Erstellen Sie eine lineare Regression in Seaborn
Dieser Artikel zielt darauf ab, etwas über die lineare Regression im Detail zu lernen und zu sehen, wie wir eine lineare Regression mit Hilfe der regplot()-Methode in Seaborn erstellen können.
Erstellen Sie eine lineare Regression mit der regplot()-Methode in Seaborn
Der ganze Zweck der Funktion regplot() besteht darin, ein lineares Regressionsmodell für Ihre Daten zu erstellen und zu visualisieren. Das regplot() steht für Regression Plot.
Lassen Sie uns direkt in den Code eintauchen, um zu sehen, wie man mit Seaborn ein Regressionsdiagramm erstellt. Jetzt werden wir die Seaborn-Bibliothek und das Pyplot-Modul importieren, und wir werden auch einige Daten aus der Seaborn-Bibliothek importieren.
Bei diesen Daten dreht sich alles um Diamanten. Jede Zeile in diesem Datenrahmen handelt also von einem bestimmten Diamanten und seinen verschiedenen Eigenschaften.
import matplotlib.pyplot as plot
import seaborn as sb
DATA = sb.load_dataset("diamonds").dropna()
DATA.head()
Ausgang:

Jetzt werden wir 190 Zufallsstichproben aus diesem Datensatz sammeln, weil wir jeden Diamanten als Punkt darstellen werden.
DATA = DATA.sample(n=190, random_state=38)
Jetzt können wir mit dem Regressionsdiagramm beginnen. Um ein Seaborn-Regressionsdiagramm zu erstellen, müssen wir die Referenz durch die Methode regplot() verwenden.
Hier übergeben wir bei dieser Methode zwei Reihen, Karat und Preis.
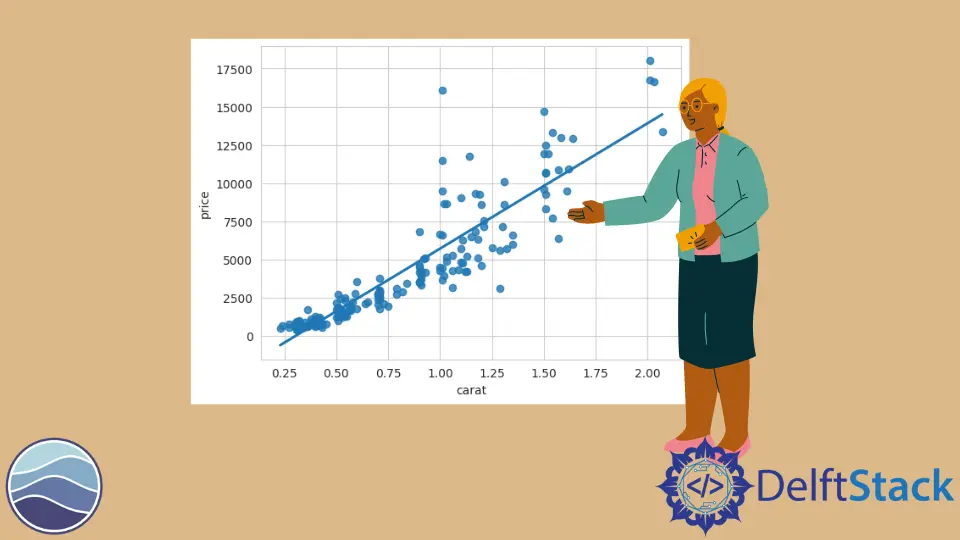
sb.regplot(DATA.carat, DATA.price)
Hier ist der vollständige Quellcode des oben bereitgestellten Beispiels.
import matplotlib.pyplot as plot
import seaborn as sb
DATA = sb.load_dataset("diamonds").dropna()
DATA.head()
DATA = DATA.sample(n=190, random_state=38)
sb.set_style("whitegrid")
sb.regplot(DATA.carat, DATA.price)
plot.show()
Jetzt können wir sehen, was Seaborn für uns getan hat. Die erste Reihe ist entlang der x-Achse aufgetragen und die zweite Reihe entlang der y-Achse.
Wir haben ein lineares Modell, das für diese Daten geeignet ist. Diese Linie verläuft durch alle unsere Scatter-Punkte.
Ausgang:

Jetzt wissen wir also, wie ein lineares Modell aussehen könnte.
Eine andere Sache an seiner Syntax ist, dass eine andere Möglichkeit, ein Seaborn-regplot() zu erstellen, darin besteht, den vollständigen Datenrahmen mit dem data-Argument zu referenzieren.
sb.regplot(x="carat", y="price", data=DATA)
Wir geben Referenzen als Spaltennamen für die Argumente x und y an. Das wird die gleiche Handlung produzieren.
Ausgang:

Wie wir sehen können, gibt es in diesem Diagramm zwei Komponenten: den Streuanteil und die lineare Regressionslinie. Wir können fit_reg=False übergeben, wenn wir kein Regressionsmodell an diese Daten anpassen wollen.
import matplotlib.pyplot as plot
import seaborn as sb
DATA = sb.load_dataset("diamonds").dropna()
DATA.head()
DATA = DATA.sample(n=190, random_state=38)
sb.set_style("whitegrid")
sb.regplot(x="carat", y="price", data=DATA, fit_reg=False)
plot.show()
Ausgang:

