Prendi sezioni di colonna di DataFrame in Pandas
-
Usa
loc()per dividere le colonne in Pandas DataFrame -
Usa
iloc()per suddividere le colonne in Pandas DataFrame -
Usa
redindex()per suddividere le colonne in Pandas DataFrame
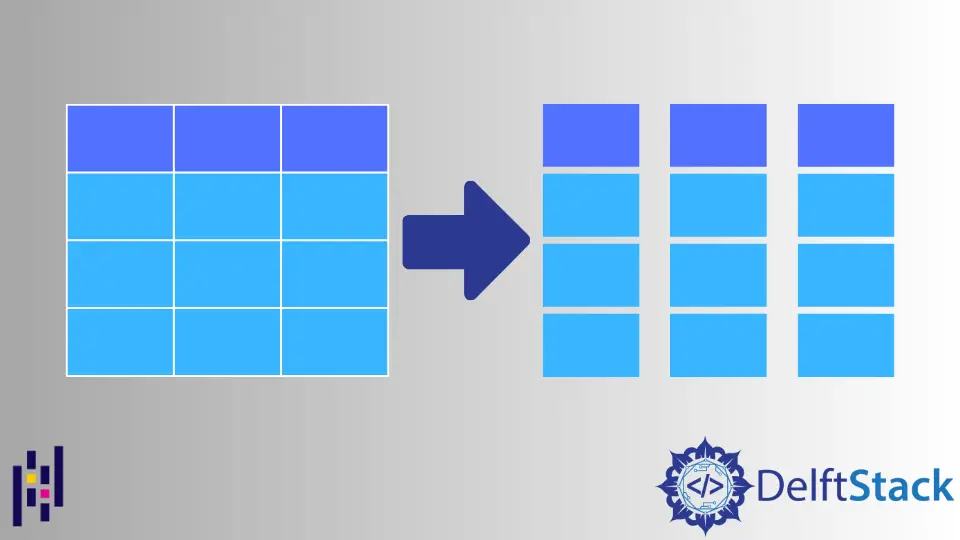
L’affettatura delle colonne in Pandas ci consente di suddividere il dataframe in sottoinsiemi, il che significa che crea un nuovo dataframe Pandas dall’originale con solo le colonne richieste. Lavoreremo con il seguente dataframe come esempio per l’affettatura delle colonne.
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.rand(4, 4), columns=["a", "b", "c", "d"])
print(df)
Produzione:
a b c d
0 0.797321 0.468894 0.335781 0.956516
1 0.546303 0.567301 0.955228 0.557812
2 0.385315 0.706735 0.058784 0.578468
3 0.751037 0.248284 0.172229 0.493763
Usa loc() per dividere le colonne in Pandas DataFrame
La libreria Pandas ci fornisce più di un metodo per eseguire l’affettatura delle colonne. Il primo sta usando la funzione loc().
La funzione Pandas loc() ci permette di accedere agli elementi di un dataframe usando nomi di colonne o etichette di indice. La sintassi per la suddivisione di colonne utilizzando loc():
dataframe.loc[:, [columns]]
Esempio:
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.rand(4, 4), columns=["a", "b", "c", "d"])
df1 = df.loc[:, "a":"c"] # Returns a new dataframe with columns a,b and c
print(df1)
Produzione:
a b c
0 0.344952 0.611792 0.213331
1 0.907322 0.992097 0.080447
2 0.471611 0.625846 0.348778
3 0.656921 0.999646 0.976743
Usa iloc() per suddividere le colonne in Pandas DataFrame
Possiamo anche usare la funzione iloc() per accedere agli elementi di un dataframe usando l’indice intero di righe e colonne. La sintassi per la suddivisione di colonne utilizzando iloc():
dataframe.iloc[:, [column - index]]
Esempio:
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.rand(4, 4), columns=["a", "b", "c", "d"])
df1 = df.iloc[:, 0:2] # Returns a new dataframe with first two columns
print(df1)
Produzione:
a b
0 0.034587 0.070249
1 0.648231 0.721517
2 0.485168 0.548045
3 0.377612 0.310408
Usa redindex() per suddividere le colonne in Pandas DataFrame
La funzione reindex() può anche essere usata per alterare gli indici del dataframe e può essere usata per affettare le colonne. La funzione reindex() può contenere molti argomenti ma per l’affettamento delle colonne, avremo solo bisogno di fornire alla funzione i nomi delle colonne.
La sintassi per la suddivisione di colonne utilizzando reindex():
dataframe.reindex(columns=[column_names])
Esempio:
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.rand(4, 4), columns=["a", "b", "c", "d"])
# Returns a new dataframe with c and b columns
df1 = df.reindex(columns=["c", "b"])
print(df1)
Produzione:
c b
0 0.429790 0.962838
1 0.605381 0.463617
2 0.922489 0.733338
3 0.741352 0.118478

Manav is a IT Professional who has a lot of experience as a core developer in many live projects. He is an avid learner who enjoys learning new things and sharing his findings whenever possible.
LinkedInArticolo correlato - Pandas DataFrame
- Come ottenere le intestazioni delle colonne DataFrame Pandas come lista
- Come cancellare la colonna DataFrame Pandas DataFrame
- Come convertire la colonna DataFrame in data e ora in pandas
- Converti un Float in un Integer in Pandas DataFrame
- Ordina Pandas DataFrame in base ai valori di una colonna
- Ottieni l'aggregato di Pandas Group-By e Sum