Fügen Sie dem Pandas-Datenrahmen Metadaten hinzu
Metadaten, auch bekannt als Daten über Daten, sind strukturierte Daten, die den Inhalt von Dokumenten beschreiben, lokalisieren und verwalten, die im Web durch Webpublishing geteilt werden.
Einige Webserver und Softwaretools können Metadaten automatisch generieren. Der manuelle Prozess ist jedoch auch machbar.
Es kann die Organisation, Auffindbarkeit, Zugänglichkeit, Indizierung und den Abruf eines Dokuments verbessern.
Der Pandas-Datenrahmen ist eine Datenstruktur, die auf dem Datenrahmen aufbaut und die Funktionalität sowohl von R-Datenrahmen als auch von Python-Wörterbüchern bereitstellt.
Es ist wie ein Python-Wörterbuch, verfügt jedoch über alle Funktionen zur Datenanalyse und -bearbeitung, wie Tabellen in Excel oder Datenbanken mit Zeilen und Spalten. In diesem Tutorial wird das Hinzufügen von Metadaten zu Pandas-Datenrahmen erläutert.
Fügen Sie dem Pandas-Datenrahmen Metadaten hinzu
Um Metadaten zu einem Datenrahmen hinzuzufügen, müssen wir die unten angegebenen Anforderungen erfüllen.
- Erstellen oder importieren Sie einen Datenrahmen.
- Vorhandene Metadaten des Datenrahmens lesen.
- Fügen Sie dem Datenrahmen Metadaten hinzu.
Erstellen oder importieren Sie einen Datenrahmen
Ein Datenrahmen ist erforderlich, um ihm Metadaten hinzuzufügen. Dazu müssen Sie eine Python-Bibliothek namens pandas installieren.
PS C:\> pip install pandas
Lassen Sie uns mit pandas einen Datenrahmen aus einer Datei lesen.
Beispielcode (gespeichert in demo.py):
import pandas as pd
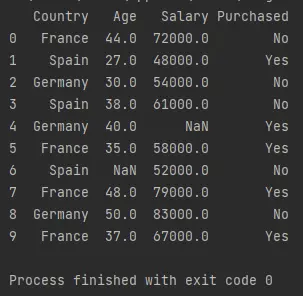
df = pd.read_csv("Data.csv")
print(df)
Der obige Code importiert das Python-Paket pandas als pd. Die Funktion pd.read_csv() importiert einen Datenrahmen, liest ihn und speichert ihn in einer Variablen namens df.
Mal sehen, was pd ist.
Ausgabe (auf Konsole gedruckt):
Vorhandene Metadaten des Datenrahmens lesen
Der importierte Datenrahmen enthält auch einige vorhandene Metadaten. Wir können es anhand der unten angegebenen Codebeispiele anzeigen.
-
Pandas
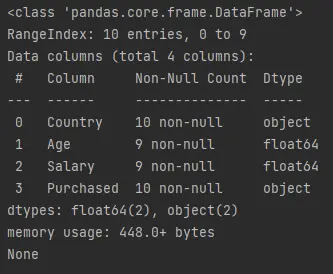
info()-Funktion bietet eine schnelle Zusammenfassung des Datenrahmens. Es ruft Informationen wiemax_cols,memory_usage,show_countsundnull_countsab.Lassen Sie uns den folgenden Code ausführen, der
df.info()aufruft und ausgibt.Beispielcode (gespeichert in
demo.py):print(df.info())Ausgabe (auf Konsole gedruckt):
-
Pandas
columns-Attribut gibt ein unveränderliches n-dimensionales Array geordneter Sätze namensIndexzurück, das Beschriftungen jeder Datenrahmenspalte enthält. Lassen Sie uns den folgenden Code ausführen, derdf.columnsaufruft und einenIndexdruckt.
