Visualización de gráficos de KDE con Pandas y Seaborn
- Visualización de datos utilizando el gráfico normal de KDE y Seaborn en Python
- Gráfica KDE unidimensional usando Pandas y Seaborn en Python
- Gráfica KDE bidimensional o bivariada utilizando Pandas y Seaborn en Python
- Conclusión
KDE es Estimación de la densidad del kernel, que se utiliza para visualizar la densidad de probabilidad de variables de datos continuas y no paramétricas. Cuando desee visualizar las distribuciones múltiples, la función KDE produce un gráfico menos desordenado que es más interpretable.
Usando KDE, podemos visualizar múltiples muestras de datos usando un solo gráfico, que es un método más eficiente en la visualización de datos.
Seaborn es una biblioteca de Python como matplotlib. Seaborn se puede integrar con pandas y numpy para representaciones de datos.
Los científicos de datos usan esta biblioteca para crear cuadros y gráficos estadísticos informativos y atractivos. Con estas presentaciones, puede comprender los conceptos claros y el flujo de información dentro de los diferentes módulos.
Podemos trazar gráficos univariados y bivariados usando la función KDE, Seaborn y Pandas.
Aprenderemos sobre la visualización de gráficos de KDE con pandas y seaborn. Este artículo utilizará algunas muestras del conjunto de datos mtcars para mostrar la visualización de gráficos de KDE.
Antes de comenzar con los detalles, debe instalar o agregar las bibliotecas seaborn y sklearn usando el comando pip.
pip install seaborn
pip install sklearn
Visualización de datos utilizando el gráfico normal de KDE y Seaborn en Python
Podemos trazar los datos utilizando la función de trazado normal de KDE con la biblioteca Seaborn.
En el siguiente ejemplo, hemos creado 1000 muestras de datos utilizando la biblioteca aleatoria y luego las organizamos en la matriz de numpy porque la biblioteca Seaborn solo funciona bien con numpy y Pandas dataframes.
Código de ejemplo:
import seaborn as sn
import matplotlib.pyplot as plt
import numpy as np
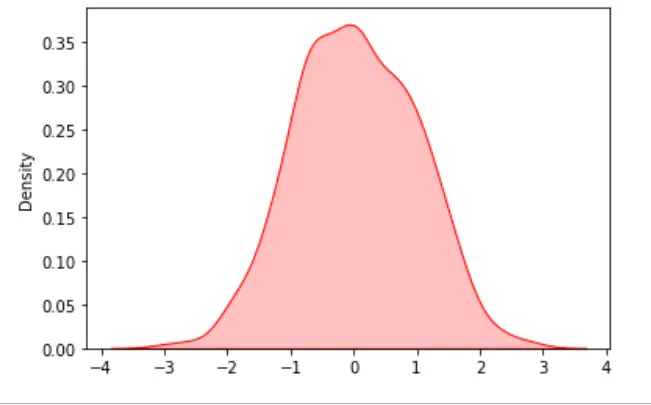
data = np.random.randn(1000)
# KDE Plot with seaborn
res = sn.kdeplot(data, color="red", shade="True")
plt.show()
Producción:
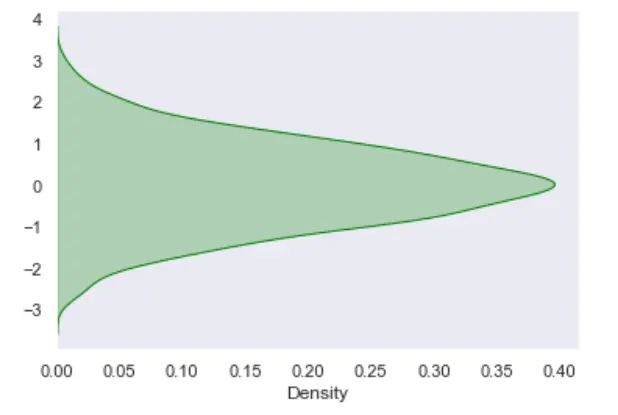
También podemos visualizar la muestra de datos anterior verticalmente o revertir el gráfico anterior usando la biblioteca KDE y Seaborn. Usamos la propiedad de trama vertical=True para revertir la trama anterior.
