Cinta de degradado TensorFlow
TensorFlow ha desempeñado un papel vital al ser un marco coherente y una zona de trabajo compatible para el campo del aprendizaje automático dinámico y el aprendizaje profundo.
Uno de los dominios más publicitados es la red neuronal, y su principio de funcionamiento se puede demostrar fácilmente con la ayuda del algoritmo de descenso de gradiente. Y TensorFlow asegura casi todas las bibliotecas necesarias para mejorar esta experiencia.
De acuerdo con el concepto básico, la red neuronal es cómo opera, decide, reconoce y funciona la célula del cerebro humano. Nuestra unidad de procesamiento solo puede memorizar la información alimentada a la vez.
Más bien, sigue una tasa de aprendizaje y se revisa de forma consecutiva en función del manejo de situaciones. En este proceso, existe un término importante llamado función de costo o función de pérdida o derivada parcial o el término básico gradiente.
Para visualizar el concepto, hemos tratado de demostrar un concepto común, el modelo de “Regresión Lineal”. Si no es un novato en el aprendizaje automático, asumimos que ya está familiarizado con él.
Lo que hace este modelo es extraer una relación entre las variables independientes y dependientes con la ayuda de una línea de regresión.
Al establecer la línea de regresión, se requiere conocer la suma de errores cuadráticos (SSE), que es el gradiente para este caso particular. Esperamos que el SSE sea el mínimo cuando entrenamos nuestro modelo.
El proceso constante sólo aprovecha esto del entrenamiento. Aquí, calculamos la salida de nuestra ecuación especificada y reinicializamos los valores del controlador con la tasa de aprendizaje de gradiente x.
La tasa de aprendizaje asegura la estabilidad para que nuestra función de pérdida no muestre consecuencias abruptas.
Actualizaremos los valores base según los gradientes después de iniciar un valor base. Este pase hacia atrás es necesario para verificar si el modelo fue entrenado correctamente.
Y la cinta de gradiente es precisamente ese componente que almacena sucesivamente la función de coste junto con las entradas y salidas actualizadas. Entonces obtenemos una imagen completa de todo el procedimiento con el detalle de los valores.
Visualicemos el método con un ejemplo.
Uso de Gradient Tape en TensorFlow
En esta sección no haremos un resumen teórico. Más bien, daremos seguimiento a los códigos prácticos e intentaremos demostrar cómo nos basamos en la cinta de degradado.
Entonces, saltemos a las bases del código. Estamos usando Google Colab para nuestra instancia.
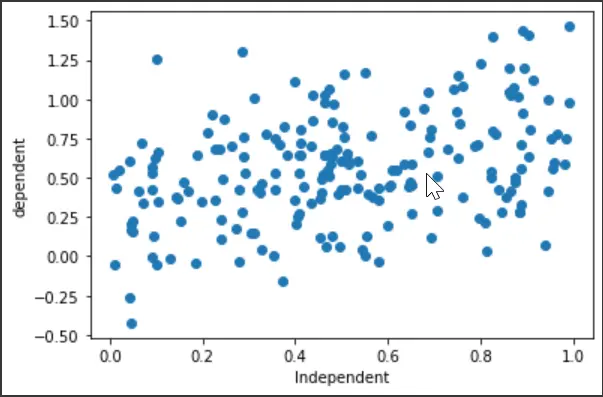
Inicialmente, configuraremos las importaciones de la biblioteca y generaremos un conjunto de datos aleatorio para la unidad. También trazaremos un diagrama de dispersión para ver cómo se comportan las variables.
# Necessary Imports
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import os
# Generating random data
x = np.random.uniform(0.0, 1.0, (200))
y = 0.3 + 0.5 * x + np.random.normal(0.0, 0.3, len(x))
# x
# y
plt.scatter(x, y)
plt.xlabel("Independent")
plt.ylabel("dependent")
plt.show()
Producción:
Las próximas vallas de código incluirán el modelo de regresión y la declaración de funciones de pérdida. La parte importante en la que centrarse es que el modelo de regresión genera el valor predicho para la variable dependiente y, y la ecuación es así:
Aquí, x es la variable independiente, también conocida como la entrada del modelo. Principalmente, intentaremos ver si tenemos el mínimo error entre la y dada y la y^ pronosticada.
La función de pérdida incluye la suma del error cuadrático (SSE):
# The following equation for the model is ----> y" = a + b * x
# Linear Regression
class regression:
def __init__(self):
self.a = tf.Variable(initial_value=0, dtype=tf.float32)
self.b = tf.Variable(initial_value=0, dtype=tf.float32)
def __call__(self, x):
x = tf.convert_to_tensor(x, dtype=tf.float32)
y_est = tf.add(self.a, tf.multiply(self.b, x))
return y_est
model = regression()
# The loss function/ Cost function/ Optimization function (sum of square error)
def loss_func(y_true, y_pred):
# both y_true and y_pred are tensors
sse = tf.reduce_sum(tf.square(tf.subtract(y_true, y_pred)))
return sse
A continuación, definiremos la sección de entrenamiento, incluida la cinta de degradado. La ecuación para actualizar las variables a y b son:
# Gradient Descent ----> a = ai - sse * lr (learning rate)
# b = bi - sse * lr
def train(model, inputs, outputs, lr):
# convert outputs to tensor
y_true = tf.convert_to_tensor(outputs, dtype=tf.float32)
# Gradient Tape
with tf.GradientTape() as g:
y_pred = model(inputs)
current_loss = loss_func(y_true, y_pred)
# slopes/ partal_differentiation/ gradients
da, db = g.gradient(current_loss, [model.a, model.b])
# update values
model.a.assign_sub(da * lr)
model.b.assign_sub(db * lr)
El siguiente segmento es establecer la línea de regresión. Fijaremos unas épocas para un mejor aprendizaje.
Hemos examinado el punto de saturación y el valor de época necesario para el cual la función de pérdida es mínima. Grafiquemos los valores de época y costo para ver cómo se produjo el resultado de toda la sección de capacitación.
# Fitting
def plotting(x, y):
plt.scatter(x, y) # scatter
plt.plot(x, model(x), "r--")
model = regression()
a_val = []
b_val = []
cost_val = []
# epochs
epochs = 70
# learning rate
lr = 0.001
for e in range(epochs):
a_val.append(model.a)
b_val.append(model.b)
# prediction values and errors
y_pred = model(x)
cost_value = loss_func(y, y_pred)
cost_val.append(cost_value)
# Train
train(model, x, y, lr)
plotting(x, y)
plt.show()
print("Epoch: %d, Loss: %0.2f" % (e, cost_value))
El diagrama de dispersión de salida de la última época:

plt.plot(cost_val)
plt.xlabel("epochs")
plt.ylabel("cost values")
Producción:

Entonces, se puede decir que los valores de costo se redujeron drásticamente en el rango de época de 0-10. Y cuando ejecute todas las épocas, notará con los valores que el punto saturado está cerca de la época 64-65.
Técnicamente, la cinta de gradiente ayudó a recopilar todos los valores correspondientes y, por lo tanto, la visualización es más intuitiva. También puede obtener una vista previa del código completo en este enlace.
