Agregar metadatos al marco de datos de Pandas
Los metadatos, también conocidos como datos sobre datos, son datos estructurados que describen, ubican y administran el contenido de los documentos compartidos en la web a través de la publicación web.
Algunos servidores web y herramientas de software pueden generar metadatos automáticamente. Sin embargo, el proceso manual también es factible.
Puede mejorar la organización, el descubrimiento, la accesibilidad, la indexación y la recuperación de un documento.
El marco de datos de Pandas es una estructura de datos construida sobre el marco de datos que proporciona la funcionalidad de los marcos de datos R y los diccionarios de Python.
Es como un diccionario de Python pero tiene toda la funcionalidad de análisis y manipulación de datos, como tablas en Excel o bases de datos con filas y columnas. Este tutorial explica cómo agregar metadatos a los marcos de datos de Pandas.
Agregar metadatos al marco de datos de Pandas
Para agregar metadatos a un marco de datos, debemos cumplir con los requisitos que se indican a continuación.
- Cree o importe un marco de datos.
- Lea los metadatos existentes del marco de datos.
- Agregue metadatos al marco de datos.
Crear o importar un marco de datos
Se requiere un marco de datos para agregarle metadatos. Para ello, debes instalar una biblioteca de Python llamada pandas.
PS C:\> pip install pandas
Leamos un marco de datos de un archivo usando pandas.
Código de ejemplo (guardado en demo.py):
import pandas as pd
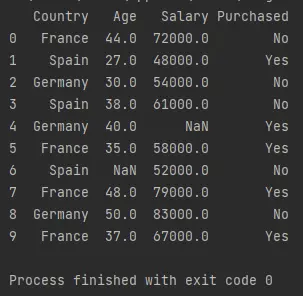
df = pd.read_csv("Data.csv")
print(df)
El código anterior importa el paquete de Python pandas como pd. La función pd.read_csv() importa un marco de datos, lo lee y lo almacena en una variable llamada df.
Veamos qué es pd.
Salida (impresa en la consola):
Leer metadatos existentes del marco de datos
El marco de datos importado también contiene algunos metadatos existentes. Podemos verlo a través de los ejemplos de código a continuación.
-
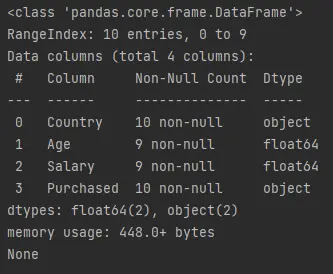
La función
info()de Panda proporciona un resumen rápido del marco de datos. Recupera información comomax_cols,memory_usage,show_countsynull_counts.Ejecutemos el siguiente código que llama a
df.info()y lo imprima.Código de ejemplo (guardado en
demo.py):print(df.info())Salida (impresa en la consola):
-
El atributo
columnasde Pandas devuelve una matriz n-dimensional inmutable de conjuntos ordenados llamadaÍndiceque contiene etiquetas de cada columna del marco de datos. Ejecutemos el siguiente código que llama adf.columnse imprime unÍndice.
Código de ejemplo (guardado en `demo.py`):
```python
print(df.columns)
```
Salida (impresa en la consola):

-
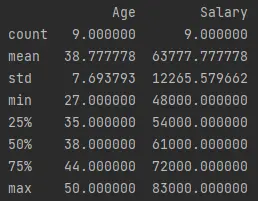
La función
describe()de Pandas genera estadísticas descriptivas del marco de datos. Esto incluyerecuento,mediay desviación estándar comoestándar,mínimo,máximoy percentiles.Ejecutemos el siguiente código que llama a
df.describe()y lo imprime.Código de ejemplo (guardado en
demo.py):print(df.describe())Salida (impresa en la consola):
Agregar metadatos al marco de datos
Ejecutemos el siguiente código para agregar metadatos al marco de datos de Pandas.
Código de ejemplo (guardado en demo.py):
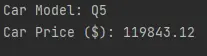
df.audi_car_model = "Q5"
df.audi_car_price_in_dollars = 119843.12
print(f"Car Model: {df.audi_car_model}")
print(f"Car Price ($): {df.audi_car_price_in_dollars}")
Salida (impresa en la consola):
Nota: Python no proporciona un método poderoso para propagar metadatos a marcos de datos.
Por ejemplo, operar como group_by en un marco de datos con metadatos adjuntos devolverá el marco de datos anterior sin metadatos adjuntos.
Sin embargo, puede almacenar los metadatos en un archivo HDF5 para su posterior procesamiento. Ejecutemos el siguiente código para guardar los metadatos en un archivo HDF5.
Código de ejemplo (guardado en demo.py):
def store_in_hdf5(filename, df, **kwargs):
hdf5_file = pd.HDFStore(filename)
hdf5_file.put("car_data", df)
hdf5_file.get_storer("car_data").attrs.metadata = kwargs
hdf5_file.close()
filename = "car data.hdf5"
metadata = {"audi_car_model": "Q5", "audi_car_price_in_dollars": 119843.12}
store_in_hdf5(filename, df, **metadata)
La función store_in_hdf5() realiza las siguientes funciones:
- Cree un
archivo_hdf5usando la funciónpd.HDFStore()con elnombre de archivocomo argumento. - Inserte el marco de datos en el archivo usando
hdf5_file.put()tomando un nombre apropiado ydfcomo argumentos. - Guarde los metadatos en
hdf5_file. Utilizahdf5_file.get_storer('car_data').attrs.metadatay le asignametadatos. - Llame a
hdf5_file.close()para cerrar el archivo.
Ahora, ejecutemos el siguiente código para importar el marco de datos y los metadatos de un archivo.
Código de ejemplo (guardado en demo.py):
def import_from_file(hdf5_file):
data = hdf5_file["car_data"]
metadata = hdf5_file.get_storer("car_data").attrs.metadata
return data, metadata
filename = "car data.hdf5"
with pd.HDFStore(filename) as hdf5_file:
data, metadata = import_from_file(hdf5_file)
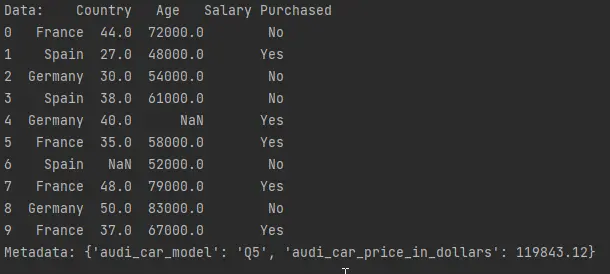
print(f"Data: {data}")
print(f"Metadata: {metadata}")
La función import_from_file() toma el hdf5_file como argumento. Recupera la siguiente información:
datosespecificando el nombre de los datos enhdf5_file[].metadatosllamando al atributometadatosde la funciónhdf5_file.get_storer('car_data').attrs.metadata.
Ahora, ejecutamos el archivo de Python demo.py como:
PS C:>python demo.py
Imprime los data y metadata devueltos por la función import_from_file().
Salida (impresa en la consola):