Código de ejemplo:
import seaborn as sn
import matplotlib.pyplot as plt
import numpy as np
data = np.random.randn(1000)
# KDE Plot with seaborn
res = sn.kdeplot(data, color="green", vertical=True, shade="True")
plt.show()
Producción:
Gráfica KDE unidimensional usando Pandas y Seaborn en Python
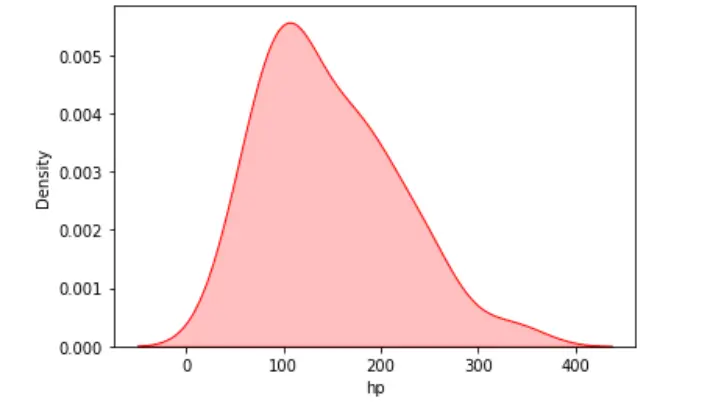
Podemos visualizar la distribución de probabilidad para un único objetivo o atributo continuo utilizando el diagrama de KDE. En el siguiente ejemplo, hemos leído un archivo CSV del conjunto de datos mtcars.
Hay más de 350 entradas en nuestro conjunto de datos y visualizaremos la distribución univariada a lo largo del eje x.
Código de ejemplo:
import seaborn as sn
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# read CSV file of dataset using pandas
dataset = pd.read_csv(r"C:\\Users\\DELL\\OneDrive\\Desktop\\samplecardataset.csv")
# kde plot using seaborn
sn.kdeplot(data=dataset, x="hp", shade=True, color="red")
plt.show()
Producción:
También puede voltear la gráfica visualizando la variable de datos a lo largo del eje y.
Código de ejemplo:
import seaborn as sn
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# Read CSV file using pandas
dataset = pd.read_csv(r"C:\\Users\\DELL\\OneDrive\\Desktop\\samplecardataset.csv")
# KDE plotting using seaborn
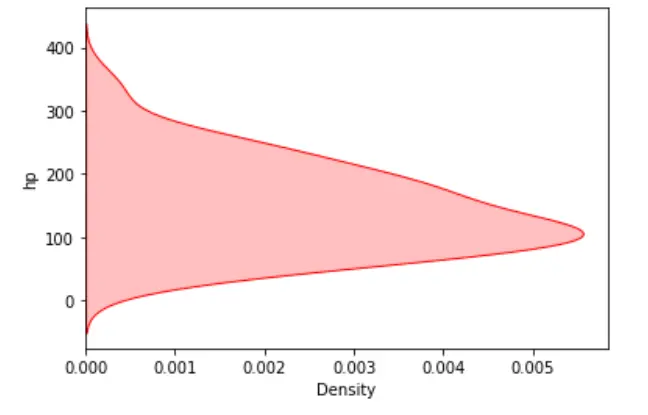
sn.kdeplot(data=dataset, y="hp", shade=True, color="red")
plt.show()
Producción:
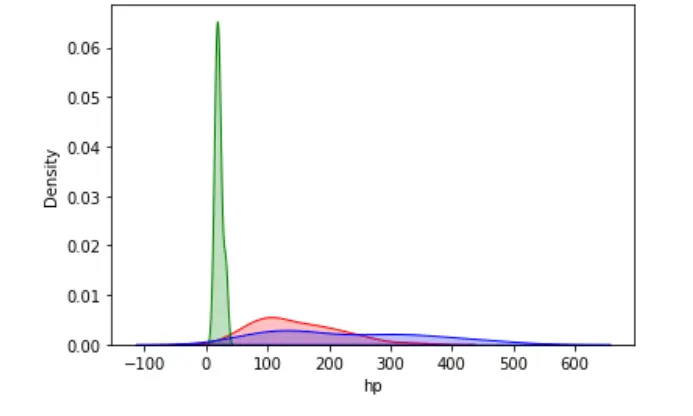
Podemos visualizar la distribución de probabilidad de múltiples valores objetivo en una sola gráfica.
