Extraiga tablas HTML en un marco de datos usando BeautifulSoup
Python tiene varios paquetes para trabajar teniendo en cuenta los requisitos del proyecto; uno es BeautifulSoup, que se utiliza para analizar documentos HTML y XML.
Crea un árbol de análisis para las páginas analizadas que podemos usar para extraer información (datos) de HTML, lo cual es beneficioso para el web scraping. El tutorial de hoy enseña cómo raspar tablas HTML en un marco de datos usando el paquete BeautifulSoup.
Use BeautifulSoup para raspar tablas HTML en un marco de datos
No es necesario que siempre obtengamos los datos organizados y limpios cada vez.
A veces, necesitamos los datos que están disponibles en los sitios web. Para eso, debemos ser capaces de recogerlo.
Afortunadamente, el paquete BeautifulSoup de Python tiene la solución para nosotros. Aprendamos cómo podemos usar este paquete para raspar tablas en un marco de datos.
Primero, necesitamos instalar este paquete en nuestra máquina para poder importarlo a nuestros scripts de Python. Podemos usar el comando pip para instalar BeautifulSoup en el sistema operativo Windows.
pip install beautifulsoup
Puede visitar esta documentación para obtener más información. Sabemos que no estamos familiarizados con la estructura básica de la tabla HTML, que es importante saber mientras raspamos; entendamos que seguir junto con este tutorial.
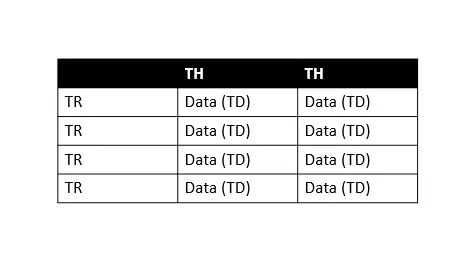
En la tabla anterior, TH significa encabezado de tabla, TR significa fila de tabla y TD significa datos de tabla (lo llamamos celdas). Como podemos ver, cada fila de la tabla tiene varios datos de tabla, por lo que podemos iterar fácilmente sobre cada fila para extraer información.
Ahora, vamos a aprenderlo paso a paso.
-
Importar bibliotecas
import requests import pandas as pd from bs4 import BeautifulSoupPrimero, necesitamos importar todas estas bibliotecas, la biblioteca
pandaspara trabajar con marcos de datos,bs4(sopa hermosa) para extraer datos y la bibliotecarequestspara realizar solicitudes HTTP usando Python. -
Descargar contenido de la página web
web_url = "https://pt.wikipedia.org/wiki/Lista_de_bairros_de_Manaus" data = requests.get(web_url).text # data # print(data) # print(type(data))Aquí, guardamos la URL requerida en la variable
web_urly hacemos una solicitud HTTP utilizando el módulorequests.Usamos
.get()del módulorequestspara recuperar datos de laweb_urlespecificada, mientras que.textsignifica que queremos recuperar datos como una cadena.Entonces, si imprimimos como
print(type(data)), veremos que recuperamos el HTML de toda la página como una cadena. Puede jugar imprimiendodatos,print(datos)eprint(tipo (datos)).Todos estos están en la valla de código anterior; puedes descomentarlas y practicar.
-
Crear objeto
BeautifulSoupbeautiful_soup = BeautifulSoup(data, "html.parser") # print(type(beautiful_soup.b))El objeto
BeautifulSoup(beautiful_soup) representa todo el documento analizado. Entonces, podemos decir que es un documento completo que estamos tratando de raspar.En su mayoría, lo tratamos como un objeto
Etiqueta, que también se puede verificar usando la declaraciónprint(type(beautiful_soup.b)). Ahora, tenemos el HTML completo de la página requerida.El siguiente paso es averiguar la tabla que queremos, podríamos obtener información de la primera tabla, pero existe la posibilidad de varias tablas en la misma página web.
Por lo tanto, es importante encontrar la tabla requerida que queremos raspar. ¿Cómo? Podemos hacerlo fácilmente inspeccionando el código fuente.
Para eso, haga
clic derechoen cualquier parte de la página web requerida y seleccioneinspeccionar, presione Ctrl+Shift+C para seleccionar el elementos (resaltados en rojo en la siguiente captura de pantalla), también puede usar el cuadro de búsqueda para encontrar etiquetas específicas (resaltadas en verde en la siguiente captura de pantalla).
