ Web ページに複数のテーブルが存在する可能性があります。
したがって、スクレイピングしたい必要なテーブルを見つけることが重要です。 どうやって? これは、ソース コードを調べることで簡単に行うことができます。
そのためには、必要な Web ページの任意の場所で
右クリックして検査を選択し、Ctrl+Shift+C を押して、 要素 (次のスクリーンショットで赤で強調表示)、検索ボックスを使用して特定のタグ (次のスクリーンショットで緑で強調表示) を見つけることもできます。
3つのテーブルがあります。 上のスクリーンショットに示されているように (検索ボックス内のこの番号を緑色で強調表示してください)、強調表示されたテーブルを
class="wikitable sortable jquery-tablesorter"で使用しています。要点は、なぜ
class属性を使用してテーブルを選択するのかということです。 これは、テーブルにタイトルがなく、class属性があるためです。 -
クラスを使用してテーブルを検証する
print("Classes of Every table:") for table in beautiful_soup.find_all("table"): print(table.get("class"))出力:
Classes of Every table: ['box-Desatualizado', 'plainlinks', 'metadata', 'ambox', 'ambox-content'] ['wikitable', 'sortable'] ['nowraplinks', 'collapsible', 'collapsed', 'navbox-inner']ここでは、すべての
<table>要素を繰り返し処理して、class属性を取得してそれらのクラスを見つけます。 -
wikitableおよびsortableクラスの検索tables = beautiful_soup.find_all("table") table = beautiful_soup.find("table", class_="wikitable sortable")まず、すべてのテーブルのリストを作成し、クラス
wikitableとsortableを持つテーブルを探します。 -
データ フレームを作成して入力する
df = pd.DataFrame( columns=["Neighborhood", "Zone", "Area", "Population", "Density", "Homes_count"] ) mylist = [] for table_row in table.tbody.find_all("tr"): table_columns = table_row.find_all("td") if table_columns != []: neighbor = table_columns[0].text.strip() zone = table_columns[1].text.strip() area = table_columns[2].span.contents[0].strip("&0.") population = table_columns[3].span.contents[0].strip("&0.") density = table_columns[4].span.contents[0].strip("&0.") home_count = table_columns[5].span.contents[0].strip("&0.") mylist.append([neighbor, zone, area, population, density, home_count]) df = pd.DataFrame( mylist, columns=["Neighborhood", "Zone", "Area", "Population", "Density", "Homes_count"], )ここでは、
Neighborhood、Zone、Area、Population、Density、およびHomes_count列を含むデータ フレームを定義します。 次に、HTML テーブルを繰り返し処理してデータを取得し、定義したばかりのデータ フレームに入力します。 -
df.head()を使用して最初の 5つのドキュメントを印刷するprint(df.head())出力:
Neighborhood Zone Area Population Density Homes_count 0 Adrianópolis Centro-Sul 248.45 10459 3560.88 3224 1 Aleixo Centro-Sul 618.34 24417 3340.4 6101 2 Alvorada Centro-Oeste 553.18 76392 11681.73 18193 3 Armando Mendes Leste 307.65 33441 9194.86 7402 4 Betânia Sul 52.51 1294 20845.55 3119
完全なソース コード:
import requests
import pandas as pd
from bs4 import BeautifulSoup
web_url = "https://pt.wikipedia.org/wiki/Lista_de_bairros_de_Manaus"
data = requests.get(web_url).text
beautiful_soup = BeautifulSoup(data, "html.parser")
print("Classes of Every table:")
for table in beautiful_soup.find_all("table"):
print(table.get("class"))
tables = beautiful_soup.find_all("table")
table = beautiful_soup.find("table", class_="wikitable sortable")
df = pd.DataFrame(
columns=["Neighborhood", "Zone", "Area", "Population", "Density", "Homes_count"]
)
mylist = []
for table_row in table.tbody.find_all("tr"):
table_columns = table_row.find_all("td")
if table_columns != []:
neighbor = table_columns[0].text.strip()
zone = table_columns[1].text.strip()
area = table_columns[2].span.contents[0].strip("&0.")
population = table_columns[3].span.contents[0].strip("&0.")
density = table_columns[4].span.contents[0].strip("&0.")
home_count = table_columns[5].span.contents[0].strip("&0.")
mylist.append([neighbor, zone, area, population, density, home_count])
df = pd.DataFrame(
mylist,
columns=["Neighborhood", "Zone", "Area", "Population", "Density", "Homes_count"],
)
print(df.head())
出力:
Classes of Every table:
['box-Desatualizado', 'plainlinks', 'metadata', 'ambox', 'ambox-content']
['wikitable', 'sortable']
['nowraplinks', 'collapsible', 'collapsed', 'navbox-inner']
Neighborhood Zone Area Population Density Homes_count
0 Adrianópolis Centro-Sul 248.45 10459 3560.88 3224
1 Aleixo Centro-Sul 618.34 24417 3340.4 6101
2 Alvorada Centro-Oeste 553.18 76392 11681.73 18193
3 Armando Mendes Leste 307.65 33441 9194.86 7402
4 Betânia Sul 52.51 1294 20845.55 3119
