Tracer le graphique à l'aide de la fonction seaborn.lmplot()
Le module seaborn est utilisé pour créer des graphiques statistiques en Python. Il est construit sur le module matplotlib, il est donc très simple à utiliser.
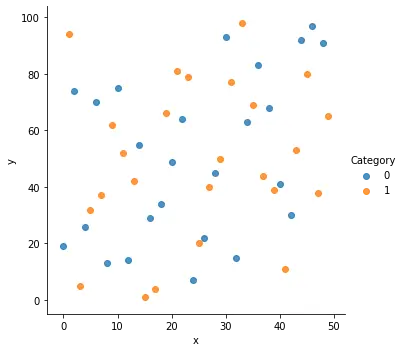
La fonction seaborn.lmplot() crée un nuage de points de base en utilisant les données fournies sur un FacetGrid.
Voir le code suivant.
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import random
x = range(50)
y = random.sample(range(100), 50)
cat = [i for i in range(2)] * 25
df = pd.DataFrame({"x": x, "y": y, "Category": cat})
sns.lmplot(x="x", y="y", data=df, fit_reg=False, hue="Category")
Cependant, l’utilisation de cette fonction dépasse le tracé des nuages de points. Il peut également être utilisé pour comprendre la relation entre les données en traçant une ligne de régression facultative dans le graphique. Il peut également être utilisé pour la régression logistique.
Contrairement à la fonction seaborn.regplot() qui est également utilisée pour effectuer une simple régression et tracer les données, la fonction seaborn.lmplot() combine la classe seaborn.FacetGrid() avec la classe seaborn.regplot() une fonction.
Le FacetGrid() est utilisé pour visualiser la relation entre la distribution des données avec d’autres sous-ensembles de données et peut être utilisé pour créer des grilles pour plusieurs parcelles. Il fonctionne sur trois axes fournissant des lignes, des colonnes et des teintes. C’est très utile lorsque nous travaillons avec un ensemble de données compliqué.
On peut aussi personnaliser la figure finale à l’aide des différents paramètres avec la fonction seaborn.lmplot(). Nous pouvons fournir les personnalisations nécessaires, comme la couleur du tracé, sous forme de paires clé-valeur d’un dictionnaire aux paramètres line_kws et scatter_kws.
Dans le code ci-dessous, nous tracerons un graphique avec une ligne de régression à l’aide de cette fonction.
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import random
x = range(50)
y = random.sample(range(100), 50)
cat = [i for i in range(2)] * 25
df = pd.DataFrame({"x": x, "y": y, "Category": cat})
sns.lmplot(x="x", y="y", data=df, hue="Category")
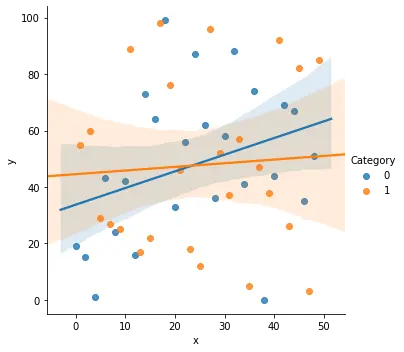
Notez que le paramètre fit_reg est défini sur True par défaut. Notre ensemble de données comportait plusieurs catégories, nous avons donc pu tracer plusieurs lignes de régression. Si nous avions supprimé le paramètre hue, alors un seul graphique de régression aurait été obtenu. Nous pouvons également utiliser de nombreux paramètres pour notre régression. Certains d’entre eux incluent l’argument jitter, qui est utilisé pour ajouter du bruit aux données, ou le paramètre estimator utilisé pour tracer une valeur estimée donnée.

Manav is a IT Professional who has a lot of experience as a core developer in many live projects. He is an avid learner who enjoys learning new things and sharing his findings whenever possible.
LinkedIn