Filtern Sie Zeilen, die eine bestimmte Zeichenfolge in Pandas enthalten
- Installieren Sie erforderliche Bibliotheken
- Erstellen Sie einen Pandas-DataFrame
-
Verwenden Sie
str.contains(), um Zeilen zu filtern, die eine bestimmte Zeichenfolge enthalten -
Verwenden Sie
str.contains(), um Zeilen zu filtern, die einen String in einer Liste enthalten
Die Pandas-Bibliothek ist ein vollständiges Werkzeug zum Umgang mit Textdaten zusätzlich zu Zahlen. Sie sollten die Texteingabe aus vielen Datenanalyseanwendungen und der Exploration/Vorverarbeitung des maschinellen Lernens ausschließen.
Dataframes in Python ist eine primäre Datenstruktur, die im Pandas-Modul vorhanden ist. Diese Datenstrukturen werden zum Speichern und Verarbeiten von Daten in Tabellenform verwendet.
Ein solcher Prozess, der für in Tabellenform gespeicherte Daten durchgeführt wird, ist das Filtern des Datenrahmens nach Teilstring-Kriterien, damit relevante Informationen daraus extrahiert werden können. Dieser Artikel führt Sie Schritt für Schritt durch, um denselben Vorgang durchzuführen.
Installieren Sie erforderliche Bibliotheken
Um mit dem Filtern des Pandas-Datenrahmens zu beginnen, müssen wir zuerst die Pandas-Bibliothek installieren. Wir können dies schnell erreichen, indem wir den folgenden Befehl im Terminal Ihrer Wahl ausführen:
pip install pandas
Es ist auch wichtig sicherzustellen, dass wir mit der richtigen Python-Version arbeiten. In diesem Artikel verwenden wir Version 3.10.4.
Wir können die aktuell installierte Python-Version überprüfen, indem wir den folgenden Befehl im Terminal ausführen:
python --version
Erstellen Sie einen Pandas-DataFrame
Um den Datenrahmen-Filtervorgang durchzuführen, benötigen wir einen Beispiel-Datenrahmen; Daher generieren wir mit dem folgenden Code einen Datenrahmen für unseren Artikel. Es zeigt uns die Namen von fünf Schülern, die für zwei Fächer, Biologie und Chemie, von 100 benotet werden.
Beispielcode:
import pandas as pd
data = {
"Student_Name": ["Anil", "Suharwardy", "Fatina", "John", "Karen"],
"Biology": [68, 73, 87, 58, 78],
"Chemistry": [78, 98, 89, 73, 87],
}
data_frame = pd.DataFrame(data)
print(data_frame)
Der obige Code ist also ziemlich einfach. Wir beginnen mit dem Importieren der Pandas-Bibliothek und initialisieren dann die Variable data als Wörterbuch, das die Informationen enthält, die wir in unseren resultierenden Datenrahmen einfügen möchten.
Wir verwenden dann die DataFrame()-Methode im Pandas-Modul, um unseren Datenrahmen zu generieren, indem wir das data-Wörterbuch in die oben genannte Technik übergeben.
Der folgende Datenrahmen wird generiert, wenn wir den Code ausführen.
Ausgang:
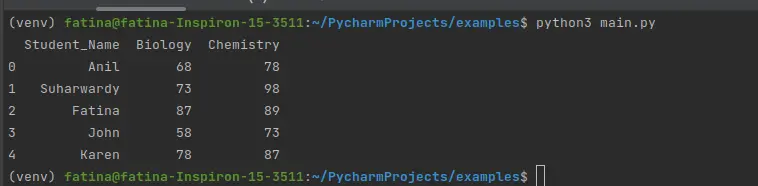
Verwenden Sie str.contains(), um Zeilen zu filtern, die eine bestimmte Zeichenfolge enthalten
Nachdem wir unseren Datenrahmen erstellt haben, können wir mit dem Filterschritt fortfahren. Nehmen wir an, wir wollen die Daten für den Studenten Suharwardy herausfiltern; Das Ergebnis sollten alle Informationen sein, die gegen Suharwardy gespeichert sind.
Wir können diese Operation mit der Methode str.contains() ausführen. Im folgenden Snippet haben wir auf die Dataframe-Spalte Student_Name zugegriffen und mit der Methode str.contains() auf die Informationen zugegriffen, die für den Namen Suharwardy gespeichert sind.
Beispielcode:
import pandas as pd
data = {
"Student_Name": ["Anil", "Suharwardy", "Fatina", "John", "Karen"],
"Biology": [68, 73, 87, 58, 78],
"Chemistry": [78, 98, 89, 73, 87],
}
data_frame = pd.DataFrame(data=data)
df = data_frame[data_frame["Student_Name"].str.contains("Suharwardy")]
print(df)
Ausgang:

Eine noch einfachere und intuitivere Art, diese Operation auszuführen, könnte die Verwendung des Punktoperators sein, um auf die Spalte Student_Name zuzugreifen. Wir erhalten die gleichen Ergebnisse.
Beispielcode:
import pandas as pd
data = {
"Student_Name": ["Anil", "Suharwardy", "Fatina", "John", "Karen"],
"Biology": [68, 73, 87, 58, 78],
"Chemistry": [78, 98, 89, 73, 87],
}
data_frame = pd.DataFrame(data=data)
df = data_frame[data_frame.Student_Name.str.contains("Suharwardy")]
print(df)
Ausgang:

Die Methode str.contains() hat auch den Parameter regex, den Sie verwenden können, um schnellere Ergebnisse zu erhalten, indem Sie ihn auf False setzen.
Beispielcode:
import pandas as pd
import regex as regex
data = {
"Student_Name": ["Anil", "Suharwardy", "Fatina", "John", "Karen"],
"Biology": [68, 73, 87, 58, 78],
"Chemistry": [78, 98, 89, 73, 87],
}
data_frame = pd.DataFrame(data=data)
df = data_frame[data_frame.Student_Name.str.contains("Suharwardy", regex=False)]
print(df)
Ausgang:
So können wir einen Pandas-Datenrahmen mit der Methode str.contains() filtern und die Einzelheiten der Informationen angeben, die wir extrahieren möchten.
Verwenden Sie str.contains(), um Zeilen zu filtern, die einen String in einer Liste enthalten
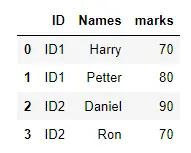
Der folgende Code zeigt, wie nach Datenrahmen-Zeilen gefiltert wird, die ID1 oder ID2 in der ID-Spalte enthalten.
Beispielcode:
import pandas as pd
d1 = {
"ID": [
"ID1",
"ID1",
"ID2",
"ID2",
"ID3",
"ID3",
],
"Names": ["Harry", "Petter", "Daniel", "Ron", "Sofia", "Kelvin"],
"marks": [70, 80, 90, 70, 60, 90],
}
df = pd.DataFrame(d1)
print(df)
s = df[df["ID"].str.contains("ID1|ID2")]
print("use of str.contains() : ")
print(s)
Ausgang:

I am Fariba Laiq from Pakistan. An android app developer, technical content writer, and coding instructor. Writing has always been one of my passions. I love to learn, implement and convey my knowledge to others.
LinkedIn