Regresión lineal en Python
- ¿Qué es la regresión?
- ¿Qué es la regresión lineal?
- Implementación de Regresión Lineal Simple en Python
- Implementación de Regresión Múltiple en Python
En este artículo, discutiremos la regresión lineal y veremos cómo se usa la regresión lineal para predecir resultados. También implementaremos regresión lineal simple y regresión múltiple en Python.
¿Qué es la regresión?
La regresión es el proceso de identificar relaciones entre variables independientes y variables dependientes. Se utiliza para predecir los precios de la vivienda, los salarios de los empleados y otras aplicaciones de previsión.
Si queremos predecir los precios de la vivienda, las variables independientes pueden incluir la antigüedad de la vivienda, el número de dormitorios, la distancia desde los lugares centrales de la ciudad como aeropuertos, mercados, etc. Aquí, el precio de la vivienda dependerá de estas variables independientes. Por tanto, el precio de la vivienda es una variable dependiente.
De manera similar, si queremos predecir el salario de los empleados, las variables independientes pueden ser su experiencia en años, nivel de educación, costo de vida del lugar donde residen, etc. Aquí, la variable dependiente es el salario de los empleados.
Con la regresión, tratamos de establecer un modelo matemático que describa cómo las variables independientes afectan a las variables dependientes. El modelo matemático debe predecir la variable dependiente con el menor error cuando se proporcionan valores para las variables independientes.
¿Qué es la regresión lineal?
En la regresión lineal, se supone que las variables independientes y dependientes están relacionadas linealmente.
Supongamos que nos dan N variables independientes de la siguiente manera.
Ahora, necesitamos encontrar una relación lineal como la siguiente ecuación.
Aquí,
- Tenemos que identificar las constantes
Aiusando regresión lineal para predecir la variable dependienteF(X)con errores mínimos cuando se dan las variables independientes. - Las constantes Ai se denominan pesos predichos o estimadores de los coeficientes de regresión.
- F(X) se denomina respuesta predicha o respuesta estimada de la regresión. Para un
X=( X1, X2, X3, X4, X5, X6, X7……, XN)dado,F(X)debe evaluarse en un valor lo más cercano posible a la variable dependiente real Y para la variable independiente dada X. - Para calcular la función F(X) que evalúa al cierre Y, normalmente minimizamos la raíz cuadrada media de la diferencia entre F(X) e Y para valores dados de X.
Implementación de Regresión Lineal Simple en Python
Solo hay una variable independiente y una variable dependiente en la regresión simple. Entonces, la respuesta predicha se puede escribir de la siguiente manera.
Para implementar la regresión lineal simple en Python, necesitamos algunos valores reales para X y sus correspondientes valores de Y. Con esos valores, podemos calcular los pesos predichos A0 y A1 matemáticamente o usando las funciones provistas en Python.
Supongamos que se nos dan diez valores para X en forma de matriz de la siguiente manera.
X = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
Además, los valores de Y correspondientes se dan de la siguiente manera.
Y = [2, 4, 3, 6, 8, 9, 9, 10, 11, 13]
Para encontrar la ecuación de regresión F(X), podemos usar el módulo linear_model de la biblioteca de aprendizaje automático scikit-learn. Puede instalar la biblioteca scikit-learn ejecutando el siguiente comando en el símbolo del sistema de su máquina.
pip3 install scikit-learn
El módulo linear_model de la biblioteca scikit-learn nos proporciona el método LinearRegression() que podemos usar para encontrar la respuesta predicha. El método LinearRegression(), cuando se ejecuta, devuelve un modelo lineal. Podemos entrenar este modelo lineal para encontrar F(X). Para ello utilizamos el método fit().
El método fit(), cuando se invoca en un modelo lineal, acepta la matriz de variables independientes X como su primer argumento y la matriz de variables dependientes Y como su segundo argumento de entrada. Después de la ejecución, los parámetros del modelo lineal se ajustan de tal manera que el modelo represente F(X). Puede encontrar los valores para A0 y A1 utilizando los atributos intercept_ y coef_, respectivamente, como se muestra a continuación.
from sklearn import linear_model
import numpy as np
X = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]).reshape(-1, 1)
Y = [2, 4, 3, 6, 8, 9, 9, 10, 11, 13]
lm = linear_model.LinearRegression()
lm.fit(X, Y) # fitting the model
print("The coefficient is:", lm.coef_)
print("The intercept is:", lm.intercept_)
Producción :
The coefficient is: [1.16969697]
The intercept is: 1.0666666666666664
Aquí, puedes ver que el valor del coeficiente A1 es 1.16969697 y el valor del intercepto A0 es 1.0666666666666664.
