Leer archivo PDF en C#
-
Análisis de PDF en
C# -
Utilice IronPDF para leer/analizar archivos PDF en
C# -
Use iTextSharp para leer/analizar archivos PDF en
C#

Este artículo trata sobre analizar un documento PDF y almacenarlo en una variable de cadena. Esta variable se puede usar para múltiples propósitos en un programa C#.
Análisis de PDF en C#
Puede ser sencillo trabajar con archivos PDF en C# y utilizar todas las funciones necesarias para una aplicación .NET, incluido el uso de la biblioteca de C# para analizar archivos PDF. Este tutorial lo logrará en solo unos pocos pasos usando dos bibliotecas de C# diferentes, IronPDF e iTextSharp.
Utilice IronPDF para leer/analizar archivos PDF en C#
IronPDF es una biblioteca comercial desarrollada en C# para generar y analizar documentos PDF. Tiene la función de generar archivos PDF a partir de cadenas o incluso HTML.
Funciona para todo tipo de aplicaciones .NET, aplicaciones de escritorio, aplicaciones web, aplicaciones de servidor o incluso aplicaciones WPF.
Los pasos para usar la biblioteca para leer un archivo PDF se enumeran a continuación:
-
Descargue la biblioteca IronPDF en su Visual Studio mediante el instalador del paquete NuGet.
-
Haga clic con el botón derecho en el nombre de su proyecto en la ventana Explorador de soluciones y seleccione Administrar paquetes NuGet.
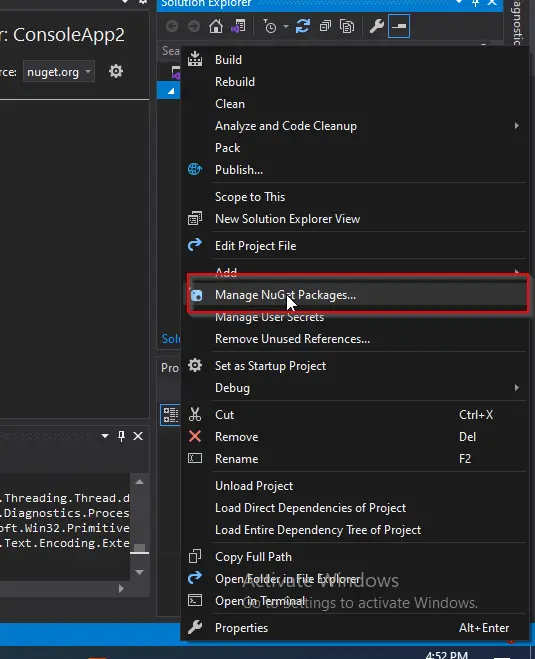
-
Aparecerá la ventana Paquete NuGet. En esa ventana, en la pestaña Examinar, busque IronPDF y luego seleccione la primera biblioteca.
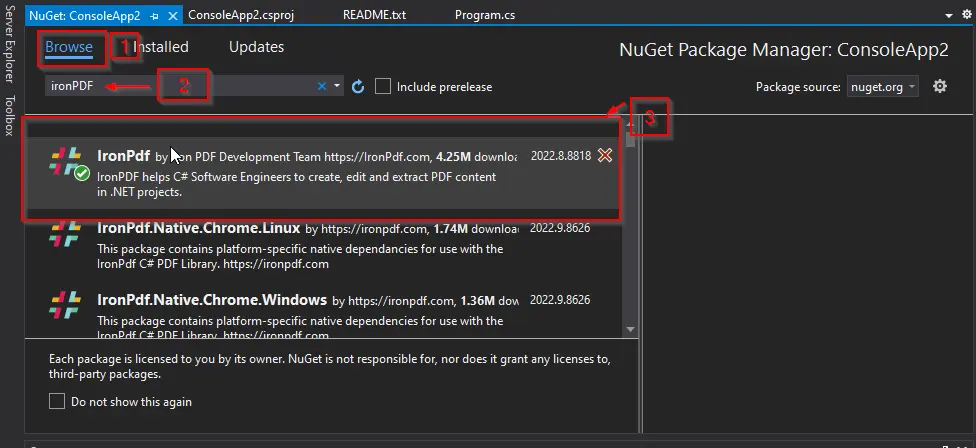
-
Escriba el código para analizar documentos PDF.
