Régression linéaire en Python
- Qu’est-ce que la régression ?
- Qu’est-ce que la régression linéaire ?
- Implémentation de la régression linéaire simple en Python
- Implémentation de la régression multiple en Python
Dans cet article, nous discuterons de la régression linéaire et verrons comment la régression linéaire est utilisée pour prédire les résultats. Nous allons également implémenter une régression linéaire simple et une régression multiple en Python.
Qu’est-ce que la régression ?
La régression est le processus d’identification des relations entre les variables indépendantes et les variables dépendantes. Il est utilisé pour prédire les prix des maisons, les salaires des employés et d’autres applications de prévision.
Si nous voulons prédire les prix des maisons, les variables indépendantes peuvent inclure l’âge de la maison, le nombre de chambres, la distance des lieux centraux de la ville comme les aéroports, les marchés, etc. Ici, le prix de la maison dépendra de ces variables indépendantes. Le prix de la maison est donc une variable dépendante.
De même, si nous voulons prédire le salaire des employés, les variables indépendantes pourraient être leur expérience en années, leur niveau d’éducation, le coût de la vie du lieu où ils résident, etc. Ici, la variable dépendante est le salaire des employés.
Avec la régression, nous essayons d’établir un modèle mathématique décrivant comment les variables indépendantes affectent les variables dépendantes. Le modèle mathématique doit prédire la variable dépendante avec le moins d’erreur lorsque les valeurs des variables indépendantes sont fournies.
Qu’est-ce que la régression linéaire ?
Dans la régression linéaire, les variables indépendantes et dépendantes sont supposées être liées linéairement.
Supposons que l’on nous donne N variables indépendantes comme suit.
Maintenant, nous devons trouver une relation linéaire comme l’équation suivante.
Ici,
- Il faut identifier les constantes
Aipar régression linéaire pour prédire la variable dépendanteF(X)avec un minimum d’erreurs lorsque les variables indépendantes sont données. - Les constantes Ai sont appelées poids prédits ou estimateurs des coefficients de régression.
- F(X) est appelée la réponse prédite ou la réponse estimée de la régression. Pour un
X=( X1, X2, X3, X4, X5, X6, X7……, XN)donné,F(X)doit donner une valeur aussi proche que possible de la variable dépendante réelle Y pour la variable indépendante donnée X. - Pour calculer la fonction F(X) qui s’évalue à la valeur Y la plus proche, nous minimisons normalement la racine carrée moyenne de la différence entre F(X) et Y pour des valeurs données de X.
Implémentation de la régression linéaire simple en Python
Il n’y a qu’une seule variable indépendante et une variable dépendante dans la régression simple. Ainsi, la réponse prédite peut être écrite comme suit.
Pour implémenter la régression linéaire simple en Python, nous avons besoin de certaines valeurs réelles pour X et de leurs valeurs Y correspondantes. Avec ces valeurs, nous pouvons calculer mathématiquement les poids prédits A0 et A1 ou en utilisant les fonctions fournies en Python.
Supposons que l’on nous donne dix valeurs pour X sous la forme d’un tableau comme suit.
X = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
De plus, les valeurs Y correspondantes sont données comme suit.
Y = [2, 4, 3, 6, 8, 9, 9, 10, 11, 13]
Pour trouver l’équation de régression F(X), on peut utiliser le module linear_model de la bibliothèque d’apprentissage automatique scikit-learn. Vous pouvez installer la bibliothèque scikit-learn en exécutant la commande suivante dans l’invite de commande de votre machine.
pip3 install scikit-learn
Le module linear_model de la bibliothèque scikit-learn nous fournit la méthode LinearRegression() que nous pouvons utiliser pour trouver la réponse prédite. La méthode LinearRegression(), lorsqu’elle est exécutée, renvoie un modèle linéaire. Nous pouvons former ce modèle linéaire pour trouver F(X). Pour cela, nous utilisons la méthode fit().
La méthode fit(), lorsqu’elle est invoquée sur un modèle linéaire, accepte le tableau de variables indépendantes X comme premier argument et le tableau de variables dépendantes Y comme deuxième argument d’entrée. Après exécution, les paramètres du modèle linéaire sont ajustés de manière à ce que le modèle représente F(X). Vous pouvez trouver les valeurs pour A0 et A1 en utilisant respectivement les attributs intercept_ et coef_, comme indiqué ci-dessous.
from sklearn import linear_model
import numpy as np
X = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]).reshape(-1, 1)
Y = [2, 4, 3, 6, 8, 9, 9, 10, 11, 13]
lm = linear_model.LinearRegression()
lm.fit(X, Y) # fitting the model
print("The coefficient is:", lm.coef_)
print("The intercept is:", lm.intercept_)
Production :
The coefficient is: [1.16969697]
The intercept is: 1.0666666666666664
Ici, vous pouvez voir que la valeur du coefficient A1 est 1,16969697 et la valeur d’interception A0 est 1,0666666666666664.