Tenemos tres mesas; como se muestra en la captura de pantalla anterior (vea este número en el cuadro de búsqueda, resaltado en verde), estamos usando la tabla resaltada con
class="wikitable sortable jquery-tablesorter".El punto es, ¿por qué estamos usando el atributo
clasepara seleccionar la tabla? Es porque las tablas no tienen ningún título sino un atributo declase. -
Verificar tablas con sus clases
print("Classes of Every table:") for table in beautiful_soup.find_all("table"): print(table.get("class"))Producción:
Classes of Every table: ['box-Desatualizado', 'plainlinks', 'metadata', 'ambox', 'ambox-content'] ['wikitable', 'sortable'] ['nowraplinks', 'collapsible', 'collapsed', 'navbox-inner']Aquí, iteramos sobre todos los elementos
<table>para encontrar sus clases obteniendo el atributoclase. -
Buscar clases
wikitableysortabletables = beautiful_soup.find_all("table") table = beautiful_soup.find("table", class_="wikitable sortable")Primero, creamos una lista de todas las tablas y luego buscamos la tabla con las clases
wikitableysortable. -
Cree un marco de datos y rellénelo
df = pd.DataFrame( columns=["Neighborhood", "Zone", "Area", "Population", "Density", "Homes_count"] ) mylist = [] for table_row in table.tbody.find_all("tr"): table_columns = table_row.find_all("td") if table_columns != []: neighbor = table_columns[0].text.strip() zone = table_columns[1].text.strip() area = table_columns[2].span.contents[0].strip("&0.") population = table_columns[3].span.contents[0].strip("&0.") density = table_columns[4].span.contents[0].strip("&0.") home_count = table_columns[5].span.contents[0].strip("&0.") mylist.append([neighbor, zone, area, population, density, home_count]) df = pd.DataFrame( mylist, columns=["Neighborhood", "Zone", "Area", "Population", "Density", "Homes_count"], )Aquí, definimos un marco de datos con las columnas
Barrio,Zona,Área,Población,DensidadyRecuento de viviendas. Luego, iteramos sobre la tabla HTML para recuperar datos y completar el marco de datos que acabamos de definir. -
Utilice
df.head()para imprimir los primeros cinco documentosprint(df.head())Producción:
Neighborhood Zone Area Population Density Homes_count 0 Adrianópolis Centro-Sul 248.45 10459 3560.88 3224 1 Aleixo Centro-Sul 618.34 24417 3340.4 6101 2 Alvorada Centro-Oeste 553.18 76392 11681.73 18193 3 Armando Mendes Leste 307.65 33441 9194.86 7402 4 Betânia Sul 52.51 1294 20845.55 3119
Código fuente completo:
import requests
import pandas as pd
from bs4 import BeautifulSoup
web_url = "https://pt.wikipedia.org/wiki/Lista_de_bairros_de_Manaus"
data = requests.get(web_url).text
beautiful_soup = BeautifulSoup(data, "html.parser")
print("Classes of Every table:")
for table in beautiful_soup.find_all("table"):
print(table.get("class"))
tables = beautiful_soup.find_all("table")
table = beautiful_soup.find("table", class_="wikitable sortable")
df = pd.DataFrame(
columns=["Neighborhood", "Zone", "Area", "Population", "Density", "Homes_count"]
)
mylist = []
for table_row in table.tbody.find_all("tr"):
table_columns = table_row.find_all("td")
if table_columns != []:
neighbor = table_columns[0].text.strip()
zone = table_columns[1].text.strip()
area = table_columns[2].span.contents[0].strip("&0.")
population = table_columns[3].span.contents[0].strip("&0.")
density = table_columns[4].span.contents[0].strip("&0.")
home_count = table_columns[5].span.contents[0].strip("&0.")
mylist.append([neighbor, zone, area, population, density, home_count])
df = pd.DataFrame(
mylist,
columns=["Neighborhood", "Zone", "Area", "Population", "Density", "Homes_count"],
)
print(df.head())
Producción :
Classes of Every table:
['box-Desatualizado', 'plainlinks', 'metadata', 'ambox', 'ambox-content']
['wikitable', 'sortable']
['nowraplinks', 'collapsible', 'collapsed', 'navbox-inner']
Neighborhood Zone Area Population Density Homes_count
0 Adrianópolis Centro-Sul 248.45 10459 3560.88 3224
1 Aleixo Centro-Sul 618.34 24417 3340.4 6101
2 Alvorada Centro-Oeste 553.18 76392 11681.73 18193
3 Armando Mendes Leste 307.65 33441 9194.86 7402
4 Betânia Sul 52.51 1294 20845.55 3119