Después de implementar el modelo de regresión lineal, puedes predecir el valor de Y para cualquier X usando el método predict(). Cuando se invoca en un modelo, el método predict() toma la variable independiente X como argumento de entrada y devuelve el valor predicho para la variable dependiente Y, como se muestra en el siguiente ejemplo.
from sklearn import linear_model
import numpy as np
X = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]).reshape(-1, 1)
Y = [2, 4, 3, 6, 8, 9, 9, 10, 11, 13]
lm = linear_model.LinearRegression()
lm.fit(X, Y) # fitting the model
Z = np.array([1, 5, 15, 56, 27]).reshape(-1, 1)
print("The input values are:", Z)
output = lm.predict(Z)
print("The predicted values are:", output)
Producción :
The input values are: [[ 1]
[ 5]
[15]
[56]
[27]]
The predicted values are: [ 2.23636364 6.91515152 18.61212121 66.56969697 32.64848485]
Aquí puede ver que hemos proporcionado diferentes valores de X al método predecir(), y ha devuelto el valor predicho correspondiente para cada valor de entrada.
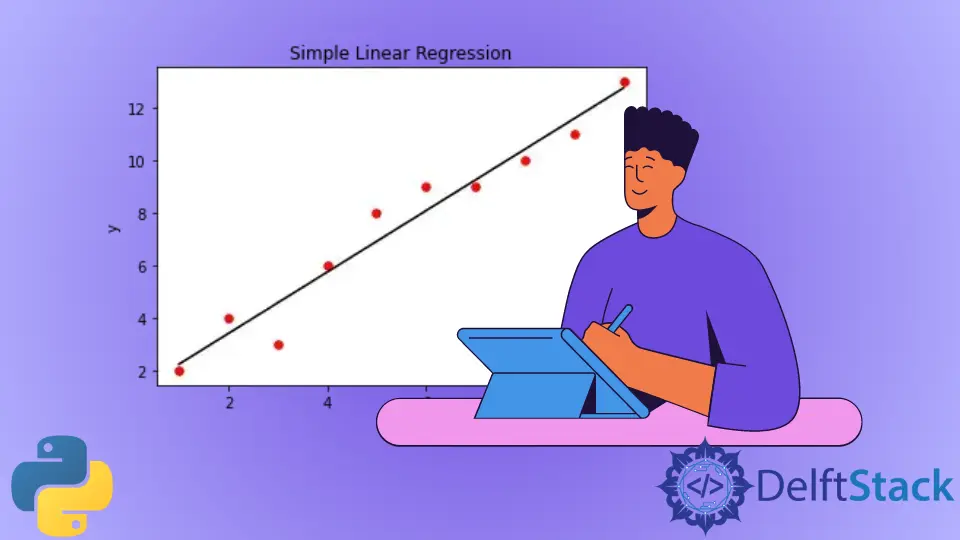
Podemos visualizar el modelo de regresión lineal simple utilizando la función de biblioteca matplotlib. Para esto, primero creamos un gráfico de dispersión de los valores reales de X e Y proporcionados como entrada. Después de crear el modelo de regresión lineal, trazaremos la salida del modelo de regresión contra X usando el método predecir(). Esto nos dará una línea recta que representa el modelo de regresión, como se muestra a continuación.
from sklearn import linear_model
import numpy as np
import matplotlib.pyplot as plt
X = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]).reshape(-1, 1)
Y = [2, 4, 3, 6, 8, 9, 9, 10, 11, 13]
lm = linear_model.LinearRegression()
lm.fit(X, Y)
plt.scatter(X, Y, color="r", marker="o", s=30)
y_pred = lm.predict(X)
plt.plot(X, y_pred, color="k")
plt.xlabel("x")
plt.ylabel("y")
plt.title("Simple Linear Regression")
plt.show()
Producción:

Implementación de Regresión Múltiple en Python
En la regresión múltiple, tenemos más de una variable independiente. Por ejemplo, sean dos variables independientes X1 y X2, y su variable dependiente Y dada de la siguiente manera.
