Funzione Pandas pandas.pivot_table()
-
Sintassi di
pandas.pivot_table() -
Codici di esempio:
pandas.pivot_table() -
Codici di esempio:
pandas.pivot_table()per specificare più funzioni di aggregazione -
Codici di esempio:
pandas.pivot_table()per utilizzare il parametromargins
La funzione Python Pandas pandas.pivot_table() evita la ripetizione dei dati del DataFrame. Riassume i dati e applica diverse funzioni aggregate sui dati.
Sintassi di pandas.pivot_table()
pandas.pivot_table(
data,
values=None,
index=None,
columns=None,
aggfunc="mean",
fill_value=None,
margins=False,
dropna=True,
margins_name="All",
observed=False,
)
Parametri
Questa funzione ha diversi parametri. I valori di default di tutti i parametri sono menzionati sopra.
data |
È il DataFrame da cui vogliamo rimuovere i dati ripetuti. |
values |
Rappresenta la colonna da aggregare. |
index |
È una column, grouper, un array o una lista. Rappresenta la colonna di dati che vogliamo come indice, ovvero come righe. |
columns |
È una column, grouper, un array o una lista. Rappresenta la colonna di dati che vogliamo come colonne nella nostra tabella pivot di output. |
aggfunc |
È una funzione, una lista di funzioni o un dizionario. Rappresenta la funzione aggregata che verrà applicata ai dati. Se viene passato una lista di funzioni aggregate, nella tabella risultante sarà presente una colonna per ciascuna funzione aggregata con il nome della colonna in alto. |
fill_value |
È uno scalare. Rappresenta il valore che sostituirà i valori mancanti nella tabella di output |
margins |
È un valore booleano. Rappresenta la riga e la colonna generate dopo aver preso la somma della rispettiva riga e colonna. |
dropna |
È un valore booleano. Elimina le colonne i cui valori sono NaN dalla tabella di output. |
margins_name |
È una stringa. Rappresenta il nome della riga e della colonna generate se il valore di margins è True. |
observed |
È un valore booleano. Se una cernia è categorica, si applica questo parametro. Se è True, mostra i valori osservati per le cernie categoriali. Se è False, mostra tutti i valori per le cernie categoriali |
Ritorno
Restituisce il DataFrame riepilogato.
Codici di esempio: pandas.pivot_table()
Approfondiamo questa funzione implementandola.
import pandas as pd
dataframe = pd.DataFrame({
"Name":
["Olivia",
"Olivia",
"Olivia",
"Olivia",
"Meghan",
"Meghan",
"Meghan",
"Meghan"],
"Date":
["03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019"],
"Science Marks":
[10,
2,
4,
6,
8,
9,
1,
10]
})
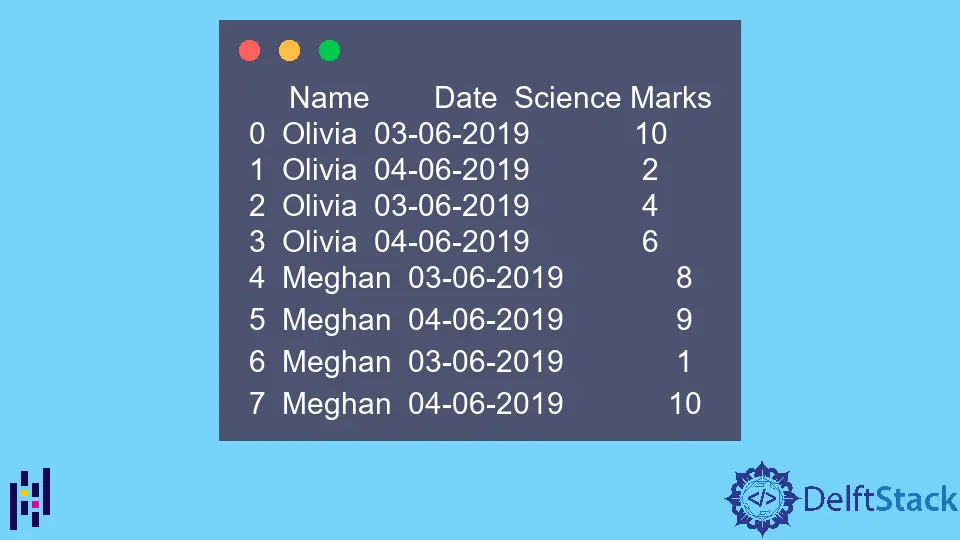
print(dataframe)
L’esempio DataFrame è,
Name Date Science Marks
0 Olivia 03-06-2019 10
1 Olivia 04-06-2019 2
2 Olivia 03-06-2019 4
3 Olivia 04-06-2019 6
4 Meghan 03-06-2019 8
5 Meghan 04-06-2019 9
6 Meghan 03-06-2019 1
7 Meghan 04-06-2019 10
Tieni presente che i dati precedenti contengono lo stesso valore in una colonna più volte. Questa funzione pivot_table riassumerà questi dati.
import pandas as pd
dataframe = pd.DataFrame(
{
"Name": [
"Olivia",
"Olivia",
"Olivia",
"Olivia",
"Meghan",
"Meghan",
"Meghan",
"Meghan",
],
"Date": [
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
],
"Science Marks": [10, 2, 4, 6, 8, 9, 1, 10],
}
)
pivotTable = pd.pivot_table(dataframe, index="Name", columns="Date")
print(pivotTable)
Produzione:
Science Marks
Date 03-06-2019 04-06-2019
Name
Meghan 4.5 9.5
Olivia 7.0 4.0
Qui abbiamo scelto la colonna Name come indice e la Data come colonna. La funzione ha generato il risultato in base ai parametri di default. La funzione aggregata predefinita mean() ha calcolato la media dei valori.
Codici di esempio: pandas.pivot_table() per specificare più funzioni di aggregazione
import pandas as pd
dataframe = pd.DataFrame(
{
"Name": [
"Olivia",
"Olivia",
"Olivia",
"Olivia",
"Meghan",
"Meghan",
"Meghan",
"Meghan",
],
"Date": [
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
],
"Science Marks": [10, 2, 4, 6, 8, 9, 1, 10],
}
)
pivotTable = pd.pivot_table(
dataframe, index="Name", columns="Date", aggfunc=["sum", "count"]
)
print(pivotTable)
Produzione:
sum count
Science Marks Science Marks
Date 03-06-2019 04-06-2019 03-06-2019 04-06-2019
Name
Meghan 9 19 2 2
Olivia 14 8 2 2
Abbiamo utilizzato due funzioni aggregate. Le colonne di queste funzioni vengono generate separatamente.
Codici di esempio: pandas.pivot_table() per utilizzare il parametro margins
import pandas as pd
dataframe = pd.DataFrame(
{
"Name": [
"Olivia",
"Olivia",
"Olivia",
"Olivia",
"Meghan",
"Meghan",
"Meghan",
"Meghan",
],
"Date": [
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
],
"Science Marks": [10, 2, 4, 6, 8, 9, 1, 10],
}
)
pivotTable = pd.pivot_table(
dataframe, index="Name", columns="Date", aggfunc=["sum", "count"], margins=True
)
print(pivotTable)
Produzione:
sum count
Science Marks Science Marks
Date 03-06-2019 04-06-2019 All 03-06-2019 04-06-2019 All
Name
Meghan 9 19 28 2 2 4
Olivia 14 8 22 2 2 4
All 23 27 50 4 4 8
Il parametro margins ha generato una nuova riga denominata All e una nuova colonna denominata anche All che mostra rispettivamente la somma della riga e della colonna.