Zufälliger Wald in R
Beim Random-Forest-Ansatz werden eine Vielzahl von Entscheidungsbäumen erstellt. Dieses Tutorial zeigt, wie Sie den Random-Forest-Ansatz in R anwenden.
Zufälliger Wald in R
Beim Random-Forest-Ansatz werden eine Vielzahl von Entscheidungsbäumen erstellt. Viele Beobachtungen werden in die Entscheidungsbäume eingespeist, und die häufigste Ausgabe davon wird als endgültige Ausgabe verwendet.
Dann wird eine neue Beobachtung an alle Entscheidungsbäume gesendet, um für jedes Klassifikationsmodell eine Mehrheitsentscheidung zu treffen. Für die Fälle, die während des Aufbaus des Baums nicht verwendet wurden, wird eine OOB-(out-of-bag)-Fehlerschätzung vorgenommen.
Verwenden wir den iris-Datensatz und wenden den Random-Forest-Ansatz darauf an. Wir müssen caTools und randomForest installieren, um den Random Forest in R zu implementieren.
install.packages("caTools")
install.packages("randomForest")
Sobald die Pakete installiert sind, können wir sie laden und den Random-Forest-Ansatz starten. Siehe Beispiel:
# Loading package
library(caTools)
library(randomForest)
# Split the data in train data and test data with ratio 0.8
split_data <- sample.split(iris, SplitRatio = 0.8)
split_data
train_data <- subset(iris, split == "TRUE")
test_data <- subset(iris, split == "FALSE")
# Fit the random Forest to the train dataset
set.seed(120) # Setting seed
classifier_Random_Forest = randomForest(x = train_data[-4],
y = train_data$Species,
ntree = 400)
classifier_Random_Forest
Der obige Code teilt die iris-Daten mit dem Verhältnis 0,8 und erstellt dann die Zug- und Testdaten; schließlich wendet es den Random-Forest-Ansatz mit 400 Bäumen an. Die Ausgabe ist:
Call:
randomForest(x = train_data[-4], y = train_data$Species, ntree = 400)
Type of random forest: classification
Number of trees: 400
No. of variables tried at each split: 2
OOB estimate of error rate: 0%
Confusion matrix:
setosa versicolor virginica class.error
setosa 30 0 0 0
versicolor 0 30 0 0
virginica 0 0 30 0
Sobald das Random-Forest-Modell angepasst ist, können wir das Ergebnis der Testreihe vorhersagen, die Konfusionsmatrix sehen und die Modelldiagramme zeichnen. Siehe Code unten.
# Predict the Test set result
y_pred = predict(classifier_RF, newdata = test_data[-4])
# The Confusion Matrix
conf_matrix = table(test_data[, 4], y_pred)
conf_matrix
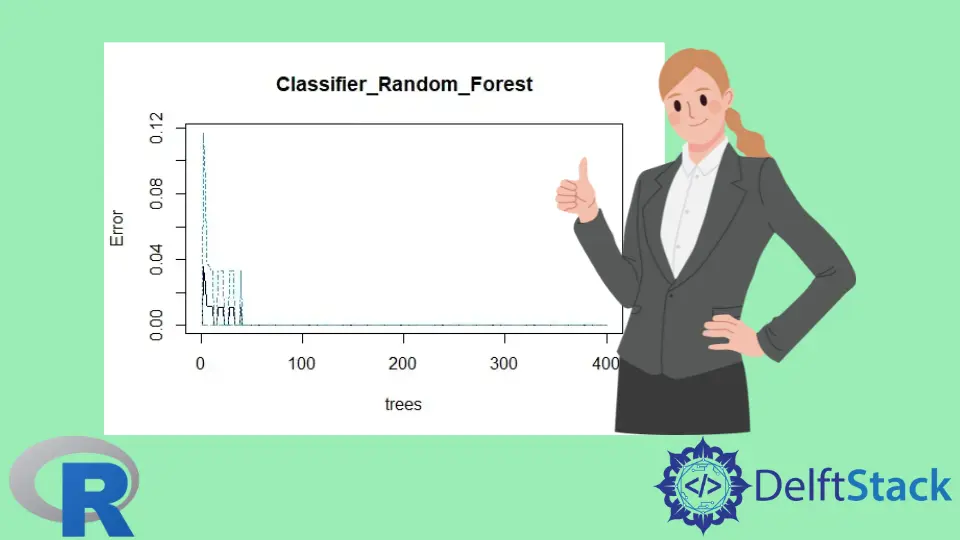
# Plot the random forest model
plot(classifier_Random_Forest)
# The importance plot
importance(classifier_Random_Forest)
# The Variable importance plot
varImpPlot(classifier_Random_Forest)
Der obige Code sagt das Ergebnis des Testsatzes voraus und zeigt dann die Konfusionsmatrix. Schließlich zeigt es den Random-Forest-Model-Plot, den Plot Wichtigkeit und den Plot Variable Wichtigkeit.
Siehe Ausgabe:
> conf_matrix
y_pred
setosa versicolor virginica
0.1 1 0 0
0.2 10 0 0
0.3 3 0 0
0.4 4 0 0
0.5 1 0 0
0.6 1 0 0
1 0 2 0
1.1 0 1 0
1.2 0 1 0
1.3 0 5 0
1.4 0 3 0
1.5 0 6 1
1.6 0 1 1
1.7 0 1 0
1.8 0 2 4
1.9 0 0 3
2 0 0 3
2.1 0 0 1
2.3 0 0 4
2.4 0 0 1
Der Plot des Random Forest-Modells:

Die Bedeutung des Random-Forest-Modells:
MeanDecreaseGini
Sepal.Length 6.1736467
Sepal.Width 0.9664428
Petal.Length 24.1454822
Species 28.0489838
Der Plot Variable Wichtigkeit:


Sheeraz is a Doctorate fellow in Computer Science at Northwestern Polytechnical University, Xian, China. He has 7 years of Software Development experience in AI, Web, Database, and Desktop technologies. He writes tutorials in Java, PHP, Python, GoLang, R, etc., to help beginners learn the field of Computer Science.
LinkedIn Facebook