Après avoir implémenté le modèle de régression linéaire, vous pouvez prédire la valeur de Y pour tout X en utilisant la méthode predict(). Lorsqu’elle est invoquée sur un modèle, la méthode predict() prend la variable indépendante X comme argument d’entrée et renvoie la valeur prédite pour la variable dépendante Y, comme illustré dans l’exemple suivant.
from sklearn import linear_model
import numpy as np
X = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]).reshape(-1, 1)
Y = [2, 4, 3, 6, 8, 9, 9, 10, 11, 13]
lm = linear_model.LinearRegression()
lm.fit(X, Y) # fitting the model
Z = np.array([1, 5, 15, 56, 27]).reshape(-1, 1)
print("The input values are:", Z)
output = lm.predict(Z)
print("The predicted values are:", output)
Production :
The input values are: [[ 1]
[ 5]
[15]
[56]
[27]]
The predicted values are: [ 2.23636364 6.91515152 18.61212121 66.56969697 32.64848485]
Ici, vous pouvez voir que nous avons fourni différentes valeurs de X à la méthode predict() et qu’elle a renvoyé la valeur prédite correspondante pour chaque valeur d’entrée.
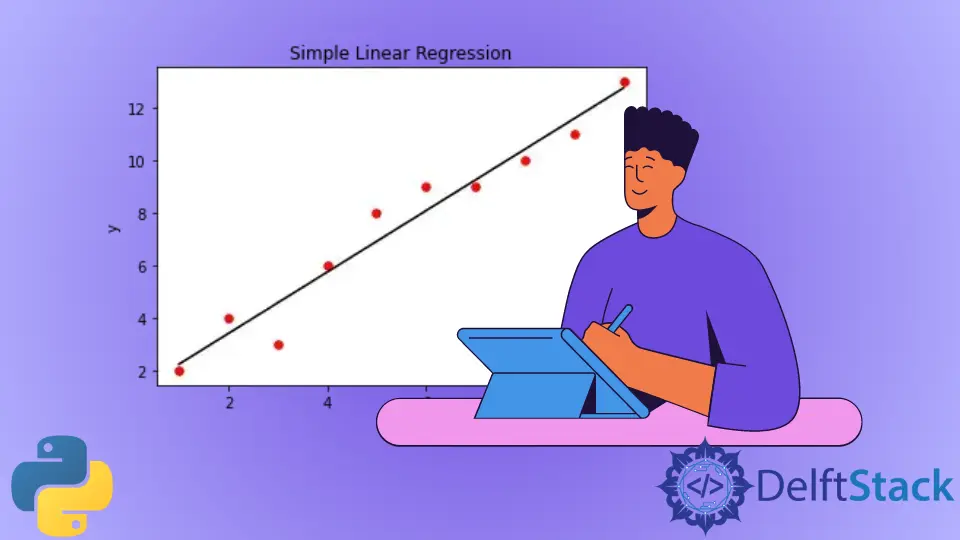
Nous pouvons visualiser le modèle de régression linéaire simple à l’aide de la fonction de bibliothèque matplotlib. Pour cela, nous créons d’abord un nuage de points des valeurs X et Y réelles fournies en entrée. Après avoir créé le modèle de régression linéaire, nous allons tracer la sortie du modèle de régression par rapport à X en utilisant la méthode predict(). Cela nous donnera une ligne droite représentant le modèle de régression, comme indiqué ci-dessous.
from sklearn import linear_model
import numpy as np
import matplotlib.pyplot as plt
X = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]).reshape(-1, 1)
Y = [2, 4, 3, 6, 8, 9, 9, 10, 11, 13]
lm = linear_model.LinearRegression()
lm.fit(X, Y)
plt.scatter(X, Y, color="r", marker="o", s=30)
y_pred = lm.predict(X)
plt.plot(X, y_pred, color="k")
plt.xlabel("x")
plt.ylabel("y")
plt.title("Simple Linear Regression")
plt.show()
Production :

Implémentation de la régression multiple en Python
Dans la régression multiple, nous avons plus d’une variable indépendante. Par exemple, supposons qu’il y ait deux variables indépendantes X1 et X2, et leur variable dépendante Y donnée comme suit.
