C# で PDF ファイルを読む

この記事では、PDF ドキュメントを解析して文字列変数に格納する方法について説明します。 この変数は、C# プログラムで複数の目的に使用できます。
C# での PDF 解析
C# で PDF を操作するのは簡単で、C# のライブラリを使用して PDF ファイルを解析するなど、.NET アプリケーションに必要なすべての機能を使用できます。 このチュートリアルでは、2つの異なる C# ライブラリ、IronPDF と iTextSharp を使用して、いくつかの簡単な手順でそれを実現します。
C# で IronPDF を使用して PDF ファイルを読み取り/解析する
IronPDF は、PDF ドキュメントを生成および解析するために C# で開発された商用ライブラリです。 文字列または HTML から PDF を生成する機能があります。
あらゆる種類の .NET アプリケーション、デスクトップ アプリケーション、Web アプリケーション、サーバー アプリケーション、さらには WPF アプリケーションで機能します。
ライブラリを使用して PDF ファイルを読み取る手順を以下に列挙します。
-
NuGet パッケージ インストーラーを使用して、Visual Studio に IronPDF ライブラリをダウンロードします。
-
ソリューション エクスプローラー ウィンドウでプロジェクト名を右クリックし、[NuGet パッケージの管理] を選択します。
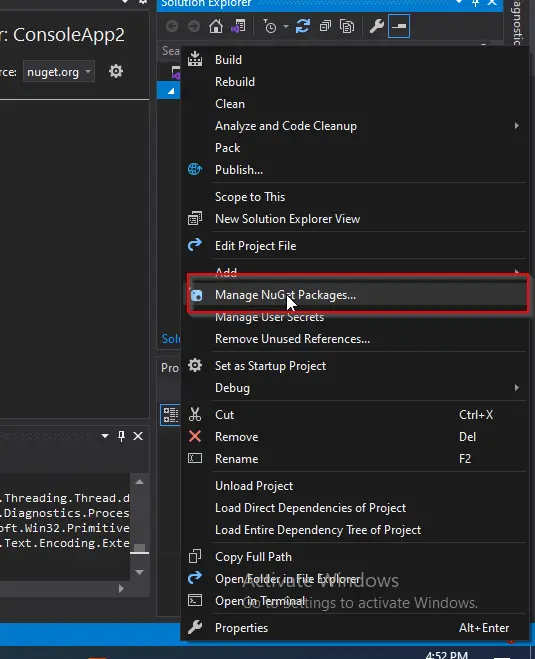
-
[NuGet パッケージ] ウィンドウが表示されます。 そのウィンドウの [参照] タブで、IronPDF を検索し、最初のライブラリを選択します。
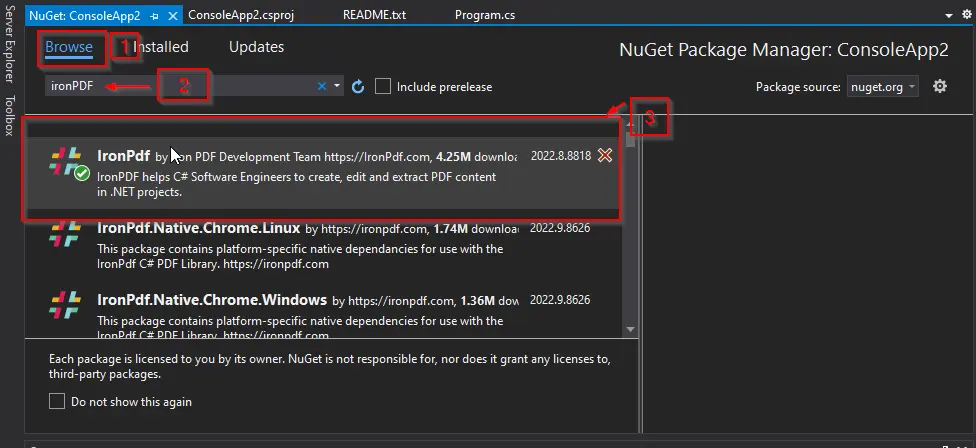
-
PDF ドキュメントを解析するコードを記述します。
IronPDF をいじってみると、C# での PDF ファイルの操作を簡単にする機能がいくつあるかがわかります。 主に、必要な形式の PDF ファイルの作成、読み取り、および編集に関係しています。
PDF ファイルは簡単に解析できます。
以下のコードでは、ExtractAllText() メソッドを使用して、PDF ファイル全体からすべてのテキスト行を取得しています。 PDF ファイルの内容を示す出力を後で表示できます。
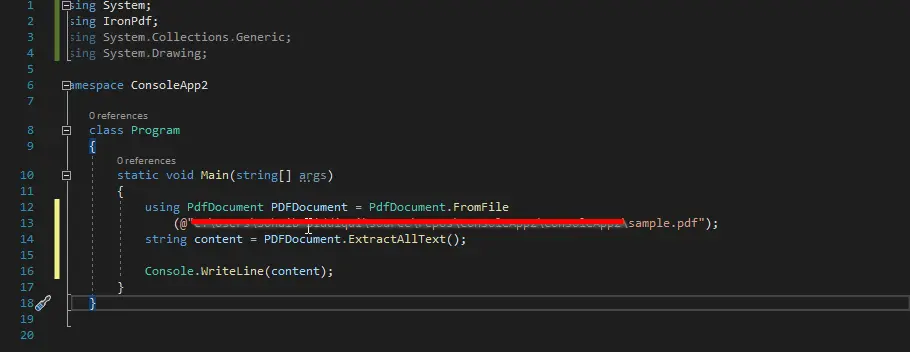
最初に PdfDocument のオブジェクトを作成し、それを解析するファイルのパスに渡したことがコードからわかります。
次に、メソッド ExtractAllText() を呼び出し、すべてのコンテンツを文字列変数 content に格納しました。 次に、その変数を画面に表示しました。
これは非常にシンプルで簡単な作業です。 以下の出力を確認できます。
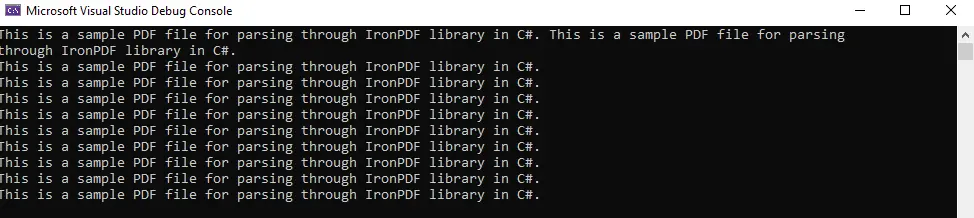
iTextSharp を使用して C# で PDF ファイルを読み取り/解析する
iTextSharp は、複雑な PDF レポートを作成するための高度なツールである別の C# ライブラリです。 これらのレポートは、Android、IOS、Java などの複数のプラットフォーム アプリケーションで使用できます。 データベースまたは XML 形式のデータを使用して PDF を作成し、任意の PDF ドキュメントをマージまたは分割できる機能があります。
