Implementieren des Gradientenabstiegs mit NumPy und Python
Maschinelles Lernen ist heutzutage ein Trend. Jedes Unternehmen oder Startup versucht, Lösungen zu entwickeln, die maschinelles Lernen verwenden, um reale Probleme zu lösen. Um diese Probleme zu lösen, erstellen Programmierer Modelle für maschinelles Lernen, die anhand einiger wichtiger und wertvoller Daten trainiert wurden. Beim Trainieren von Modellen stehen viele Taktiken, Algorithmen und Methoden zur Auswahl. Einige könnten funktionieren, andere nicht.
Im Allgemeinen wird Python verwendet, um diese Modelle zu trainieren. Python unterstützt zahlreiche Bibliotheken, die die Implementierung von Konzepten des maschinellen Lernens erleichtern. Ein solches Konzept ist der Gradientenabstieg. In diesem Artikel erfahren Sie, wie Sie den Gradientenabstieg mit Python implementieren.
Gradientenabstieg
Gradient Descent ist ein konvexer funktionsbasierter Optimierungsalgorithmus, der beim Trainieren des Modells für maschinelles Lernen verwendet wird. Dieser Algorithmus hilft uns, die besten Modellparameter zu finden, um das Problem effizienter zu lösen. Beim Trainieren eines maschinellen Lernmodells über einige Daten optimiert dieser Algorithmus die Modellparameter für jede Iteration, was schließlich ein globales Minima, manchmal sogar ein lokales Minima, für die differenzierbare Funktion ergibt.
Beim Optimieren der Modellparameter bestimmt ein als Lernrate bekannter Wert den Betrag, um den die Werte optimiert werden sollen. Wenn dieser Wert zu groß ist, erfolgt das Lernen schnell, und wir können das Modell möglicherweise nicht ausreichend anpassen. Und wenn dieser Wert zu klein ist, wird das Lernen langsam sein, und wir könnten das Modell am Ende überanpassen an die Trainingsdaten. Daher müssen wir einen Wert finden, der die Balance hält und schließlich ein gutes Modell für maschinelles Lernen mit guter Genauigkeit liefert.
Implementierung von Gradient Descent mit Python
Nachdem wir nun mit der kurzen Theorie des Gradientenabstiegs fertig sind, wollen wir anhand eines Beispiels verstehen, wie wir sie mit Hilfe des NumPy-Moduls und der Programmiersprache Python implementieren können.
Wir trainieren ein maschinelles Lernmodell für die Gleichung y = 0.5x + 2, die die Form y = mx + c oder y = ax + b hat. Im Wesentlichen wird ein Modell für maschinelles Lernen anhand der mit dieser Gleichung generierten Daten trainiert. Das Modell errät die Werte von m und c oder a und b, d. h. die Steigung bzw. den Achsenabschnitt. Da Modelle für maschinelles Lernen einige Daten zum Lernen und einige Testdaten benötigen, um ihre Genauigkeit zu testen, werden wir dieselben mithilfe eines Python-Skripts generieren. Wir werden eine lineare Regression durchführen, um diese Aufgabe zu erfüllen.
Die Trainingseingaben und Testeingaben werden in der folgenden Form vorliegen; ein zweidimensionales NumPy-Array. In diesem Beispiel ist die Eingabe ein einzelner ganzzahliger Wert und die Ausgabe ist ein einzelner ganzzahliger Wert. Da eine einzelne Eingabe ein Array von Integer- und Float-Werten sein kann, wird das folgende Format verwendet, um die Wiederverwendbarkeit von Code oder dynamischer Natur zu fördern.
[[1], [2], [3], [4], [5], [6], [7], ...]
Und die Trainingslabels und Testlabels werden in der folgenden Form vorliegen; ein eindimensionales NumPy-Array.
[1, 4, 9, 16, 25, 36, 49, ...]
Python-Code
Es folgt die Implementierung des obigen Beispiels.