Jugar con IronPDF le mostrará cuántas funciones tiene para simplificar el trabajo con archivos PDF en C#. Se ocupa principalmente de producir, leer y editar cualquier archivo PDF en los formatos requeridos.
Los archivos PDF se pueden analizar fácilmente.
El método ExtractAllText() se utiliza en el siguiente código para recuperar cada línea de texto del archivo PDF completo. Más tarde puede ver la salida, que muestra el contenido del archivo PDF.
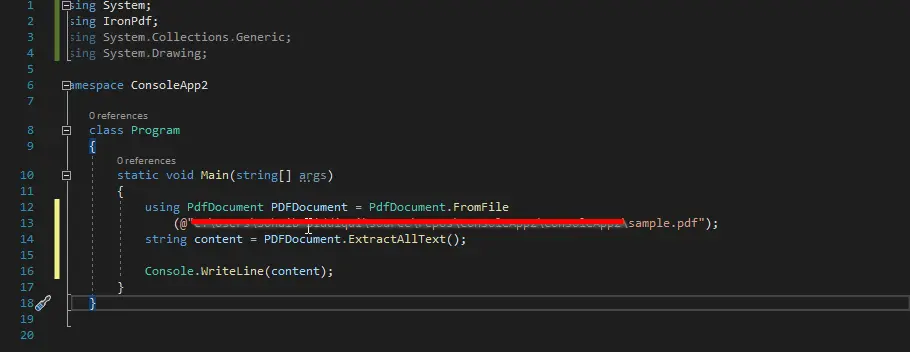
Puede ver en el código que primero creamos un objeto de PdfDocument y lo pasamos a la ruta del archivo para analizarlo.
Luego llamamos a un método ExtractAllText() y almacenamos todo el contenido en una variable de cadena contenido. Luego mostramos esa variable en la pantalla.
Es una tarea muy sencilla y directa. Puedes ver la salida a continuación:
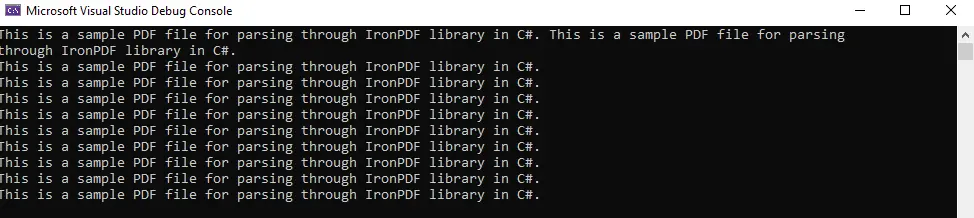
Use iTextSharp para leer/analizar archivos PDF en C#
iTextSharp es otra biblioteca de C# que es una herramienta avanzada para crear informes PDF complejos; estos informes pueden ser utilizados por múltiples aplicaciones de plataforma, como Android, IOS o Java. Tiene funcionalidades que pueden crear archivos PDF utilizando los datos de la base de datos o formatos XML y fusionar o dividir cualquier documento PDF.
Los pasos para usar iTextSharp para leer un archivo PDF se muestran a continuación:
-
Descargue la biblioteca iTextSharp en su Visual Studio usando el instalador del paquete NuGet.
-
Haga clic con el botón derecho en el nombre de su proyecto en la ventana Explorador de soluciones y seleccione Administrar paquetes NuGet.