iTextSharp を使用して PDF ファイルを読み取る手順を以下に示します。
-
NuGet パッケージ インストーラーを使用して、Visual Studio に iTextSharp ライブラリをダウンロードします。
-
ソリューション エクスプローラー ウィンドウでプロジェクト名を右クリックし、[NuGet パッケージの管理] を選択します。
-
[NuGet パッケージ] ウィンドウが表示されます。 そのウィンドウの [参照] タブで iTextSharp を検索し、最初のライブラリを選択して [インストール] を選択します。
-
次のライブラリを
csファイルに含めます。using iTextSharp.text.pdf; using iTextSharp.text.pdf.parser; -
PDFファイルを読み取り、そのPDFファイルを文字列変数で解析する関数を作成しましょう。
public static string parsePDFDocument(string filePath) { using (PdfReader read = new PdfReader(filePath)) { StringBuilder convertedText = new StringBuilder(); for (int p = 1; p <= read.NumberOfPages; p++) { convertedText.Append(PdfTextExtractor.GetTextFromPage(read, p)); } return convertedText.ToString(); } }
このコード スニペットでは、iTextSharp ライブラリの一部である PdfReader クラスのオブジェクトを作成しました。 このオブジェクトは、解析する PDF ドキュメントのファイル パスを受け取ります。
その後、PDF ファイルのテキストを格納できる StringBuilder クラスを使用して文字列を作成しました。
ループは、最初のページから PDF ドキュメントの合計ページ数まで開始されます。 ループ内で、作成された文字列オブジェクトにページごとにテキストを追加しました。
最後に、文字列は関数が呼び出されるポイントに返されます。
Main 関数は次のようになります。
static void Main(string[] args) {
var ExtractedTextFromPDF = parsePDFDocument([path to PDF file]);
Console.WriteLine(ExtractedTextFromPDF);
}
PDF ファイルを完全なパスで渡すようにしてください。 コンパイル後、次の出力が得られます。
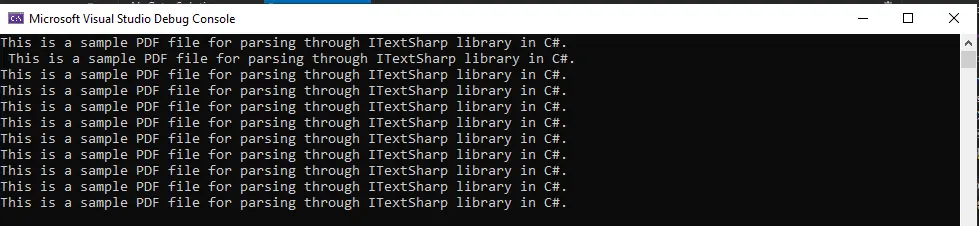
出力は、PDF ファイル全体がテキストに変換され、画面に表示されることを示しています。
このライブラリは、ページ番号に基づいてドキュメントを分割するメソッドを提供します。 さらに、PDF を作成する機能もこのライブラリで利用できます。