Regresión Logística en R
La regresión logística es un modelo en el que la variable respuesta tiene valores como True, False, o 0, 1, que son valores categóricos. Mide la probabilidad de una respuesta binaria.
Este tutorial demostrará cómo realizar una regresión logística en R.
Regresión Logística en R
El método glm() se usa en R para crear un modelo de regresión. Toma tres parámetros.
Primero está la fórmula, que es el símbolo que representa la relación entre variables; el segundo es el dato, que es el conjunto de datos que contiene los valores de estas variables; y tercero es la familia, que es el objeto R que especifica los detalles del modelo. Para la regresión logística, el valor es binomial.
La expresión matemática para la regresión logística se da a continuación:
y = 1/(1+e^-(a+b1x1+b2x2+b3x3+...))
Dónde:
aybson las constantes numéricas que son coeficientesyes la variable de respuestaxes la variable predictora
Pasos para realizar una regresión logística en R
Ahora realicemos una regresión logística en R. Este es el proceso paso a paso.
Cargar los datos
Usemos el conjunto de datos predeterminado del paquete ISLR. Primero, necesitamos instalar el paquete si aún no está instalado.
install.packages('ISLR')
Una vez que el paquete se haya instalado correctamente, el siguiente paso es cargar los datos.
require(ISLR)
#load the dataset
data_set <- ISLR::Default
## The total observations in data
nrow(data_set)
#the summary of the dataset
summary(data_set)
El código cargará el conjunto de datos predeterminado de ISLR y mostrará el número de observaciones y el resumen de datos.
Producción :
[1] 10000
default student balance income
No :9667 No :7056 Min. : 0.0 Min. : 772
Yes: 333 Yes:2944 1st Qu.: 481.7 1st Qu.:21340
Median : 823.6 Median :34553
Mean : 835.4 Mean :33517
3rd Qu.:1166.3 3rd Qu.:43808
Max. :2654.3 Max. :73554
El conjunto de datos anterior contiene 10000 individuos.
El predeterminado muestra si el individuo está en incumplimiento o no, y el estudiante indica si el individuo es un estudiante. El saldo significa el saldo promedio de un individuo, y el ingreso es el ingreso del individuo.
Entrenar y probar muestras
El siguiente paso es dividir el conjunto de datos en un conjunto de entrenamiento y prueba para entrenar y probar el modelo.
#this will make the example reproducible
set.seed(1)
# We use 70% as training and 30% as testing set
sample <- sample(c(TRUE, FALSE), nrow(data), replace=TRUE, prob=c(0.7,0.3))
train <- data_set[sample, ]
test <- data_set[!sample, ]
Crear el modelo de regresión logística
Usamos glm() para crear el modelo de regresión logística con familia = binomial.
# the logistic regression model
logistic_model <- glm(default~student+balance+income, family="binomial", data=train)
# just disable scientific notation for summary
options(scipen=999)
# model summary
summary(logistic_model)
El código anterior crea un modelo de regresión logística y muestra el resumen del modelo a partir de los datos anteriores.
Producción :
Deviance Residuals:
Min 1Q Median 3Q Max
-2.4881 -0.1327 -0.0509 -0.0176 3.5912
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -10.961385538 0.602044982 -18.207 < 0.0000000000000002 ***
studentYes -0.835485760 0.284855225 -2.933 0.00336 **
balance 0.005893470 0.000289649 20.347 < 0.0000000000000002 ***
income -0.000001611 0.000009942 -0.162 0.87124
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1997.4 on 7014 degrees of freedom
Residual deviance: 1050.9 on 7011 degrees of freedom
AIC: 1058.9
Number of Fisher Scoring iterations: 8
El modelo de regresión logística se ha creado correctamente. Luego, el siguiente paso es usar el modelo para hacer predicciones.
Usa el modelo para hacer predicciones
Una vez que se ajusta el modelo de regresión logística, podemos usarlo para predecir si el individuo estará en default en función del estado de “ingresos”, “estudiante” o “saldo”.
#defining two individuals
demo <- data.frame(balance = 1500, income = 3000, student = c("Yes", "No"))
#predict the probability of defaulting
predict(logistic_model, demo, type="response")
El código anterior predice la probabilidad de incumplimiento de dos individuos definidos.
Producción :
1 2
0.04919576 0.10659389
La probabilidad de que un individuo incumpla con un saldo de $1500, ingresos de $3000 y estatus de estudiante de sí es 0.0491. Lo mismo con un estado de estudiante de no, la probabilidad de default es 0.1065.
