Parcela de conteo marino
Este artículo analiza el gráfico de recuento de Seaborn y la diferencia entre el gráfico de recuento y el gráfico de barras. También veremos las opciones de Python disponibles para la función countplot() de Seaborn.
Usa la función countplot() en Seaborn
El countplot() es una forma de contar el número de observaciones que tiene por categoría y luego mostrar esa información en barras. Puede considerarlo un histograma, pero para datos categóricos, es un gráfico muy simple y muy útil, especialmente cuando se realizan análisis de datos exploratorios en Python.
Consulte la función countplot() en la biblioteca de Seaborn. Primero, importaremos la biblioteca de Seaborn y cargaremos algunos datos de la biblioteca de Seaborn sobre diamantes.
import seaborn as sb
Data_DM = sb.load_dataset("diamonds")
Data_DM.head()
Cada fila de este conjunto de datos contiene información sobre un diamante en particular.

Lo reduciremos utilizando clarity.isin a SI1 y VS2, por lo que tenemos una categoría con solo dos opciones.
Data_DM = Data_DM[Data_DM.clarity.isin(["SI1", "VS2"])]
Data_DM.shape
Una vez que reducimos todo, tenemos alrededor de 25323 diamantes diferentes en este conjunto de datos.
(25323, 10)
Ahora estamos listos para crear nuestra primera gráfica de conteo. Para hacerlo, haremos referencia a la biblioteca Seaborn, llamaremos a la función countplot() y pasaremos la columna que nos gustaría trazar.
Trazaremos la columna color, y estos datos provienen de nuestro marco de datos Data_DM.
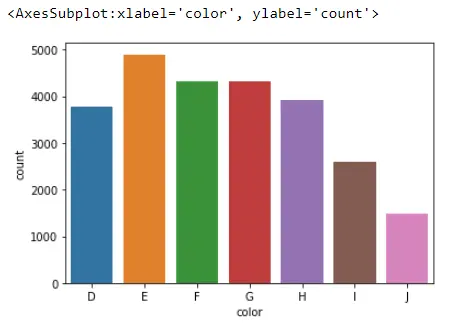
sb.countplot(x="color", data=Data_DM)
Lo que hace esto con este gráfico es contar el número de observaciones que tenemos para cada categoría que encuentra en la columna color. Por ejemplo, Seaborn encontró alrededor de 1500 diamantes con un color igual a J.
Si aplicamos value_counts() a la columna color:
Data_DM.color.value_counts(sort=False)
Estos números son los que trazamos cuando usamos la función countplot().
D 3780
E 4896
F 4332
G 4323
H 3918
I 2593
J 1481
Name: color, dtype: int64
Una cosa buena de Seaborn countplot() es que podemos cambiar fácilmente de barras verticales a horizontales. Todo lo que tenemos que hacer es cambiar esta x en una y.
sb.countplot(y="color", data=Data_DM)
Producción:

Diagrama de barras de Seaborn vs. Diagrama de conteo
Entonces, en este punto, puede pensar que el gráfico de recuento de Seaborn se parece mucho al gráfico de barras. Pero hay una gran diferencia: con el gráfico de recuento de Seaborn, solo estamos contando el número de observaciones por categoría.
Con el gráfico de barras de Seaborn, obtenemos una estimación de algunas estadísticas resumidas por categoría. Por ejemplo, podríamos tener el promedio por categoría y obtener los intervalos de confianza de esto; por eso se utiliza un gráfico de barras.
El argumento del orden
Se utilizan para dos cosas diferentes; sin embargo, las opciones de codificación están disponibles en ambos gráficos. Veamos algunas de esas opciones en el código de Seaborn.
Para la primera opción, hablemos del orden en esas barras que aparecen en el gráfico anterior. Si observamos nuestro gráfico de conteo para el color de esos diamantes, veremos que las barras no están actualmente ordenadas según el más popular al menos popular.
Están ordenados alfabéticamente de la D a la J.
sb.countplot(x="cut", data=Data_DM)
Pero, si nos fijamos en otra columna llamada corte, veremos que las barras ya no están ordenadas alfabéticamente.