Wenn Sie es vorziehen, ein Diagramm nur mit einer Regressionslinie zu haben, besteht die andere Möglichkeit darin, nur die Linie aus der linearen Regression zu zeichnen. Wir müssen die Scatter-Punkte mit dem Argument scatter ausschalten, das gleich False sein sollte.
import matplotlib.pyplot as plot
import seaborn as sb
DATA = sb.load_dataset("diamonds").dropna()
DATA.head()
DATA = DATA.sample(n=190, random_state=38)
sb.set_style("whitegrid")
sb.regplot(x="carat", y="price", data=DATA, scatter=False)
plot.show()
Ausgang:

Sie sehen den gebänderten Bereich mit dem schattierten Bereich um Ihre Linie, wenn Sie das normale Regressionsdiagramm zeichnen. Diese werden Konfidenzintervalle genannt.
Wenn Sie das ausschalten möchten, können Sie das Argument ci verwenden und es gleich None setzen.
import matplotlib.pyplot as plot
import seaborn as sb
DATA = sb.load_dataset("diamonds").dropna()
DATA.head()
DATA = DATA.sample(n=190, random_state=38)
sb.set_style("whitegrid")
sb.regplot(x="carat", y="price", data=DATA, ci=None)
plot.show()
Ausgang:

Es schaltet diese Konfidenzintervalle vollständig aus und gibt Ihnen nur eine Linie statt dieses schattierten Bandes.
Wir möchten Ihnen auch zeigen, was passiert, wenn Sie eine diskrete Variable haben, die Sie für eine dieser Achsen verwenden möchten. Wir werden also einige der Informationen in Zahlenwerte umwandeln.
CUT_MAP = {"Fair": 1, "Good": 2, "Very Good": 3, "Premium": 4, "Ideal": 5}
Wir haben den Schliff jedes Diamanten, und wir ordnen diesen einfach dem schlimmsten Schliff zu und setzen die Kategorie in aufsteigender Reihenfolge.
DATA["CUT_VALUE"] = DATA.cut.map(CUT_MAP).cat.as_ordered()
Wir haben eine Spalte CUT_VALUE erstellt, und wenn Sie sie drucken, werden Sie sehen, dass wir Werte von 1 bis 5 haben.
import matplotlib.pyplot as plot
import seaborn as sb
DATA = sb.load_dataset("diamonds").dropna()
DATA.head()
DATA = DATA.sample(n=190, random_state=38)
sb.set_style("whitegrid")
CUT_MAP = {"Fair": 1, "Good": 2, "Very Good": 3, "Premium": 4, "Ideal": 5}
DATA["CUT_VALUE"] = DATA.cut.map(CUT_MAP).cat.as_ordered()
sb.regplot(x="CUT_VALUE", y="price", data=DATA)
plot.show()
Ausgang:

Wenn wir versuchen, diese Spalte CUT_VALUE als unseren x-Wert zu verwenden, sehen wir viele übereinander gestapelte Scatter-Punkte. Es kann wirklich schwierig sein, sie unter dieser linearen Regression zu sehen.
Wir können also etwas Jitter hinzufügen, was die Eigenschaft x_jitter steuert. Es nimmt jeden meiner Scatter-Punkte und bewegt sie nach links oder rechts.
import numpy as np
import matplotlib.pyplot as plot
import seaborn as sb
DATA = sb.load_dataset("diamonds").dropna()
DATA.head()
DATA = DATA.sample(n=190, random_state=38)
sb.set_style("whitegrid")
CUT_MAP = {"Fair": 1, "Good": 2, "Very Good": 3, "Premium": 4, "Ideal": 5}
DATA["CUT_VALUE"] = DATA.cut.map(CUT_MAP).cat.as_ordered().astype(np.int8)
sb.regplot(x="CUT_VALUE", y="price", data=DATA, x_jitter=0.1)
plot.show()
Ausgang:

Auf diese Weise können wir sehen, wo Klumpen von Streupunkten zusammengeballt sind.
Das andere, was wir tun könnten, ist, wenn wir eine diskrete Variable haben. Wir können einen Schätzer für diese Punkte verwenden, indem wir das Argument x_estimator verwenden, anstatt jeden einzelnen Streupunkt zu zeichnen.
import numpy as np
import matplotlib.pyplot as plot
import seaborn as sb
DATA = sb.load_dataset("diamonds").dropna()
DATA.head()
DATA = DATA.sample(n=190, random_state=38)
sb.set_style("whitegrid")
CUT_MAP = {"Fair": 1, "Good": 2, "Very Good": 3, "Premium": 4, "Ideal": 5}
DATA["CUT_VALUE"] = DATA.cut.map(CUT_MAP).cat.as_ordered().astype(np.int8)
sb.regplot(x="CUT_VALUE", y="price", data=DATA, x_estimator=np.mean)
plot.show()
Wir haben diese diskreten Punkte gruppiert und den Mittelwert und einige Konfidenzintervalle für diese Werte berechnet. Jetzt ist es einfach zu lesen, obwohl wir viele Punkte übereinander gestapelt haben.
Ausgang:


Hello! I am Salman Bin Mehmood(Baum), a software developer and I help organizations, address complex problems. My expertise lies within back-end, data science and machine learning. I am a lifelong learner, currently working on metaverse, and enrolled in a course building an AI application with python. I love solving problems and developing bug-free software for people. I write content related to python and hot Technologies.
LinkedIn