Pandas DataFrame innerhalb der Gruppe einordnen
In diesem Artikel wird erläutert, wie Daten in aufsteigender und absteigender Reihenfolge sortiert werden. Wir werden auch lernen, wie man eine Gruppe von Daten mit Hilfe der groupby()-Funktion in Pandas einordnet.
Verwenden Sie die Funktion rank(), um Pandas DataFrame in Python einzustufen
Das Ranking ist ein gängiges Verfahren, wenn wir Daten manipulieren oder versuchen herauszufinden, ob beispielsweise der Gewinn basierend auf einem Ranking hoch oder niedrig ist. Manchmal ist das Zeitmanagement sogar daran interessiert zu wissen, was die Top-10-Produkte oder die Bottom-10-Produkte sind.
In Pandas ist die Datenrangfolge eine Operation, bei der wir möchten, dass die Elemente der Reihe nach ihren Werten geordnet oder sortiert werden. Die rank-Operation ist von der SQL ROW_NUMBER inspiriert, oder die meisten Ergebnisse, die wir von der ROW_NUMBER-Operation erwarten können, können von der rank-Operation in Pandas erwartet werden.
Beginnen wir damit, einen Code zu schreiben, um uns ein Beispiel anzusehen.
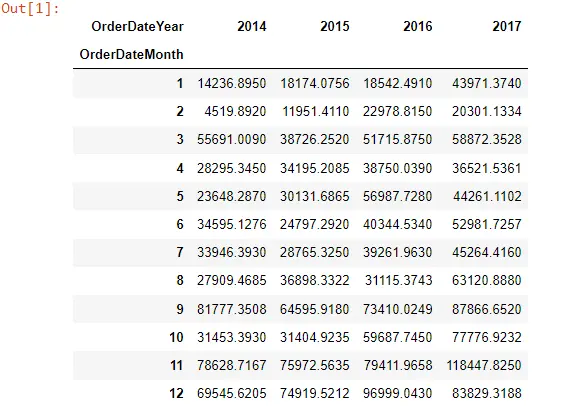
Wir haben einen Datensatz eines Supermarkts geladen und den Monat und das Jahr aus den Daten extrahiert. Und wir haben die Pivot-Tabelle für den Verkaufswert über Monat und Jahr erstellt.
import numpy as np
import pandas as pd
import datetime
Store_Data = pd.read_excel("demo_Data.xls")
Store_Data["OrderDateMonth"] = Store_Data["Order Date"].apply(lambda x: x.month)
Store_Data["OrderDateYear"] = Store_Data["Order Date"].apply(lambda x: x.year)
Mon_Year_Sales = pd.pivot_table(
Store_Data,
index=["OrderDateMonth"],
columns=["OrderDateYear"],
aggfunc="sum",
values="Sales",
)
Mon_Year_Sales
Wenn wir also in unsere Pivot-Tabelle schauen, sieht sie so aus:
Ordnen Sie den DataFrame in aufsteigender und absteigender Reihenfolge
Nun müssen wir diese Daten basierend auf den Werten ordnen. Die Pandas-Bibliothek hat eine rank()-Funktion, die optional den Parameter ascending akzeptiert und die Daten standardmäßig in aufsteigender Reihenfolge anordnet.
Die Funktion rank() hat einige Argumente, die wir durch Drücken von shift+tab+tab sehen können. Es zeigt uns alle Argumente und Definitionen.
![]()
Wenn wir fortfahren und das Ranking auf Mon_Year_Sales anwenden und das ausführen, werden alle diese Spalten in numerische Werte umgewandelt, unabhängig von der numerischen Form, und das Ranking in aufsteigender Reihenfolge durchgeführt.
Mon_Year_Sales.rank()
![]()
Der Rang wird anhand der angegebenen Werte berechnet.
In der zweiten Reihe von 2014 sind diese Daten der erste Rang. Es ist in aufsteigender Reihenfolge angeordnet, da wir dem Argument aufsteigend keinen Wert übergeben haben.
Wenn wir das aufsteigende Argument False übergeben, würde es die Reihenfolge in absteigender Reihenfolge der Werte neu ordnen.
