How to Strip HTML Tags From String in JavaScript
- Strip HTML Tags With Regular Expression
-
Strip HTML Tags With
textContent - Strip HTML Tags With jQuery
-
Strip HTML Tags With
DOMParser - Strip HTML Tags With String-Strip-HTML Package

This article introduces how to strip HTML tags from a string using different methods with examples.
Strip HTML Tags With Regular Expression
You can create a regular expression pattern that’ll match the HTML tags in your string. As a result, you can replace each match with an empty string.
This effectively strips the HTML tags from the string.
We defined a regular expression pattern in the following code that replaces the HTML tags. However, it’s not bulletproof.
Anyone can break the regular expression pattern by supplying malformed HTML. So, if the malformed HTML contains some JavaScript, it could execute.
Or, the pattern removes the entire string, and you get an empty string in return.
let html = '<h1 class=\'header_tag\'>hello <i>world</i></h1>';
let cleanHTML = html.replace(/<\/?[^>]+(>|$)/gi, '');
console.log(cleanHTML);
Output:
hello world
Now, try the same code with a malformed HTML:
let html = '<div data="score> 42">Hello</div>';
let cleanHTML = html.replace(/<\/?[^>]+(>|$)/gi, '');
console.log(cleanHTML);
Output:
42">Hello
Strip HTML Tags With textContent
The textContent method will return the text from an HTML string. It’s a perfect fit to prevent Cross-Site Scripting attacks.
We’ve used textContent to strip the HTML tags in our example code below. However, keep the following in mind when using our approach:
- The HTML is valid within a
<div>element. That’s because HTML in a<body>or<html>is not valid within a<div>element. - The
textContentmethod will include text within a<script>element. So, if the string contains<script>elements, this method withtextContentwill return its content. - Based on the previous point, ensure the HTML has no
<script>elements. - Make sure the HTML is not
null. - The HTML is from a trusted source. That’s because the following HTML code will get through this method:
<img onerror='alert(\"Run dangerous JavaScript\")' src=nonexistence>
Example:
let html = '<h1 class=\'header_tag\'>hello <i>world</i></h1>';
let div = document.createElement('div');
div.innerHTML = html;
let text = div.textContent || div.innerText || '';
console.log(text);
Output:
hello world
When you update the string to contain the <script> element:
let htmlWithScriptElement = '<script>alert("Hello world");<\/script>';
let html =
`<h1 class='header_tag'>hello <i>world</i> ${htmlWithScriptElement}</h1>`;
let div = document.createElement('div');
div.innerHTML = html;
let text = div.textContent || div.innerText || '';
console.log(text);
Output:
hello world alert("Hello world");
You get the content of the <script> element.
From our last point on how the HTML should be from a trusted source, if it’s not, it could prove costly.
// This time the HTML contains code
// that'll get through stripping HTML tags
// with textContent
let html =
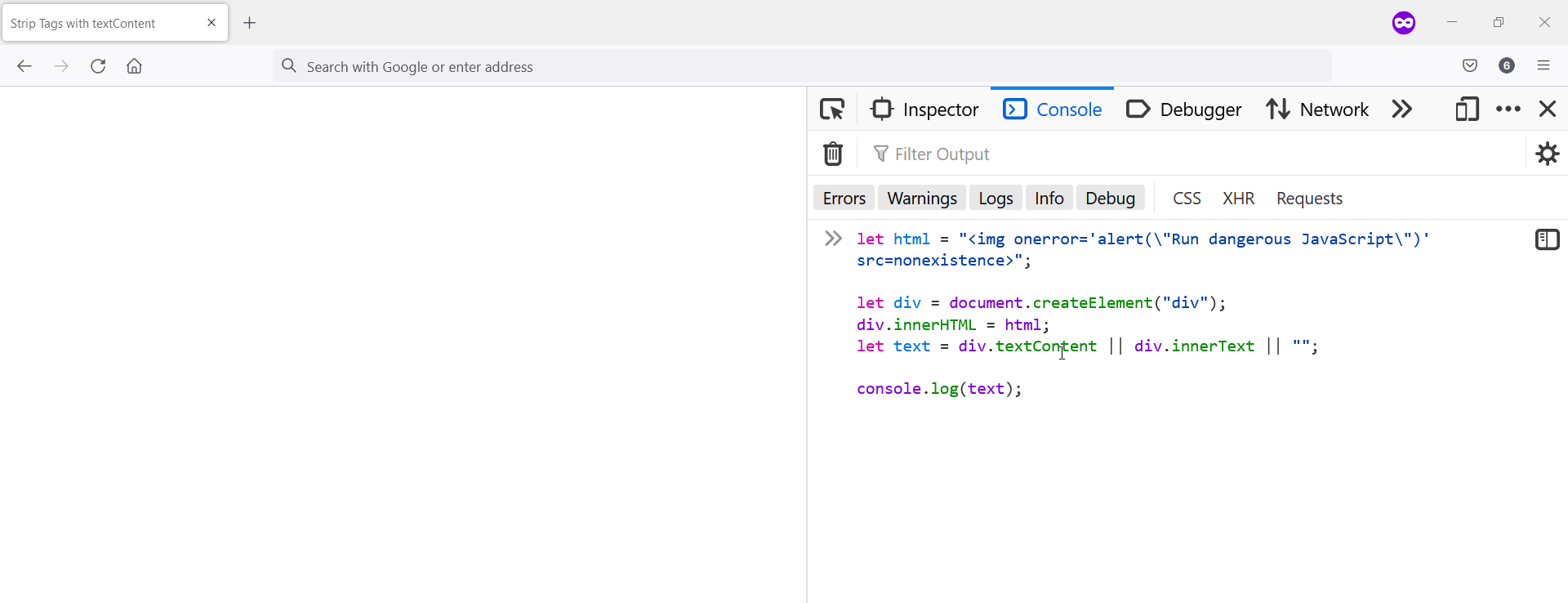
'<img onerror=\'alert("Run dangerous JavaScript")\' src=nonexistence>';
let div = document.createElement('div');
div.innerHTML = html;
let text = div.textContent || div.innerText || '';
console.log(text);
Output:
Strip HTML Tags With jQuery
The jQuery library has the .text() API that’ll return the text from a string that contains HTML. Although, you could use the JavaScript native innerText method.
However, jQuery’s approach is cross-browser. We’ve used the .text() API to remove the HTML from the given string in the following code.
Example:
<body>
<script src="https://ajax.googleapis.com/ajax/libs/jquery/3.6.0/jquery.min.js"></script>
<script type="text/javascript">
let html = "<h1 class='header_tag'>hello <i>world</i></h1>";
console.log($(html).text());
</script>
</body>
Output:
hello world
Meanwhile, this approach requires that the HTML comes from a trusted source. If not, you could execute arbitrary JavaScript code.
<body>
<script src="https://ajax.googleapis.com/ajax/libs/jquery/3.6.0/jquery.min.js"></script>
<script type="text/javascript">
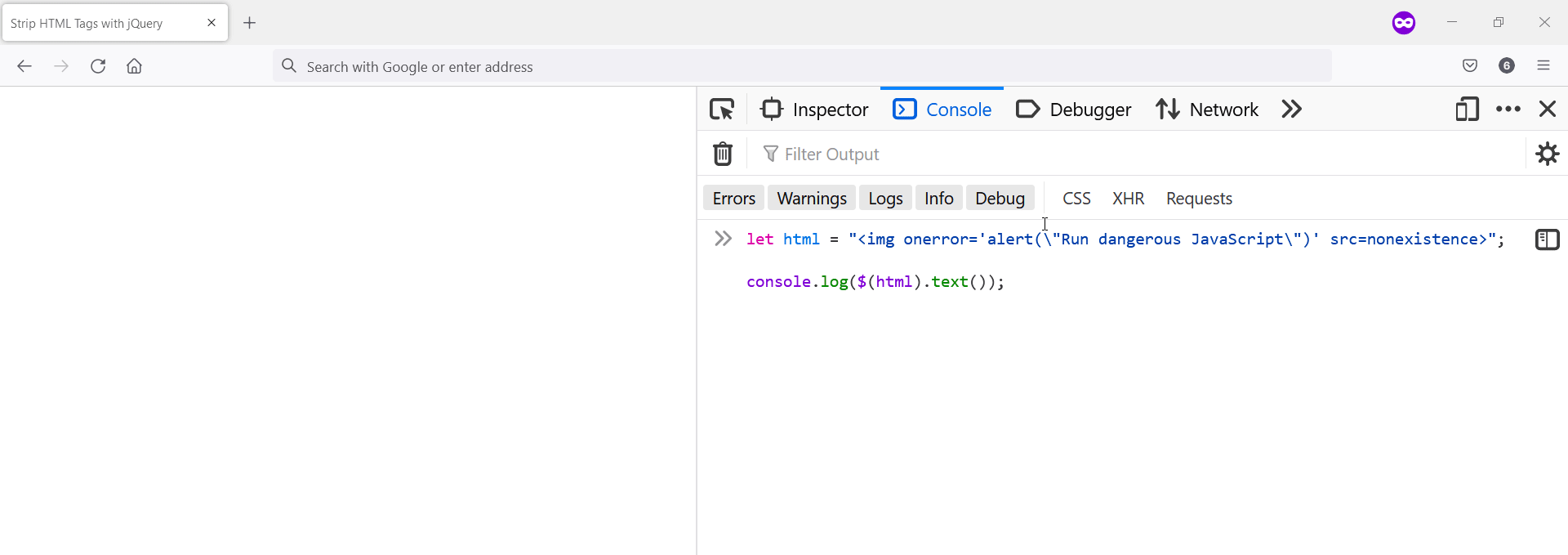
let html = "<img onerror='alert(\"Run dangerous JavaScript\")' src=nonexistence>";
console.log($(html).text());
</script>
</body>
Output:
Strip HTML Tags With DOMParser
