Trace el gráfico utilizando la función seaborn.lmplot()
El módulo seaborn se utiliza para crear gráficos estadísticos en Python. Está construido sobre el módulo matplotlib, por lo que es muy sencillo de usar.
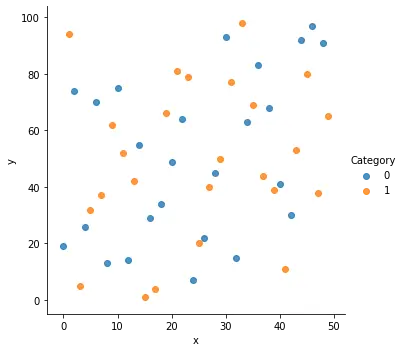
La función seaborn.lmplot() crea un diagrama de dispersión básico usando los datos dados en un FacetGrid.
Consulte el siguiente código.
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import random
x = range(50)
y = random.sample(range(100), 50)
cat = [i for i in range(2)] * 25
df = pd.DataFrame({"x": x, "y": y, "Category": cat})
sns.lmplot(x="x", y="y", data=df, fit_reg=False, hue="Category")
Sin embargo, el uso de esta función excede el trazado de diagramas de dispersión. También se puede utilizar para comprender la relación entre los datos trazando una línea de regresión opcional en el gráfico. También se puede utilizar para regresiones logísticas.
A diferencia de la función seaborn.regplot() que también se utiliza para realizar regresiones simples y trazar los datos, la función seaborn.lmplot() combina la clase seaborn.FacetGrid() con la clase seaborn.regplot()Función.
El FacetGrid() se utiliza para visualizar la relación entre la distribución de datos con otros subconjuntos de datos y se puede utilizar para crear cuadrículas para múltiples gráficos. Funciona en tres ejes que proporcionan filas, columnas y matices. Es muy útil cuando trabajamos con un conjunto de datos complicado.
También podemos personalizar la figura final utilizando los diferentes parámetros con la función seaborn.lmplot(). Podemos proporcionar las personalizaciones necesarias, como el color del gráfico, como pares clave-valor de un diccionario para los parámetros line_kws y scatter_kws.
En el siguiente código, trazaremos un gráfico con una línea de regresión usando esta función.
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import random
x = range(50)
y = random.sample(range(100), 50)
cat = [i for i in range(2)] * 25
df = pd.DataFrame({"x": x, "y": y, "Category": cat})
sns.lmplot(x="x", y="y", data=df, hue="Category")
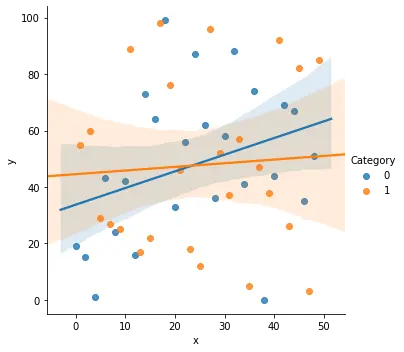
Tenga en cuenta que el parámetro fit_reg está establecido en True de forma predeterminada. Nuestro conjunto de datos tenía múltiples categorías, por lo que pudimos trazar múltiples líneas de regresión. Si hubiéramos eliminado el parámetro hue, se habría obtenido una única gráfica de regresión. También podemos usar muchos parámetros para nuestra regresión. Algunos de estos incluyen el argumento jitter, que se utiliza para añadir algo de ruido a los datos, o el parámetro estimator utilizado para graficar sobre un valor estimado dado.

Manav is a IT Professional who has a lot of experience as a core developer in many live projects. He is an avid learner who enjoys learning new things and sharing his findings whenever possible.
LinkedIn