Mon_Year_Sales.rank(ascending=False)
Nun hat der 9. Monat den höchsten Umsatzwert im Jahr 2014, weshalb er den ersten Rang einnimmt.
![]()
Verwenden Sie die groupby()-Methode, um Daten basierend auf einer Gruppe in Pandas zu ordnen
Es gibt bestimmte Anforderungen, bei denen wir Daten basierend auf einer Gruppe von Werten einstufen möchten, nicht auf der Grundlage des Gesamtwerts. Angenommen, unsere Daten sehen so aus:
![]()
Angenommen, wir möchten in den Kategorien für den Wert Gewinn statt für das Gesamtranking ranken.
Group_Data = (
Store_Data.groupby(["OrderDateYear", "Category"])
.agg({"Profit": "sum"})
.reset_index()
)
Group_Data
![]()
Für das jeweilige Jahr möchten wir den Gewinn der Kategorien ordnen, also möchten wir für 2014, dass der zweite Wert der erste Rang ist, da dies das Maximum innerhalb von 2014 ist.
In ähnlicher Weise wollen wir für 2015 eine separate Rangliste, z. B. wieder bei 1, 2 und 3 beginnen, anstatt kontinuierlich in der Gesamtwertung fortzufahren. Und dann wollen wir wissen, welche Kategorie den höchsten Rang hat, also wie können wir das erreichen?
Um das Ziel zu erreichen, werden wir nach Jahr gruppieren und dann den Gewinn auswählen, dann das Argument aufsteigend auf False setzen, was bedeutet, dass wir den obersten Rang auf den maximalen Wert setzen wollen. Dann setzen wir das Argument method auf dense.
Group_Data["Rank_groupby"] = Group_Data.groupby("OrderDateYear")["Profit"].rank(
ascending=False, method="dense"
)
Group_Data
Nach der Ausführung können wir nun sehen, dass Bürobedarf den ersten Rang hat, und dann hat die andere Gruppenebene wieder von 1, 2 und 3 für jedes einzelne Jahr begonnen.
![]()
Vollständiger Beispielcode:
# In[1]:
import numpy as np
import pandas as pd
import datetime
Store_Data = pd.read_excel("demo_Data.xls")
Store_Data["OrderDateMonth"] = Store_Data["Order Date"].apply(lambda x: x.month)
Store_Data["OrderDateYear"] = Store_Data["Order Date"].apply(lambda x: x.year)
Mon_Year_Sales = pd.pivot_table(
Store_Data,
index=["OrderDateMonth"],
columns=["OrderDateYear"],
aggfunc="sum",
values="Sales",
)
Mon_Year_Sales
# In[2]:
Mon_Year_Sales.rank()
# In[3]:
Mon_Year_Sales.rank(ascending=False)
# In[4]:
Store_Data.head(2)
# In[5]:
Group_Data = (
Store_Data.groupby(["OrderDateYear", "Category"])
.agg({"Profit": "sum"})
.reset_index()
)
Group_Data
# In[6]:
Group_Data["Rank_groupby"] = Group_Data.groupby("OrderDateYear")["Profit"].rank(
ascending=False, method="dense"
)
Group_Data
Lesen Sie weitere verwandte Antworten von hier.

Hello! I am Salman Bin Mehmood(Baum), a software developer and I help organizations, address complex problems. My expertise lies within back-end, data science and machine learning. I am a lifelong learner, currently working on metaverse, and enrolled in a course building an AI application with python. I love solving problems and developing bug-free software for people. I write content related to python and hot Technologies.
LinkedInVerwandter Artikel - Pandas DataFrame
- Wie man Pandas DataFrame-Spaltenüberschriften als Liste erhält
- Pandas DataFrame-Spalte löschen
- Wie man DataFrame-Spalte in Datetime in Pandas konvertiert
- Wie konvertiert man eine Fließkommazahl in eine Ganzzahl in Pandas DataFrame
- Wie man Pandas-DataFrame nach den Werten einer Spalte sortiert
- Wie erhält man das Aggregat der Pandas gruppenweise und sum