Régression par morceaux dans R
La régression par morceaux est utilisée lorsqu’il existe des points d’arrêt clairs dans les données. Ce didacticiel montre comment effectuer une régression par morceaux dans R.
Régression par morceaux dans R
Lorsqu’il existe des points d’arrêt clairs dans les données, la régression qui fonctionnera sera la régression par morceaux. La régression par morceaux est le processus étape par étape comme illustré ci-dessous :
-
Créez le bloc de données.
-
Ajustez le modèle de régression linéaire aux données. Nous pouvons le faire en utilisant la méthode
lm(). -
Ajustez le modèle de régression par morceaux. La méthode
segmented()est utilisée à partir du packagesegmentedpour ajuster le modèle de régression par morceaux. -
Visualisez le modèle de régression final par morceaux en utilisant la méthode
plot().
Essayons maintenant un exemple en utilisant les étapes ci-dessus. Voir exemple :
#Step 1
#create the DataFrame
data<-read.table(text="
Year Stopped
2015 973
2016 1025
2017 1151
2018 1384
2019 4507
2020 15557
", header=T, sep="")
#first six rows of the data frame
head(data)
#Step2
#fit the simple linear regression model
dput(names(data))
q.lm <- lm(log(Stopped) ~ Year, data)
summary(q.lm)
#Step3
#fit the piecewise regression model to original model,
#estimating a breakpoint at x=14
install.packages('segmented')
library(segmented)
o <- segmented(q.lm, seg.Z = ~Year, psi = 2018)
# view the summary
summary(o)
#Step4
# visulize the piecewise regression model
plot(o)
points(log(Stopped) ~ Year, data)
Le code ci-dessus crée un modèle de régression par morceaux pour les personnes qui ont arrêté leurs études au cours de différentes années. Le code a quelques sorties, qui sont décrites ci-dessous :
Le résultat de l’étape 1 :
Year Stopped
1 2015 973
2 2016 1025
3 2017 1151
4 2018 1384
5 2019 4507
6 2020 15557
Il montre la tête des données.
Le résultat de l’étape 2 :
Call:
lm(formula = log(Stopped) ~ Year, data = data)
Residuals:
1 2 3 4 5 6
0.50759 0.03146 -0.38079 -0.72463 -0.07216 0.63853
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -1057.9257 279.3081 -3.788 0.0193 *
Year 0.5282 0.1384 3.815 0.0189 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.5791 on 4 degrees of freedom
Multiple R-squared: 0.7844, Adjusted R-squared: 0.7305
F-statistic: 14.56 on 1 and 4 DF, p-value: 0.01886
Cela montre le résumé du modèle de régression linéaire.
Le résultat de l’étape 3 :
***Regression Model with Segmented Relationship(s)***
Call:
segmented.lm(obj = q.lm, seg.Z = ~Year, psi = 2018)
Estimated Break-Point(s):
Est. St.Err
psi1.Year 2017.91 0.039
Meaningful coefficients of the linear terms:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -162.39260 35.56716 -4.566 0.0448 *
Year 0.08400 0.01764 4.761 0.0414 *
U1.Year 1.12577 0.02495 45.121 NA
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.02495 on 2 degrees of freedom
Multiple R-Squared: 0.9998, Adjusted R-squared: 0.9995
Boot restarting based on 6 samples. Last fit:
Convergence attained in 1 iterations (rel. change 3.7909e-16)
Cela correspond au modèle de régression par morceaux et affiche le résumé du modèle. Le modèle détecte un point de rupture en 2017.91.
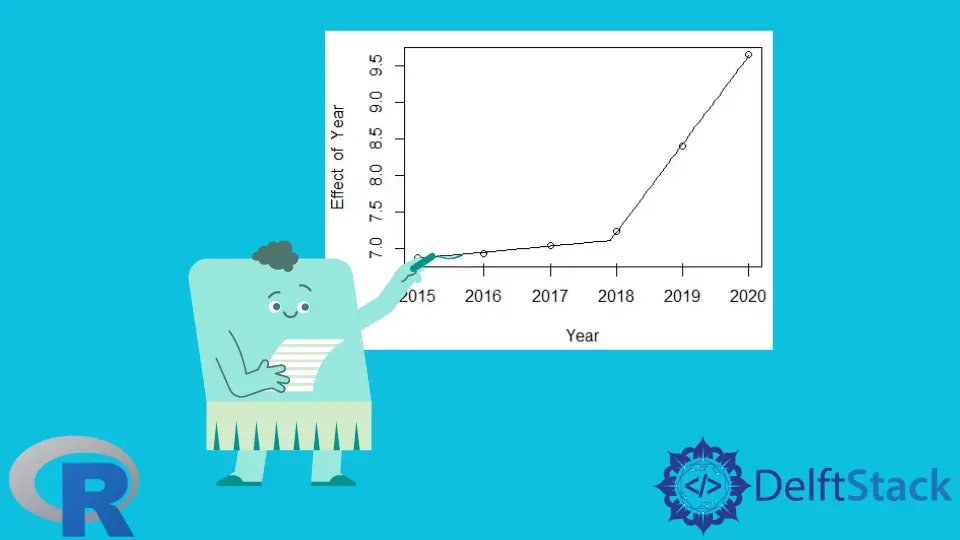
Le résultat de l’étape 4 :

Il visualise le modèle de régression par morceaux. Le graphique montre que le modèle de régression par morceaux correspond assez bien aux données données.

Sheeraz is a Doctorate fellow in Computer Science at Northwestern Polytechnical University, Xian, China. He has 7 years of Software Development experience in AI, Web, Database, and Desktop technologies. He writes tutorials in Java, PHP, Python, GoLang, R, etc., to help beginners learn the field of Computer Science.
LinkedIn Facebook