Beispielcode (gespeichert in `demo.py`):
```python
print(df.columns)
```
Ausgabe (auf Konsole gedruckt):

-
Pandas
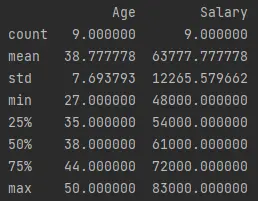
describe()-Funktion generiert beschreibende Statistiken des Datenrahmens. Dazu gehörenAnzahl,Mittelwertund Standardabweichung alsstd,min,maxund Perzentile.Lassen Sie uns den folgenden Code ausführen, der
df.describe()aufruft und ausgibt.Beispielcode (gespeichert in
demo.py):print(df.describe())Ausgabe (auf Konsole gedruckt):
Fügen Sie dem Datenrahmen Metadaten hinzu
Lassen Sie uns den folgenden Code ausführen, um dem Pandas-Datenrahmen Metadaten hinzuzufügen.
Beispielcode (gespeichert in demo.py):
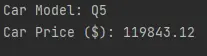
df.audi_car_model = "Q5"
df.audi_car_price_in_dollars = 119843.12
print(f"Car Model: {df.audi_car_model}")
print(f"Car Price ($): {df.audi_car_price_in_dollars}")
Ausgabe (auf Konsole gedruckt):
Hinweis: Python bietet keine leistungsstarke Methode zum Weitergeben von Metadaten an Datenrahmen.
Wenn Sie beispielsweise group_by auf einen Datenrahmen mit angehängten Metadaten anwenden, wird der vorherige Datenrahmen ohne angehängte Metadaten zurückgegeben.
Sie können die Metadaten jedoch für eine spätere Bearbeitung in einer HDF5-Datei speichern. Lassen Sie uns den folgenden Code ausführen, um Metadaten in einer HDF5-Datei zu speichern.
Beispielcode (gespeichert in demo.py):
def store_in_hdf5(filename, df, **kwargs):
hdf5_file = pd.HDFStore(filename)
hdf5_file.put("car_data", df)
hdf5_file.get_storer("car_data").attrs.metadata = kwargs
hdf5_file.close()
filename = "car data.hdf5"
metadata = {"audi_car_model": "Q5", "audi_car_price_in_dollars": 119843.12}
store_in_hdf5(filename, df, **metadata)
Die Funktion store_in_hdf5() führt die folgenden Funktionen aus:
- Erstellen Sie eine
hdf5_filemit der Funktionpd.HDFStore()mit demfilenameals Argument. - Fügen Sie den Datenrahmen mit
hdf5_file.put()in die Datei ein, indem Sie einen geeigneten Namen unddfals Argumente verwenden. - Metadaten in
hdf5_filespeichern. Es verwendethdf5_file.get_storer('car_data').attrs.metadataund weist ihmmetadatazu. - Rufen Sie
hdf5_file.close()auf, um die Datei zu schliessen.
Lassen Sie uns nun den folgenden Code ausführen, um den Datenrahmen und die Metadaten aus einer Datei zu importieren.
Beispielcode (gespeichert in demo.py):
def import_from_file(hdf5_file):
data = hdf5_file["car_data"]
metadata = hdf5_file.get_storer("car_data").attrs.metadata
return data, metadata
filename = "car data.hdf5"
with pd.HDFStore(filename) as hdf5_file:
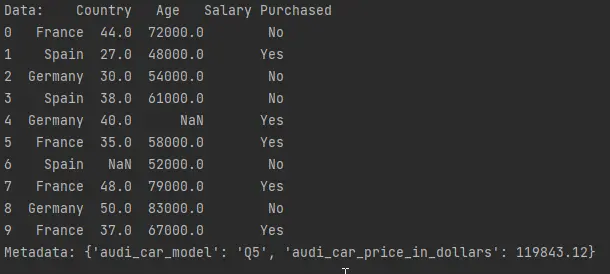
data, metadata = import_from_file(hdf5_file)
print(f"Data: {data}")
print(f"Metadata: {metadata}")
Die Funktion import_from_file() nimmt die hdf5_file als Argument. Es ruft die folgenden Informationen ab:
Datendurch Angabe des Namens der Daten inhdf5_file[].metadatadurch Aufruf desmetadata-Attributs der Funktionhdf5_file.get_storer('car_data').attrs.metadata.
Nun führen wir die Python-Datei demo.py wie folgt aus:
PS C:>python demo.py
Es druckt die Daten und Metadaten, die von der Funktion import_from_file() zurückgegeben werden.
Ausgabe (auf Konsole gedruckt):