Scipy scipy.optimize.curve_fit メソッド
-
scipy.optimize.curve_fit()の構文: -
コード例:
scipy.optimize.curve_fit()データに直線を当てはめるメソッド(線形モデル式) -
コード例:
scipy.optimize.curve_fit()指数曲線をデータに適合させるメソッド(指数モデル式)
Python Scipy scipy.optimize.curve_fit() 関数は、最小二乗近似を使用して最適なパラメーターを求めるために使用されます。curve_fit メソッドは、モデルをデータに適合させます。
カーブフィットは、提供された一連の観測値に最適な、定義された関数のパラメーターの最適なセットを求めるために不可欠です。
scipy.optimize.curve_fit() の構文:
scipy.optimize.curve_fit(f, xdata, ydata, sigma=None, p0=None)
パラメーター
f |
モデル関数です。最初の引数として独立変数を取り、残りの個別の引数として適合するパラメーターを取ります。 |
xdata |
配列のような。独立変数または関数への入力。 |
ydata |
配列のような。従属変数。関数の出力。 |
sigma |
オプションの値。これは、データの推定不確実性です。 |
p0 |
パラメータの初期推定。カーブフィットは、ハンティングを開始する場所、パラメーターの妥当な値を認識している必要があります。 |
戻り値
2つの値を返します。
popt:配列のようなもの。モデル関数の最適値が含まれています。内部には、slopeのフィット結果とinterceptのフィット結果を含みます。p-cov:共分散。近似結果の不確実性を示します。
コード例:scipy.optimize.curve_fit() データに直線を当てはめるメソッド(線形モデル式)
import numpy as np
import matplotlib.pyplot as plt
import scipy
from scipy import optimize
def function(x, a, b):
return a * x + b
x = np.linspace(start=-50, stop=10, num=40)
y = function(x, 6, 2)
np.random.seed(6)
noise = 20 * np.random.normal(size=y.size)
y = y + noise
popt, cov = scipy.optimize.curve_fit(function, x, y)
a, b = popt
x_new_value = np.arange(min(x), 30, 5)
y_new_value = function(x_new_value, a, b)
plt.scatter(x, y, color="green")
plt.plot(x_new_value, y_new_value, color="red")
plt.xlabel("X")
plt.ylabel("Y")
print("Estimated value of a : " + str(a))
print("Estimated value of b : " + str(b))
plt.show()

出力:
Estimated value of a : 5.859050240780936
Estimated value of b : 1.172416121927438
この例では、最初に y = 6*x+2 の式を使用して 40 ポイントのデータセットを生成します。次に、データセットの y 値にガウスノイズを追加して、よりリアルに見せます。ここで、基礎となる方程式 y=a*x+b のパラメーターa と b を推定します。これにより、scipy.optimize.curve_fit() メソッドを使用してデータセットが生成されます。プロットの緑の点はデータセットの実際のデータ点を表し、赤の線は scipy.optimize.curve_fit() メソッドを使用してデータセットに適合した曲線を表します。
最後に、scipy.optimize.curve_fit() メソッドを使用して推定された a と b の値は、それぞれ 5.859 と 1.172 であり、実際の値 6 とにかなり近いことがわかります。2。
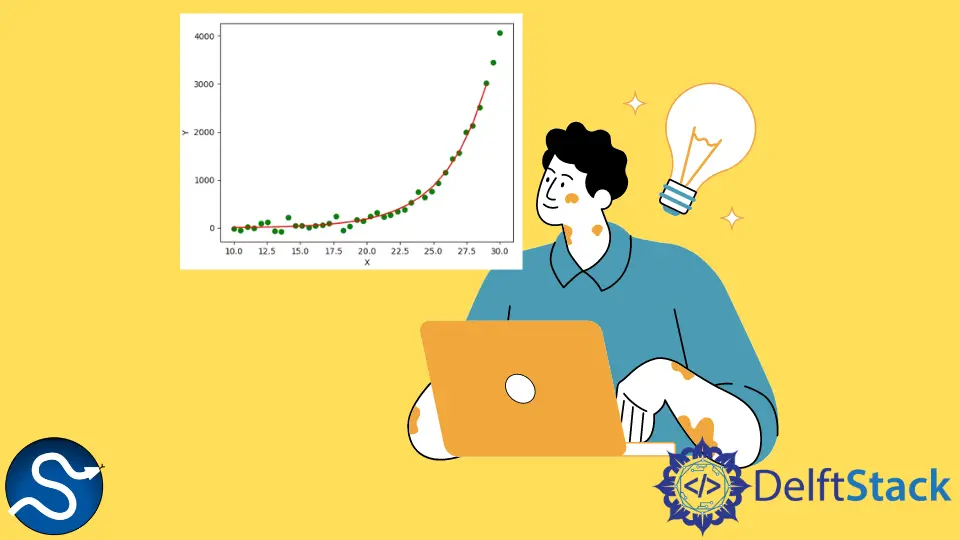
コード例:scipy.optimize.curve_fit() 指数曲線をデータに適合させるメソッド(指数モデル式)
import numpy as np
import matplotlib.pyplot as plt
import scipy
from scipy import optimize
def function(x, a, b):
return a * np.exp(b * x)
x = np.linspace(10, 30, 40)
y = function(x, 0.5, 0.3)
print(y)
noise = 100 * np.random.normal(size=y.size)
y = y + noise
print(y)
popt, cov = scipy.optimize.curve_fit(function, x, y)
a, b = popt
x_new_value = np.arange(min(x), max(x), 1)
y_new_value = function(x_new_value, a, b)
plt.scatter(x, y, color="green")
plt.plot(x_new_value, y_new_value, color="red")
plt.xlabel("X")
plt.ylabel("Y")
print("Estimated value of a : " + str(a))
print("Estimated value of b : " + str(b))
plt.show()

出力:
Estimated value of a : 0.5109620054206334
Estimated value of b : 0.2997005016319089
この例では、最初に方程式 y = 0.5*x^0.3 を使用して 40 ポイントのデータセットを生成します。次に、データセットの y 値にガウスノイズを追加して、より現実的にします。ここで、scipy.optimize.curve_fit() メソッドを使用してデータセットを生成する基礎となる方程式 y = a*x^b のパラメーターa と b を推定します。プロットの緑の点はデータセットの実際のデータ点を表し、赤の線は scipy.optimize.curve_fit() メソッドを使用してデータセットに適合した曲線を表します。
最後に、scipy.optimize.curve_fit() メソッドを使用して推定された a と b の値は、それぞれ 0.5109 と 0.299 であり、実際の値 0.5 とにかなり近いことがわかります。0.3。
このようにして、scipy.optimize.curve_fit() メソッドを使用して、特定のデータポイントの基礎となる方程式を決定できます。

Suraj Joshi is a backend software engineer at Matrice.ai.
LinkedIn