Código de ejemplo:
import seaborn as sn
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# Read CSV file using pandas
dataset = pd.read_csv(r"C:\\Users\\DELL\\OneDrive\\Desktop\\samplecardataset.csv")
# KDE plotting using seaborn
sn.kdeplot(data=dataset, x="hp", shade=True, color="red")
sn.kdeplot(data=dataset, x="mpg", shade=True, color="green")
sn.kdeplot(data=dataset, x="disp", shade=True, color="blue")
plt.show()
Producción:
Gráfica KDE bidimensional o bivariada utilizando Pandas y Seaborn en Python
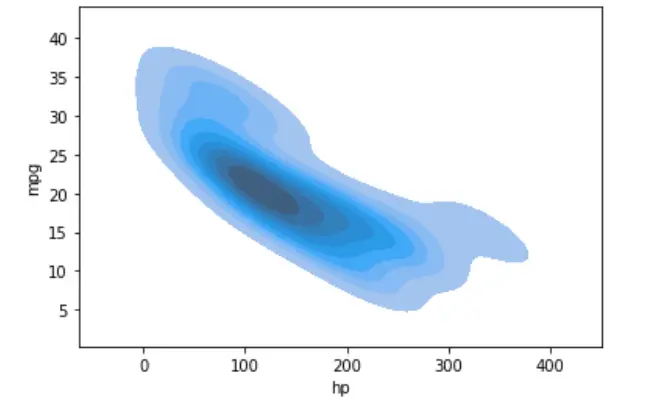
Podemos visualizar datos en gráficos KDE bidimensionales o bivariados utilizando la biblioteca seaborn y pandas.
De esta forma, podemos visualizar la distribución de probabilidad de una muestra dada frente a múltiples atributos continuos. Visualizamos los datos a lo largo de los ejes x e y.
Código de ejemplo:
import seaborn as sn
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# Read CSV file using pandas
dataset = pd.read_csv(r"C:\\Users\\DELL\\OneDrive\\Desktop\\samplecardataset.csv")
# KDE plotting using seaborn
sn.kdeplot(data=dataset, shade=True, x="hp", y="mpg")
plt.show()
Producción:
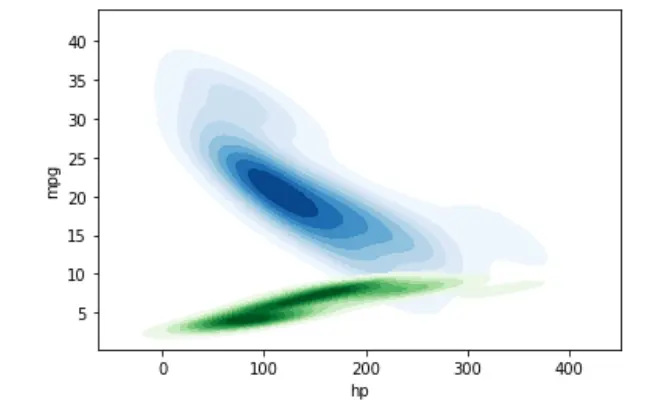
De manera similar, podemos trazar la distribución de probabilidad de múltiples muestras utilizando un único gráfico KDE.
Código de ejemplo:
import seaborn as sn
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# Read CSV file using pandas
dataset = pd.read_csv(r"C:\\Users\\DELL\\OneDrive\\Desktop\\samplecardataset.csv")
# KDE plotting using seaborn
sn.kdeplot(data=dataset, shade=True, x="hp", y="mpg", cmap="Blues")
sn.kdeplot(data=dataset, shade=True, x="hp", y="cyl", cmap="Greens")
plt.show()
Producción:
Conclusión
Lo demostramos en este tutorial usando la visualización de gráficos de KDE usando la biblioteca Pandas y Seaborn. Hemos visto cómo visualizar la distribución de probabilidad de muestras únicas y múltiples en un gráfico KDE unidimensional.
Discutimos cómo usar el diagrama de KDE con Seaborn y Pandas para visualizar los datos bidimensionales.
Artículo relacionado - Pandas DataFrame
- Cómo obtener las cabeceras de columna de Pandas DataFrame como una lista
- Cómo borrar la columna de Pandas DataFrame
- Cómo convertir la columna del DataFrame a Datetime en Pandas
- Cómo convertir un float en un entero en Pandas DataFrame
- Cómo clasificar Pandas DataFrame por los valores de una columna
- Cómo obtener el agregado de Pandas grupo por y suma