-
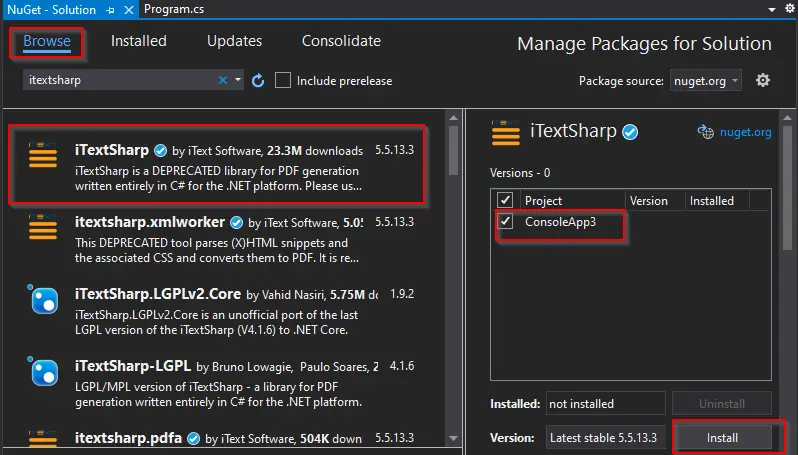
Aparecerá la ventana Paquete NuGet. En esa ventana, en la pestaña Examinar, busque iTextSharp, seleccione la primera biblioteca y elija Instalar.
-
Incluya las siguientes bibliotecas en su archivo
cs:using iTextSharp.text.pdf; using iTextSharp.text.pdf.parser; -
Ahora creemos una función que leerá un archivo PDF y analizará ese archivo PDF en una variable de cadena.
public static string parsePDFDocument(string filePath) { using (PdfReader read = new PdfReader(filePath)) { StringBuilder convertedText = new StringBuilder(); for (int p = 1; p <= read.NumberOfPages; p++) { convertedText.Append(PdfTextExtractor.GetTextFromPage(read, p)); } return convertedText.ToString(); } }
En este fragmento de código, hemos creado un objeto de la clase PdfReader, que forma parte de la biblioteca iTextSharp. Este objeto toma una ruta de archivo del documento PDF que se va a analizar.
Después de eso, creamos una cadena usando la clase StringBuilder que puede contener el texto de un archivo PDF.
Luego, el ciclo comienza desde la primera página hasta el número total de páginas en el documento PDF. Dentro del bucle, hemos agregado el texto en el objeto de cadena creado página por página.
Al final, la cadena se devuelve al punto donde se llamará a la función.
Nuestra función Principal se verá así:
static void Main(string[] args) {
var ExtractedTextFromPDF = parsePDFDocument([path to PDF file]);
Console.WriteLine(ExtractedTextFromPDF);
}
Asegúrese de pasar el archivo PDF con su ruta completa. Después de la compilación, dará el siguiente resultado:
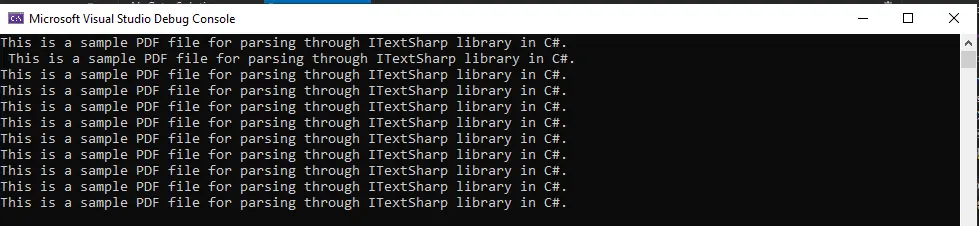
El resultado muestra que todo el archivo PDF se convierte en texto y se muestra en la pantalla.
Esta biblioteca proporciona métodos para dividir el documento según los números de página. Además, las funcionalidades para crear archivos PDF también están disponibles en esta biblioteca.