No está claro al principio cómo Seaborn organiza estos bares; podemos recorrer el proceso. Observamos los tipos de datos de las columnas diamantes y notamos que tenemos varios float64, int64 y categorías.
Data_DM.dtypes
Estas tres columnas se consideran los tipos de datos de categoría. corte, color y claridad son todas categorías.
carat float64
cut category
color category
clarity category
depth float64
table float64
price int64
x float64
y float64
z float64
dtype: object
Veamos qué significa. Para comprobar el color, tenemos esta propiedad llamada categorías.
Data_DM.color.cat.categories
Esto es lo que usa Seaborn para alinear esas barras.
Index(['D', 'E', 'F', 'G', 'H', 'I', 'J'], dtype='object')
Por lo general, las columnas de “categoría” vendrán con esta propiedad llamada “categorías”, y Seaborn usará esto para averiguar cómo debe alinear esas barras.
Data_DM.cut.cat.categories
Producción :
Index(['Ideal', 'Premium', 'Very Good', 'Good', 'Fair'], dtype='object')
En el primero, nos alineamos alfabéticamente, pero en el segundo, nos alineamos según los mejores diamantes primero y hasta los peores diamantes.
Pero, ¿y si el orden de esa categoría no es como nos gustaría que aparecieran esas barras? La función countplot() de Seaborn tiene un argumento llamado order, y podemos pasar una lista de cómo nos gustaría ordenar esas barras.
ord_of_c = ["J", "I", "H", "G", "F", "E", "D"]
sb.countplot(x="color", data=Data_DM, order=ord_of_c)
Producción:

También podemos ordenar estas barras en orden ascendente o descendente ya que se trata de un marco de datos de Pandas, por lo que recomendamos utilizar el método value_counts(). Esto ordenará nuestras barras de las más populares a las menos populares.
Si seguimos adelante y tomamos el índice, veríamos que la categoría más popular es E y hasta la categoría menos popular, J.
Data_DM.color.value_counts().index
Producción :
CategoricalIndex(['E', 'F', 'G', 'H', 'D', 'I', 'J'], categories=['D', 'E', 'F', 'G', 'H', 'I', 'J'], ordered=False, dtype='category')
Podemos usar este índice cuando creamos nuestro pedido para nuestras barras. Ahora los tenemos ordenados en orden descendente.
Pero si preferimos tenerlos ordenados de forma ascendente.
Todo lo que tenemos que hacer es invertir este índice, lo que podemos hacer con dos dos puntos y uno negativo que cambiará el índice por completo.
sb.countplot(x="color", data=Data_DM, order=Data_DM.color.value_counts().index[::-1])
Producción:

Puede encontrar más opciones cuando visite aquí.
Código completo:
# In[1]:
import seaborn as sb
Data_DM = sb.load_dataset("diamonds")
Data_DM.head()
# In[2]:
Data_DM = Data_DM[Data_DM.clarity.isin(["SI1", "VS2"])]
Data_DM.shape
# In[3]:
sb.countplot(x="color", data=Data_DM)
# In[4]:
Data_DM.color.value_counts(sort=False)
# In[5]:
sb.countplot(y="color", data=Data_DM)
# In[6]: order argument
sb.countplot(x="cut", data=Data_DM)
# In[7]:
Data_DM.dtypes
# In[8]:
Data_DM.color.cat.categories
# In[9]:
Data_DM.cut.cat.categories
# In[10]:
ord_of_c = ["J", "I", "H", "G", "F", "E", "D"]
sb.countplot(x="color", data=Data_DM, order=ord_of_c)
# In[11]:
Data_DM.color.value_counts().index
# In[12]:
sb.countplot(x="color", data=Data_DM, order=Data_DM.color.value_counts().index[::-1])

Hello! I am Salman Bin Mehmood(Baum), a software developer and I help organizations, address complex problems. My expertise lies within back-end, data science and machine learning. I am a lifelong learner, currently working on metaverse, and enrolled in a course building an AI application with python. I love solving problems and developing bug-free software for people. I write content related to python and hot Technologies.
LinkedIn