X1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
X2 = [5, 7, 7, 8, 9, 9, 10, 11, 12, 13]
Y = [5, 7, 6, 9, 11, 12, 12, 13, 14, 16]
Aquí cada i-ésimo valor en X1, X2 e Y forma un triplete donde el i-ésimo elemento del array Y se determina utilizando el i-ésimo elemento del array X1 y el i-ésimo elemento del array X2.
Para implementar la regresión múltiple en Python, crearemos un array X a partir de X1 y X2 de la siguiente manera.
X1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
X2 = [5, 7, 7, 8, 9, 9, 10, 11, 12, 13]
X = [
(1, 5),
(2, 7),
(3, 7),
(4, 8),
(5, 9),
(6, 9),
(7, 10),
(8, 11),
(9, 12),
(10, 13),
]
Para crear X a partir de X1 y X2, utilizaremos el método zip(). El método zip() toma diferentes objetos iterables como entrada y devuelve un iterador que contiene los elementos emparejados. Como se muestra a continuación, podemos convertir el iterador en una lista usando el constructor list().
X1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
X2 = [5, 7, 7, 8, 9, 9, 10, 11, 12, 13]
print("X1:", X1)
print("X2:", X2)
X = list(zip(X1, X2))
print("X:", X)
Producción :
X1: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
X2: [5, 7, 7, 8, 9, 9, 10, 11, 12, 13]
X: [(1, 5), (2, 7), (3, 7), (4, 8), (5, 9), (6, 9), (7, 10), (8, 11), (9, 12), (10, 13)]
Después de obtener X, necesitamos encontrar F(X)= A0+A1X1+A2X2.
Para ello, podemos pasar la matriz de características X y la matriz de variables dependientes Y al método fit(). Cuando se ejecuta, el método fit() ajusta las constantes A0, A1 y A2 de modo que el modelo representa el modelo de regresión múltiple F(X). Puede encontrar los valores A1 y A2 usando el atributo coef_ y el valor A0 usando el atributo intercept_ como se muestra a continuación.
from sklearn import linear_model
import numpy as np
X1 = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
X2 = np.array([5, 7, 7, 8, 9, 9, 10, 11, 12, 13])
Y = [5, 7, 6, 9, 11, 12, 12, 13, 14, 16]
X = list(zip(X1, X2))
lm = linear_model.LinearRegression()
lm.fit(X, Y) # fitting the model
print("The coefficient is:", lm.coef_)
print("The intercept is:", lm.intercept_)
Producción :
The coefficient is: [0.72523364 0.55140187]
The intercept is: 1.4934579439252396
Aquí, puedes ver que el coeficiente es un array. El primer elemento del array representa A1 mientras que el segundo elemento del array representa A2. El intercepto representa A0
Después de entrenar el modelo, puede predecir el valor de Y para cualquier valor de X1, X2 de la siguiente manera.
from sklearn import linear_model
import numpy as np
X1 = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
X2 = np.array([5, 7, 7, 8, 9, 9, 10, 11, 12, 13])
Y = [5, 7, 6, 9, 11, 12, 12, 13, 14, 16]
X = list(zip(X1, X2))
lm = linear_model.LinearRegression()
lm.fit(X, Y) # fitting the model
Z = [(1, 3), (1, 5), (4, 9), (4, 8)]
print("The input values are:", Z)
output = lm.predict(Z)
print("The predicted values are:", output)
Producción :
The input values are: [(1, 3), (1, 5), (4, 9), (4, 8)]
The predicted values are: [3.8728972 4.97570093 9.35700935 8.80560748]

Aditya Raj is a highly skilled technical professional with a background in IT and business, holding an Integrated B.Tech (IT) and MBA (IT) from the Indian Institute of Information Technology Allahabad. With a solid foundation in data analytics, programming languages (C, Java, Python), and software environments, Aditya has excelled in various roles. He has significant experience as a Technical Content Writer for Python on multiple platforms and has interned in data analytics at Apollo Clinics. His projects demonstrate a keen interest in cutting-edge technology and problem-solving, showcasing his proficiency in areas like data mining and software development. Aditya's achievements include securing a top position in a project demonstration competition and gaining certifications in Python, SQL, and digital marketing fundamentals.
GitHub