Ahora calculemos la probabilidad de incumplimiento de cada individuo en nuestro conjunto de datos de prueba.
#probability of default for the test dataset
prediction <- predict(logistic_model, test, type="response")
El código calculará la probabilidad de incumplimiento para cada individuo en nuestro conjunto de datos de prueba. La salida será una gran suma de datos.
El diagnóstico del modelo de regresión logística
Ahora es el momento de verificar qué tan bien funcionará nuestro modelo con el conjunto de datos de prueba. Encontramos la probabilidad óptima utilizando el método optimalCutoff() de la biblioteca informationvalue.
Ejemplo:
library(InformationValue)
#from "Yes" and "No" to 1's and 0's
test$default <- ifelse(test$default=="Yes", 1, 0)
#optimal cutoff probability to use for maximize accuracy
optimal <- optimalCutoff(test$default, prediction)[1]
optimal
El corte de probabilidad óptimo para usar se da a continuación. Cualquier individuo con una mayor probabilidad se considerará en incumplimiento.
Producción :
[1] 0.5209985
A continuación, podemos usar la matriz de confusión para mostrar la comparación de nuestra predicción con los valores predeterminados reales.
Ejemplo:
confusionMatrix(test$default, prediction)
Producción :
0 1
0 2868 71
1 10 36
También podemos calcular la tasa positiva verdadera (sensibilidad), la tasa negativa verdadera (especificidad) y el error de clasificación errónea:
# sensitivity
sensitivity(test$default, prediction)
# specificity
specificity(test$default, prediction)
# total misclassification error rate
misClassError(test$default, prediction, threshold=optimal)
Producción :
[1] 0.3364486
[1] 0.9965254
[1] 0.0265
La tasa total de errores de clasificación es del 2,65 % para nuestro modelo, lo que significa que nuestro modelo puede predecir resultados fácilmente porque la tasa de error es muy baja.
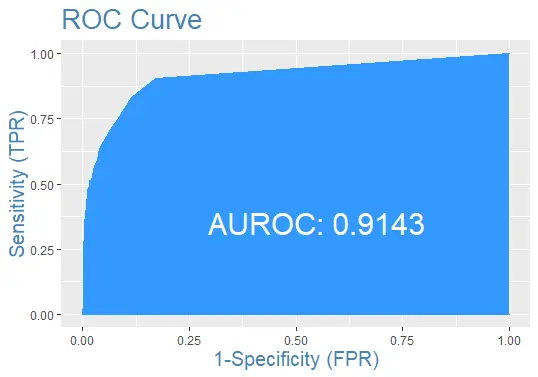
Finalmente, tracemos la curva ROC para el conjunto de datos de prueba con la predicción:
Código de ejemplo completo
Aquí está el código completo utilizado en este tutorial para su conveniencia.
install.packages('ISLR')
require(ISLR)
#load the dataset
data_set <- ISLR::Default
## The total observations in data
nrow(data_set)
#the summary of the dataset
summary(data_set)
#this will make the example reproducible
set.seed(1)
#We use 70% of as training set and 30% as testing set
sample <- sample(c(TRUE, FALSE), nrow(data), replace=TRUE, prob=c(0.7,0.3))
train <- data_set[sample, ]
test <- data_set[!sample, ]
# the logistic regression model
logistic_model <- glm(default~student+balance+income, family="binomial", data=train)
# just disable scientific notation for summary
options(scipen=999)
#view model summary
summary(logistic_model)
#defining two individuals
demo <- data.frame(balance = 1500, income = 3000, student = c("Yes", "No"))
#predict the probability of defaulting
predict(logistic_model, demo, type="response")
#probability of default for the test dataset
prediction <- predict(logistic_model, test, type="response")
install.packages('InformationValue')
library(InformationValue)
#from "Yes" and "No" to 1's and 0's
test$default <- ifelse(test$default=="Yes", 1, 0)
#optimal cutoff probability to use for maximize accuracy
optimal <- optimalCutoff(test$default, prediction)[1]
optimal
confusionMatrix(test$default, prediction)
# sensitivity
sensitivity(test$default, prediction)
# specificity
specificity(test$default, prediction)
# total misclassification error rate
misClassError(test$default, prediction, threshold=optimal)
#the ROC curve
plotROC(test$default, prediction)

Sheeraz is a Doctorate fellow in Computer Science at Northwestern Polytechnical University, Xian, China. He has 7 years of Software Development experience in AI, Web, Database, and Desktop technologies. He writes tutorials in Java, PHP, Python, GoLang, R, etc., to help beginners learn the field of Computer Science.
LinkedIn Facebook