X1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
X2 = [5, 7, 7, 8, 9, 9, 10, 11, 12, 13]
Y = [5, 7, 6, 9, 11, 12, 12, 13, 14, 16]
Ici, chaque ième valeur dans X1, X2 et Y forme un triplet où le ième élément du tableau Y est déterminé en utilisant le ième élément du tableau X1 et le ième élément du tableau X2.
Pour implémenter la régression multiple en Python, nous allons créer un tableau X à partir de X1 et X2 comme suit.
X1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
X2 = [5, 7, 7, 8, 9, 9, 10, 11, 12, 13]
X = [
(1, 5),
(2, 7),
(3, 7),
(4, 8),
(5, 9),
(6, 9),
(7, 10),
(8, 11),
(9, 12),
(10, 13),
]
Pour créer X à partir de X1 et X2, nous allons utiliser la méthode zip(). La méthode zip() prend différents objets itérables en entrée et renvoie un itérateur contenant les éléments appariés. Comme indiqué ci-dessous, nous pouvons convertir l’itérateur en une liste en utilisant le constructeur list().
X1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
X2 = [5, 7, 7, 8, 9, 9, 10, 11, 12, 13]
print("X1:", X1)
print("X2:", X2)
X = list(zip(X1, X2))
print("X:", X)
Production :
X1: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
X2: [5, 7, 7, 8, 9, 9, 10, 11, 12, 13]
X: [(1, 5), (2, 7), (3, 7), (4, 8), (5, 9), (6, 9), (7, 10), (8, 11), (9, 12), (10, 13)]
Après avoir obtenu X, il faut trouver F(X)= A0+A1X1+A2X2.
Pour cela, nous pouvons passer la matrice de caractéristiques X et le tableau de variables dépendantes Y à la méthode fit(). Lorsqu’elle est exécutée, la méthode fit() ajuste les constantes A0, A1 et A2 de sorte que le modèle représente le modèle de régression multiple F(X). Vous pouvez trouver les valeurs A1 et A2 en utilisant l’attribut coef_ et la valeur A0 en utilisant l’attribut intercept_ comme indiqué ci-dessous.
from sklearn import linear_model
import numpy as np
X1 = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
X2 = np.array([5, 7, 7, 8, 9, 9, 10, 11, 12, 13])
Y = [5, 7, 6, 9, 11, 12, 12, 13, 14, 16]
X = list(zip(X1, X2))
lm = linear_model.LinearRegression()
lm.fit(X, Y) # fitting the model
print("The coefficient is:", lm.coef_)
print("The intercept is:", lm.intercept_)
Production :
The coefficient is: [0.72523364 0.55140187]
The intercept is: 1.4934579439252396
Ici, vous pouvez voir que le coefficient est un tableau. Le premier élément du tableau représente A1 tandis que le deuxième élément du tableau représente A2. L’interception représente A0
Après avoir formé le modèle, vous pouvez prédire la valeur de Y pour n’importe quelle valeur de X1, X2 comme suit.
from sklearn import linear_model
import numpy as np
X1 = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
X2 = np.array([5, 7, 7, 8, 9, 9, 10, 11, 12, 13])
Y = [5, 7, 6, 9, 11, 12, 12, 13, 14, 16]
X = list(zip(X1, X2))
lm = linear_model.LinearRegression()
lm.fit(X, Y) # fitting the model
Z = [(1, 3), (1, 5), (4, 9), (4, 8)]
print("The input values are:", Z)
output = lm.predict(Z)
print("The predicted values are:", output)
Production :
The input values are: [(1, 3), (1, 5), (4, 9), (4, 8)]
The predicted values are: [3.8728972 4.97570093 9.35700935 8.80560748]

Aditya Raj is a highly skilled technical professional with a background in IT and business, holding an Integrated B.Tech (IT) and MBA (IT) from the Indian Institute of Information Technology Allahabad. With a solid foundation in data analytics, programming languages (C, Java, Python), and software environments, Aditya has excelled in various roles. He has significant experience as a Technical Content Writer for Python on multiple platforms and has interned in data analytics at Apollo Clinics. His projects demonstrate a keen interest in cutting-edge technology and problem-solving, showcasing his proficiency in areas like data mining and software development. Aditya's achievements include securing a top position in a project demonstration competition and gaining certifications in Python, SQL, and digital marketing fundamentals.
GitHub