import random
import numpy as np
import matplotlib.pyplot as plt
def linear_regression(inputs, targets, epochs, learning_rate):
"""
A utility function to run linear regression and get weights and bias
"""
costs = [] # A list to store losses at each epoch
values_count = inputs.shape[1] # Number of values within a single input
size = inputs.shape[0] # Total number of inputs
weights = np.zeros((values_count, 1)) # Weights
bias = 0 # Bias
for epoch in range(epochs):
# Calculating the predicted values
predicted = np.dot(inputs, weights) + bias
loss = predicted - targets # Calculating the individual loss for all the inputs
d_weights = np.dot(inputs.T, loss) / (2 * size) # Calculating gradient
d_bias = np.sum(loss) / (2 * size) # Calculating gradient
weights = weights - (learning_rate * d_weights) # Updating the weights
bias = bias - (learning_rate * d_bias) # Updating the bias
cost = np.sqrt(
np.sum(loss ** 2) / (2 * size)
) # Root Mean Squared Error Loss or RMSE Loss
costs.append(cost) # Storing the cost
print(
f"Iteration: {epoch + 1} | Cost/Loss: {cost} | Weight: {weights} | Bias: {bias}"
)
return weights, bias, costs
def plot_test(inputs, targets, weights, bias):
"""
A utility function to test the weights
"""
predicted = np.dot(inputs, weights) + bias
predicted = predicted.astype(int)
plt.plot(
predicted,
[i for i in range(len(predicted))],
color=np.random.random(3),
label="Predictions",
linestyle="None",
marker="x",
)
plt.plot(
targets,
[i for i in range(len(targets))],
color=np.random.random(3),
label="Targets",
linestyle="None",
marker="o",
)
plt.xlabel("Indexes")
plt.ylabel("Values")
plt.title("Predictions VS Targets")
plt.legend()
plt.show()
def rmse(inputs, targets, weights, bias):
"""
A utility function to calculate RMSE or Root Mean Squared Error
"""
predicted = np.dot(inputs, weights) + bias
mse = np.sum((predicted - targets) ** 2) / (2 * inputs.shape[0])
return np.sqrt(mse)
def generate_data(m, n, a, b):
"""
A function to generate training data, training labels, testing data, and testing inputs
"""
x, y, tx, ty = [], [], [], []
for i in range(1, m + 1):
x.append([float(i)])
y.append([float(i) * a + b])
for i in range(n):
tx.append([float(random.randint(1000, 100000))])
ty.append([tx[-1][0] * a + b])
return np.array(x), np.array(y), np.array(tx), np.array(ty)
learning_rate = 0.0001 # Learning rate
epochs = 200000 # Number of epochs
a = 0.5 # y = ax + b
b = 2.0 # y = ax + b
inputs, targets, train_inputs, train_targets = generate_data(300, 50, a, b)
weights, bias, costs = linear_regression(
inputs, targets, epochs, learning_rate
) # Linear Regression
indexes = [i for i in range(1, epochs + 1)]
plot_test(train_inputs, train_targets, weights, bias) # Testing
print(f"Weights: {[x[0] for x in weights]}")
print(f"Bias: {bias}")
print(
f"RMSE on training data: {rmse(inputs, targets, weights, bias)}"
) # RMSE on training data
print(
f"RMSE on testing data: {rmse(train_inputs, train_targets, weights, bias)}"
) # RMSE on testing data
plt.plot(indexes, costs)
plt.xlabel("Epochs")
plt.ylabel("Overall Cost/Loss")
plt.title(f"Calculated loss over {epochs} epochs")
plt.show()
eine kurze Erklärung des Python-Codes
Der Code hat die folgenden Methoden implementiert.
linear_regression(inputs, target, epochs, learning_rate): Diese Funktion führt die lineare Regression über die Daten durch und gibt Modellgewichte, Modellverzerrung und Zwischenkosten oder -verluste für jede Epoche zurückplot_test(inputs, targets, weights, bias): Diese Funktion akzeptiert Eingaben, Targets, Gewichte und Bias und sagt die Ausgabe für die Eingaben voraus. Dann wird ein Diagramm erstellt, um zu zeigen, wie nahe die Modellvorhersagen von den tatsächlichen Werten waren.rmse(inputs, targets, weights, bias): Diese Funktion berechnet und gibt den quadratischen Mittelwert des Fehlers für einige Eingaben, Gewichte, Bias und Ziele oder Labels zurück.generate_data(m, n, a, b): Diese Funktion generiert Beispieldaten für das zu trainierende Machine-Learning-Modell unter Verwendung der Gleichungy = ax + b. Es generiert die Trainings- und Testdaten.mundnbeziehen sich auf die Anzahl der generierten Trainings- bzw. Testproben.
Es folgt der Ausführungsablauf des obigen Codes.
-
Die Methode
generate_data()wird aufgerufen, um einige Beispiel-Trainingseingaben, Trainingslabels, Testeingaben und Testlabels zu generieren. -
Einige Konstanten wie die Lernrate und die Anzahl der Epochen werden initialisiert.
-
Die Methode
linear_regression()wird aufgerufen, um eine lineare Regression über die generierten Trainingsdaten durchzuführen, und Gewichtungen, Verzerrungen und Kosten, die in jeder Epoche gefunden wurden, werden gespeichert. -
Die Gewichtungen und Verzerrungen des Modells werden mit den generierten Testdaten getestet und ein Diagramm erstellt, das zeigt, wie nahe die Vorhersagen an den wahren Werten liegen.
-
RMSE-Verlust für Trainings- und Testdaten wird berechnet und ausgedruckt.
-
Die gefundenen Kosten für jede Epoche werden mit dem Modul
Matplotlib(eine Graph-Plotting-Bibliothek für Python) geplottet.
Ausgabe
Der Python-Code gibt den Modelltrainingsstatus für jede Epoche oder Iteration an die Konsole aus. Es wird wie folgt sein.
...
