Clasificar Pandas DataFrame dentro del grupo
Este artículo discutirá cómo clasificar los datos en orden ascendente y descendente. También aprenderemos cómo clasificar un grupo de datos con la ayuda de la función groupby() en Pandas.
Utilice la función rank() para clasificar Pandas DataFrame en Python
La clasificación es un procedimiento común cada vez que manipulamos datos o tratamos de averiguar si, por ejemplo, la ganancia es alta o baja en función de alguna clasificación. Incluso a veces, la gestión del tiempo está interesada en saber cuáles son los 10 mejores productos o los 10 últimos productos.
En Pandas, la clasificación de datos es una operación en la que queremos que los elementos de la serie se clasifiquen u ordenen según sus valores. La operación rank está inspirada en SQL ROW_NUMBER, o la mayoría de los resultados que podemos esperar de la operación ROW_NUMBER se pueden esperar de la operación rank en Pandas.
Comencemos escribiendo un código para ver un ejemplo.
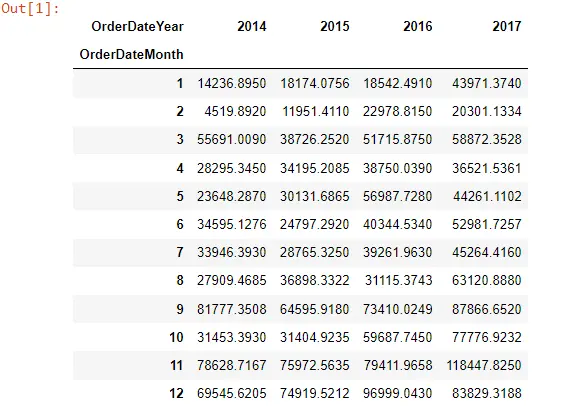
Hemos cargado un conjunto de datos de una supertienda y extraído el mes y el año de los datos. Y hemos creado la tabla dinámica para el valor de las ventas durante el mes y el año.
import numpy as np
import pandas as pd
import datetime
Store_Data = pd.read_excel("demo_Data.xls")
Store_Data["OrderDateMonth"] = Store_Data["Order Date"].apply(lambda x: x.month)
Store_Data["OrderDateYear"] = Store_Data["Order Date"].apply(lambda x: x.year)
Mon_Year_Sales = pd.pivot_table(
Store_Data,
index=["OrderDateMonth"],
columns=["OrderDateYear"],
aggfunc="sum",
values="Sales",
)
Mon_Year_Sales
Entonces, si miramos nuestra tabla dinámica, esto es lo que parece:
Clasifique el DataFrame en orden ascendente y descendente
Ahora, tenemos que clasificar estos datos en función de los valores. La biblioteca de Pandas tiene una función rank() que opcionalmente toma el parámetro ascending y, por defecto, ordenará los datos en orden ascendente.
La función rank() tiene algunos argumentos que podemos ver presionando shift+tab+tab. Nos mostrará todos los argumentos y definiciones.
![]()
Si seguimos adelante y aplicamos la clasificación en Mon_Year_Sales y lo ejecutamos, tomará todas estas columnas y las convertirá en numéricas, cualquiera que sea la forma numérica, y hará la clasificación en orden ascendente.
Mon_Year_Sales.rank()
![]()
El rango se calcula usando los valores dados.
En la segunda fila de 2014, este dato es el primer rango. Está ordenado en orden ascendente porque no le hemos pasado ningún valor al argumento ascendente.
Si le pasamos el argumento ascendente False, reordenaría la secuencia en el orden descendente de los valores.
Mon_Year_Sales.rank(ascending=False)
Ahora, el noveno mes tiene el mayor valor de ventas en 2014, por lo que ocupa el primer lugar.
![]()
Utilice el método groupby() para clasificar datos en función de un grupo en Pandas
Hay ciertos requisitos en los que queremos clasificar los datos en función de un grupo de valores, no del total. Supongamos que nuestros datos se ven así:
![]()
Supongamos que queremos clasificar entre las categorías por el valor Beneficio en lugar de la clasificación general.
Group_Data = (
Store_Data.groupby(["OrderDateYear", "Category"])
.agg({"Profit": "sum"})
.reset_index()
)
Group_Data
![]()
Para el año en particular, queremos clasificar el beneficio de las categorías, por lo que, para 2014, queremos que el segundo valor sea el primero porque este es el máximo dentro de 2014.
De manera similar, para 2015 queremos una clasificación separada, como comenzar de nuevo desde 1, 2 y 3 en lugar de continuar en la general. Y luego, queremos saber qué categoría tiene el rango más alto, entonces, ¿cómo podemos lograrlo?
Para lograr el objetivo, agruparemos por año y luego seleccionaremos el “beneficio”, luego estableceremos el argumento “ascendente” para que sea “False”, lo que significa que queremos que el rango superior tenga el valor máximo. Luego establecemos el argumento método en denso.
Group_Data["Rank_groupby"] = Group_Data.groupby("OrderDateYear")["Profit"].rank(
ascending=False, method="dense"
)
Group_Data
Después de la ejecución, ahora podemos ver que Suministros de oficina obtuvo el primer rango, y luego el otro nivel de grupo comenzó nuevamente desde 1, 2 y 3 para cada año en particular.
![]()
Código de ejemplo completo:
# In[1]:
import numpy as np
import pandas as pd
import datetime
Store_Data = pd.read_excel("demo_Data.xls")
Store_Data["OrderDateMonth"] = Store_Data["Order Date"].apply(lambda x: x.month)
Store_Data["OrderDateYear"] = Store_Data["Order Date"].apply(lambda x: x.year)
Mon_Year_Sales = pd.pivot_table(
Store_Data,
index=["OrderDateMonth"],
columns=["OrderDateYear"],
aggfunc="sum",
values="Sales",
)
Mon_Year_Sales
# In[2]:
Mon_Year_Sales.rank()
# In[3]:
Mon_Year_Sales.rank(ascending=False)
# In[4]:
Store_Data.head(2)
# In[5]:
Group_Data = (
Store_Data.groupby(["OrderDateYear", "Category"])
.agg({"Profit": "sum"})
.reset_index()
)
Group_Data
# In[6]:
Group_Data["Rank_groupby"] = Group_Data.groupby("OrderDateYear")["Profit"].rank(
ascending=False, method="dense"
)
Group_Data
Lea más respuestas relacionadas de aquí.

Hello! I am Salman Bin Mehmood(Baum), a software developer and I help organizations, address complex problems. My expertise lies within back-end, data science and machine learning. I am a lifelong learner, currently working on metaverse, and enrolled in a course building an AI application with python. I love solving problems and developing bug-free software for people. I write content related to python and hot Technologies.
LinkedInArtículo relacionado - Pandas DataFrame
- Cómo obtener las cabeceras de columna de Pandas DataFrame como una lista
- Cómo borrar la columna de Pandas DataFrame
- Cómo convertir la columna del DataFrame a Datetime en Pandas
- Cómo convertir un float en un entero en Pandas DataFrame
- Cómo clasificar Pandas DataFrame por los valores de una columna
- Cómo obtener el agregado de Pandas grupo por y suma