With the help of the DOMParser, you can parse an HTML code. So, when a string contains HTML code, you can strip the HTML tags with the DOMParser and its parseFromSring() method.
What’s more, this method prevents the arbitrary JavaScript discussed earlier in the article.
We’ve used DOMParser.parseFromString() to remove the HTML tags from the string in the code below.
Example:
function stripHTMLTags(html) {
const parseHTML = new DOMParser().parseFromString(html, 'text/html');
return parseHTML.body.textContent || '';
}
let html = '<h1 class=\'header_tag\'>hello <i>world</i></h1>';
console.log(stripHTMLTags(html));
Output:
hello world
Meanwhile, DOMParser.parseFromString() will return an empty string for the arbitrary JavaScript code:
function stripHTMLTags(html) {
const parseHTML = new DOMParser().parseFromString(html, 'text/html');
return parseHTML.body.textContent || '';
}
let html =
'<img onerror=\'alert("Run dangerous JavaScript")\' src=nonexistence>';
console.log(stripHTMLTags(html));
Output:
<empty string>
Strip HTML Tags With String-Strip-HTML Package
The string-strip-html package is designed to strip HTML from a string. The package provides a stringStripHtml method that takes an HTML as an input.
Afterward, it’ll return a string that’s free of HTML tags. If the string contains the <script> element, string-strip-html will remove it and its content.
In the following code, we’ve passed an HTML string to the stringStripHtml method. This HTML string contains the <script> element.
However, it gets removed when you run the code in your web browser.
<body>
<script src="https://cdn.jsdelivr.net/npm/string-strip-html/dist/string-strip-html.umd.js"></script>
<script type="text/javascript">
const { stripHtml } = stringStripHtml;
let htmlWithScriptElement = '<script>alert("Hello world");<\/script>';
let html = `<h1 class='header_tag'>hello <i>world</i> ${htmlWithScriptElement}</h1>`;
console.log(stripHtml(html).result);
</script>
</body>
Output:
hello world

Habdul Hazeez is a technical writer with amazing research skills. He can connect the dots, and make sense of data that are scattered across different media.
LinkedIn