Iteration: 199987 | Cost/Loss: 0.05856315870190882 | Weight: [[0.5008289]] | Bias: 1.8339454694938624
Iteration: 199988 | Cost/Loss: 0.05856243033468181 | Weight: [[0.50082889]] | Bias: 1.8339475347628937
Iteration: 199989 | Cost/Loss: 0.05856170197651294 | Weight: [[0.50082888]] | Bias: 1.8339496000062387
Iteration: 199990 | Cost/Loss: 0.058560973627402625 | Weight: [[0.50082887]] | Bias: 1.8339516652238976
Iteration: 199991 | Cost/Loss: 0.05856024528735169 | Weight: [[0.50082886]] | Bias: 1.8339537304158708
Iteration: 199992 | Cost/Loss: 0.05855951695635694 | Weight: [[0.50082885]] | Bias: 1.8339557955821586
Iteration: 199993 | Cost/Loss: 0.05855878863442534 | Weight: [[0.50082884]] | Bias: 1.8339578607227613
Iteration: 199994 | Cost/Loss: 0.05855806032154768 | Weight: [[0.50082883]] | Bias: 1.8339599258376793
...
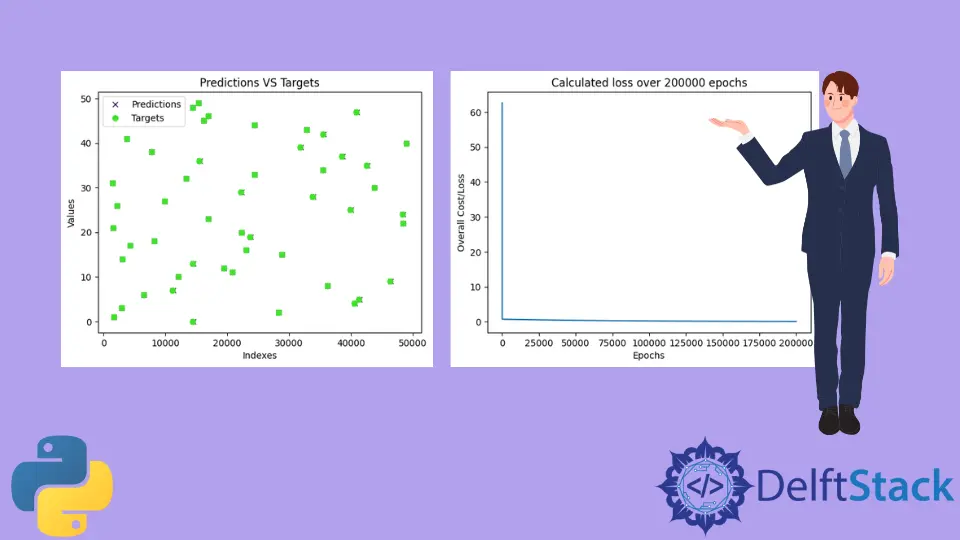
Sobald das Modell trainiert ist, testet das Programm das Modell und zeichnet ein Diagramm mit den Modellvorhersagen und den wahren Werten. Der trainierte Plot ähnelt dem unten gezeigten. Beachten Sie, dass, da Testdaten mit dem Modul random generiert werden, zufällige Werte im Handumdrehen generiert werden, und daher wird sich das unten gezeigte Diagramm höchstwahrscheinlich von Ihrem unterscheiden.

Wie wir sehen, überlappen die Vorhersagen fast alle wahren Werte (Vorhersagen werden durch x und Ziele werden durch o dargestellt). Das bedeutet, dass das Modell die Werte für a und b bzw. m und c fast erfolgreich vorhergesagt hat.
Als nächstes druckt das Programm alle Verluste, die beim Trainieren des Modells gefunden wurden.

Wie wir sehen, sank der Verlust sofort von rund 60 auf 0 und blieb für den Rest der Epochen bei diesem.
Zuletzt wurden die RMSE-Verluste für Trainings- und Testdaten gedruckt und die vorhergesagten Werte für a und b oder die Modellparameter.
Weights: [0.5008287639956263]
Bias: 1.8339723159878247
RMSE on training data: 0.05855296238504223
RMSE on testing data: 30.609530314187527
Die Gleichung, die wir für dieses Beispiel verwendet haben, war y = 0.5x + 2, wobei a = 0.5 und b = 2 sind. Und das Modell sagte a = 0.50082 und b = 1.83397 voraus, die den wahren Werten sehr nahe kommen. Deshalb überschnitten sich unsere Vorhersagen mit den wahren Zielen.
Für dieses Beispiel setzen wir die Anzahl der Epochen auf 200000 und die Lernrate auf 0.0001. Glücklicherweise ist dies nur ein Satz von Konfigurationen, der uns extrem gute, fast perfekte Ergebnisse lieferte. Ich würde den Lesern dieses Artikels wärmstens empfehlen, mit diesen Werten herumzuspielen und zu sehen, ob sie einige Wertesätze finden können, die noch bessere Ergebnisse liefern.

Vaibhav is an artificial intelligence and cloud computing stan. He likes to build end-to-end full-stack web and mobile applications. Besides computer science and technology, he loves playing cricket and badminton, going on bike rides, and doodling.